diff --git a/img/aufrufdiagramm_fib.svg b/img/aufrufdiagramm_fib.svg
new file mode 100644
index 0000000000000000000000000000000000000000..167805caacbcc6dd572ec97ee78e6d933d917eaa
--- /dev/null
+++ b/img/aufrufdiagramm_fib.svg
@@ -0,0 +1,726 @@
+<?xml version="1.0" encoding="UTF-8" standalone="no"?>
+<!-- Created with Inkscape (http://www.inkscape.org/) -->
+
+<svg
+ xmlns:dc="http://purl.org/dc/elements/1.1/"
+ xmlns:cc="http://creativecommons.org/ns#"
+ xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
+ xmlns:svg="http://www.w3.org/2000/svg"
+ xmlns="http://www.w3.org/2000/svg"
+ xmlns:sodipodi="http://sodipodi.sourceforge.net/DTD/sodipodi-0.dtd"
+ xmlns:inkscape="http://www.inkscape.org/namespaces/inkscape"
+ width="297.73431mm"
+ height="201.82164mm"
+ viewBox="0 0 297.73431 201.82164"
+ version="1.1"
+ id="svg8"
+ inkscape:version="0.92.2 5c3e80d, 2017-08-06"
+ sodipodi:docname="fibonacci.svg">
+ <defs
+ id="defs2">
+ <marker
+ inkscape:isstock="true"
+ style="overflow:visible"
+ id="marker5438"
+ refX="0"
+ refY="0"
+ orient="auto"
+ inkscape:stockid="Arrow2Lend">
+ <path
+ transform="matrix(-1.1,0,0,-1.1,-1.1,0)"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ id="path5436"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:isstock="true"
+ style="overflow:visible"
+ id="marker5286"
+ refX="0"
+ refY="0"
+ orient="auto"
+ inkscape:stockid="Arrow2Lend">
+ <path
+ transform="matrix(-1.1,0,0,-1.1,-1.1,0)"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ id="path5284"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:isstock="true"
+ style="overflow:visible"
+ id="marker5142"
+ refX="0"
+ refY="0"
+ orient="auto"
+ inkscape:stockid="Arrow2Lend">
+ <path
+ transform="matrix(-1.1,0,0,-1.1,-1.1,0)"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ id="path5140"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:isstock="true"
+ style="overflow:visible"
+ id="marker5006"
+ refX="0"
+ refY="0"
+ orient="auto"
+ inkscape:stockid="Arrow2Lend">
+ <path
+ transform="matrix(-1.1,0,0,-1.1,-1.1,0)"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ id="path5004"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:isstock="true"
+ style="overflow:visible"
+ id="marker4856"
+ refX="0"
+ refY="0"
+ orient="auto"
+ inkscape:stockid="Arrow2Lend">
+ <path
+ transform="matrix(-1.1,0,0,-1.1,-1.1,0)"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ id="path4854"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:isstock="true"
+ style="overflow:visible"
+ id="marker4306"
+ refX="0"
+ refY="0"
+ orient="auto"
+ inkscape:stockid="Arrow2Lend">
+ <path
+ transform="matrix(-1.1,0,0,-1.1,-1.1,0)"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ id="path4304"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:isstock="true"
+ style="overflow:visible"
+ id="marker4034"
+ refX="0"
+ refY="0"
+ orient="auto"
+ inkscape:stockid="Arrow2Lend">
+ <path
+ transform="matrix(-1.1,0,0,-1.1,-1.1,0)"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ id="path4032"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:stockid="Arrow2Lstart"
+ orient="auto"
+ refY="0"
+ refX="0"
+ id="marker3887"
+ style="overflow:visible"
+ inkscape:isstock="true">
+ <path
+ id="path3885"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ transform="matrix(1.1,0,0,1.1,1.1,0)"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:isstock="true"
+ style="overflow:visible"
+ id="marker3519"
+ refX="0"
+ refY="0"
+ orient="auto"
+ inkscape:stockid="Arrow2Lstart"
+ inkscape:collect="always">
+ <path
+ transform="matrix(1.1,0,0,1.1,1.1,0)"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ id="path3517"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:stockid="Arrow2Lstart"
+ orient="auto"
+ refY="0"
+ refX="0"
+ id="marker3257"
+ style="overflow:visible"
+ inkscape:isstock="true">
+ <path
+ id="path3255"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ transform="matrix(1.1,0,0,1.1,1.1,0)"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:isstock="true"
+ style="overflow:visible"
+ id="marker3141"
+ refX="0"
+ refY="0"
+ orient="auto"
+ inkscape:stockid="Arrow2Lstart"
+ inkscape:collect="always">
+ <path
+ transform="matrix(1.1,0,0,1.1,1.1,0)"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ id="path3139"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:stockid="Arrow2Lstart"
+ orient="auto"
+ refY="0"
+ refX="0"
+ id="marker2905"
+ style="overflow:visible"
+ inkscape:isstock="true"
+ inkscape:collect="always">
+ <path
+ id="path2903"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ transform="matrix(1.1,0,0,1.1,1.1,0)"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:isstock="true"
+ style="overflow:visible"
+ id="marker2477"
+ refX="0"
+ refY="0"
+ orient="auto"
+ inkscape:stockid="Arrow2Lstart"
+ inkscape:collect="always">
+ <path
+ transform="matrix(1.1,0,0,1.1,1.1,0)"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ id="path2475"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:stockid="Arrow2Lend"
+ orient="auto"
+ refY="0"
+ refX="0"
+ id="marker2189"
+ style="overflow:visible"
+ inkscape:isstock="true"
+ inkscape:collect="always">
+ <path
+ id="path2187"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ transform="matrix(-1.1,0,0,-1.1,-1.1,0)"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:stockid="Arrow2Lend"
+ orient="auto"
+ refY="0"
+ refX="0"
+ id="marker2077"
+ style="overflow:visible"
+ inkscape:isstock="true">
+ <path
+ id="path2075"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ transform="matrix(-1.1,0,0,-1.1,-1.1,0)"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:stockid="Arrow2Lend"
+ orient="auto"
+ refY="0"
+ refX="0"
+ id="marker1935"
+ style="overflow:visible"
+ inkscape:isstock="true"
+ inkscape:collect="always">
+ <path
+ id="path1933"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ transform="matrix(-1.1,0,0,-1.1,-1.1,0)"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:stockid="Arrow1Lend"
+ orient="auto"
+ refY="0"
+ refX="0"
+ id="Arrow1Lend"
+ style="overflow:visible"
+ inkscape:isstock="true">
+ <path
+ id="path850"
+ d="M 0,0 5,-5 -12.5,0 5,5 Z"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:1.00000003pt;stroke-opacity:1"
+ transform="matrix(-0.8,0,0,-0.8,-10,0)"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:isstock="true"
+ style="overflow:visible"
+ id="marker1833"
+ refX="0"
+ refY="0"
+ orient="auto"
+ inkscape:stockid="Arrow2Lstart">
+ <path
+ transform="matrix(1.1,0,0,1.1,1.1,0)"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ id="path1831"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:stockid="Arrow2Lstart"
+ orient="auto"
+ refY="0"
+ refX="0"
+ id="marker1461"
+ style="overflow:visible"
+ inkscape:isstock="true"
+ inkscape:collect="always">
+ <path
+ id="path1459"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ transform="matrix(1.1,0,0,1.1,1.1,0)"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:isstock="true"
+ style="overflow:visible"
+ id="marker1197"
+ refX="0"
+ refY="0"
+ orient="auto"
+ inkscape:stockid="Arrow2Lstart"
+ inkscape:collect="always">
+ <path
+ transform="matrix(1.1,0,0,1.1,1.1,0)"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ id="path1195"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:stockid="Arrow2Lstart"
+ orient="auto"
+ refY="0"
+ refX="0"
+ id="Arrow2Lstart"
+ style="overflow:visible"
+ inkscape:isstock="true"
+ inkscape:collect="always">
+ <path
+ id="path865"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ transform="matrix(1.1,0,0,1.1,1.1,0)"
+ inkscape:connector-curvature="0" />
+ </marker>
+ <marker
+ inkscape:stockid="Arrow2Lend"
+ orient="auto"
+ refY="0"
+ refX="0"
+ id="Arrow2Lend"
+ style="overflow:visible"
+ inkscape:isstock="true">
+ <path
+ id="path868"
+ style="fill:#000000;fill-opacity:1;fill-rule:evenodd;stroke:#000000;stroke-width:0.625;stroke-linejoin:round;stroke-opacity:1"
+ d="M 8.7185878,4.0337352 -2.2072895,0.01601326 8.7185884,-4.0017078 c -1.7454984,2.3720609 -1.7354408,5.6174519 -6e-7,8.035443 z"
+ transform="matrix(-1.1,0,0,-1.1,-1.1,0)"
+ inkscape:connector-curvature="0" />
+ </marker>
+ </defs>
+ <sodipodi:namedview
+ id="base"
+ pagecolor="#ffffff"
+ bordercolor="#666666"
+ borderopacity="1.0"
+ inkscape:pageopacity="0.0"
+ inkscape:pageshadow="2"
+ inkscape:zoom="0.40441389"
+ inkscape:cx="213.88593"
+ inkscape:cy="337.09792"
+ inkscape:document-units="mm"
+ inkscape:current-layer="layer1"
+ showgrid="false"
+ showguides="true"
+ inkscape:guide-bbox="true"
+ inkscape:window-width="1440"
+ inkscape:window-height="855"
+ inkscape:window-x="0"
+ inkscape:window-y="1"
+ inkscape:window-maximized="1"
+ fit-margin-top="0"
+ fit-margin-left="0"
+ fit-margin-right="0"
+ fit-margin-bottom="0" />
+ <metadata
+ id="metadata5">
+ <rdf:RDF>
+ <cc:Work
+ rdf:about="">
+ <dc:format>image/svg+xml</dc:format>
+ <dc:type
+ rdf:resource="http://purl.org/dc/dcmitype/StillImage" />
+ <dc:title></dc:title>
+ </cc:Work>
+ </rdf:RDF>
+ </metadata>
+ <g
+ inkscape:label="Ebene 1"
+ inkscape:groupmode="layer"
+ id="layer1"
+ transform="translate(77.937001,-33.119358)">
+ <path
+ transform="scale(1,-1)"
+ style="fill:#e6e6e6;stroke:#000000;stroke-width:0.65399998;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1"
+ d="m 60.326996,-66.754768 h 52.738314 v 33.30841 H 60.326996 Z"
+ id="rect10"
+ inkscape:connector-curvature="0" />
+ <text
+ xml:space="preserve"
+ style="font-style:normal;font-weight:normal;font-size:10.58333302px;line-height:1.25;font-family:sans-serif;letter-spacing:0px;word-spacing:0px;fill:#000000;fill-opacity:1;stroke:none;stroke-width:0.26458332"
+ x="63.257065"
+ y="47.506409"
+ id="text14"><tspan
+ sodipodi:role="line"
+ id="tspan12"
+ x="63.257065"
+ y="47.506409"
+ style="stroke-width:0.26458332">fibonacci</tspan><tspan
+ sodipodi:role="line"
+ x="63.257065"
+ y="60.735577"
+ style="stroke-width:0.26458332"
+ id="tspan16">n 4</tspan></text>
+ <path
+ style="fill:none;stroke:#000000;stroke-width:0.57200003;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1;marker-start:url(#Arrow2Lstart)"
+ d="M 97.851679,57.475155 H 74.607766"
+ id="path845"
+ inkscape:connector-curvature="0" />
+ <g
+ id="g2014"
+ transform="translate(-50.094519,-17.664453)">
+ <rect
+ style="fill:#e6e6e6;stroke:#000000;stroke-width:0.65399998;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1"
+ id="rect1179"
+ width="52.738316"
+ height="33.308411"
+ x="42.296612"
+ y="-140.31084"
+ transform="scale(1,-1)"
+ ry="0" />
+ <text
+ xml:space="preserve"
+ style="font-style:normal;font-weight:normal;font-size:10.58333302px;line-height:1.25;font-family:sans-serif;letter-spacing:0px;word-spacing:0px;fill:#000000;fill-opacity:1;stroke:none;stroke-width:0.26458332"
+ x="45.215004"
+ y="121.06248"
+ id="text1185"><tspan
+ sodipodi:role="line"
+ id="tspan1181"
+ x="45.215004"
+ y="121.06248"
+ style="stroke-width:0.26458332">fibonacci</tspan><tspan
+ id="tspan1439"
+ sodipodi:role="line"
+ x="45.215004"
+ y="134.29164"
+ style="stroke-width:0.26458332">n 3</tspan></text>
+ <path
+ style="fill:none;stroke:#000000;stroke-width:0.57200003;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1;marker-start:url(#marker1197)"
+ d="M 79.809619,131.07509 H 56.565706"
+ id="path1193"
+ inkscape:connector-curvature="0" />
+ </g>
+ <g
+ id="g2063"
+ transform="translate(10.263668,-20.281412)">
+ <rect
+ transform="scale(1,-1)"
+ y="-142.9278"
+ x="118.18833"
+ height="33.308411"
+ width="52.738316"
+ id="rect1443"
+ style="fill:#e6e6e6;stroke:#000000;stroke-width:0.65399998;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1" />
+ <text
+ id="text1449"
+ y="123.02519"
+ x="121.10673"
+ style="font-style:normal;font-weight:normal;font-size:10.58333302px;line-height:1.25;font-family:sans-serif;letter-spacing:0px;word-spacing:0px;fill:#000000;fill-opacity:1;stroke:none;stroke-width:0.26458332"
+ xml:space="preserve"><tspan
+ style="stroke-width:0.26458332"
+ y="123.02519"
+ x="121.10673"
+ id="tspan1445"
+ sodipodi:role="line">fibonacci</tspan><tspan
+ style="stroke-width:0.26458332"
+ y="136.25436"
+ x="121.10673"
+ sodipodi:role="line"
+ id="tspan1447">n 2</tspan></text>
+ <path
+ inkscape:connector-curvature="0"
+ id="path1457"
+ d="M 155.70134,132.71069 H 132.45743"
+ style="fill:none;stroke:#000000;stroke-width:0.57200003;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1;marker-start:url(#marker1461)" />
+ </g>
+ <g
+ id="g3378">
+ <rect
+ style="fill:#e6e6e6;stroke:#000000;stroke-width:0.65399998;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1"
+ id="rect2065"
+ width="52.738316"
+ height="33.308411"
+ x="-42.703972"
+ y="-178.62962"
+ transform="scale(1,-1)" />
+ <text
+ xml:space="preserve"
+ style="font-style:normal;font-weight:normal;font-size:10.58333302px;line-height:1.25;font-family:sans-serif;letter-spacing:0px;word-spacing:0px;fill:#000000;fill-opacity:1;stroke:none;stroke-width:0.26458332"
+ x="-39.78558"
+ y="159.38126"
+ id="text2399"><tspan
+ sodipodi:role="line"
+ id="tspan2395"
+ x="-39.78558"
+ y="159.38126"
+ style="stroke-width:0.26458332">fibonacci</tspan><tspan
+ sodipodi:role="line"
+ x="-39.78558"
+ y="172.61043"
+ style="stroke-width:0.26458332"
+ id="tspan2397">n 2</tspan></text>
+ <path
+ style="fill:none;stroke:#000000;stroke-width:0.57200003;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1;marker-start:url(#marker2477)"
+ d="M -5.1909657,169.60016 H -28.434879"
+ id="path2473"
+ inkscape:connector-curvature="0" />
+ </g>
+ <g
+ id="g3397"
+ transform="translate(-4.0372213e-6)">
+ <rect
+ transform="scale(1,-1)"
+ y="-178.62962"
+ x="27.108162"
+ height="33.308411"
+ width="52.738316"
+ id="rect2887"
+ style="fill:#e6e6e6;stroke:#000000;stroke-width:0.65399998;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1" />
+ <text
+ id="text2893"
+ y="159.38126"
+ x="30.026566"
+ style="font-style:normal;font-weight:normal;font-size:10.58333302px;line-height:1.25;font-family:sans-serif;letter-spacing:0px;word-spacing:0px;fill:#000000;fill-opacity:1;stroke:none;stroke-width:0.26458332"
+ xml:space="preserve"><tspan
+ style="stroke-width:0.26458332"
+ y="159.38126"
+ x="30.026566"
+ id="tspan2889"
+ sodipodi:role="line">fibonacci</tspan><tspan
+ id="tspan2891"
+ style="stroke-width:0.26458332"
+ y="172.61043"
+ x="30.026566"
+ sodipodi:role="line">n 1</tspan></text>
+ <path
+ inkscape:connector-curvature="0"
+ id="path2901"
+ d="M 64.621188,169.60016 H 41.377278"
+ style="fill:none;stroke:#000000;stroke-width:0.57200003;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1;marker-start:url(#marker2905)" />
+ </g>
+ <g
+ id="g3428"
+ transform="translate(-3.4070035)">
+ <rect
+ style="fill:#e6e6e6;stroke:#000000;stroke-width:0.65399998;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1"
+ id="rect3123"
+ width="52.738316"
+ height="33.308411"
+ x="100.327"
+ y="-178.62962"
+ transform="scale(1,-1)" />
+ <text
+ xml:space="preserve"
+ style="font-style:normal;font-weight:normal;font-size:10.58333302px;line-height:1.25;font-family:sans-serif;letter-spacing:0px;word-spacing:0px;fill:#000000;fill-opacity:1;stroke:none;stroke-width:0.26458332"
+ x="103.2454"
+ y="159.38126"
+ id="text3129"><tspan
+ sodipodi:role="line"
+ id="tspan3125"
+ x="103.2454"
+ y="159.38126"
+ style="stroke-width:0.26458332">fibonacci</tspan><tspan
+ sodipodi:role="line"
+ x="103.2454"
+ y="172.61043"
+ style="stroke-width:0.26458332"
+ id="tspan3127">n 1</tspan></text>
+ <path
+ style="fill:none;stroke:#000000;stroke-width:0.57200003;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1;marker-start:url(#marker3141)"
+ d="M 137.84001,169.60016 H 114.5961"
+ id="path3137"
+ inkscape:connector-curvature="0" />
+ </g>
+ <g
+ id="g3447"
+ transform="translate(-3.5949959)">
+ <rect
+ transform="scale(1,-1)"
+ y="-178.62962"
+ x="170.327"
+ height="33.308411"
+ width="52.738316"
+ id="rect3239"
+ style="fill:#e6e6e6;stroke:#000000;stroke-width:0.65399998;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1" />
+ <text
+ id="text3245"
+ y="159.38126"
+ x="173.24539"
+ style="font-style:normal;font-weight:normal;font-size:10.58333302px;line-height:1.25;font-family:sans-serif;letter-spacing:0px;word-spacing:0px;fill:#000000;fill-opacity:1;stroke:none;stroke-width:0.26458332"
+ xml:space="preserve"><tspan
+ style="stroke-width:0.26458332"
+ y="159.38126"
+ x="173.24539"
+ id="tspan3241"
+ sodipodi:role="line">fibonacci</tspan><tspan
+ id="tspan3243"
+ style="stroke-width:0.26458332"
+ y="172.61043"
+ x="173.24539"
+ sodipodi:role="line">n 0</tspan></text>
+ <path
+ inkscape:connector-curvature="0"
+ id="path3253"
+ d="M 207.84,169.60016 H 184.59609"
+ style="fill:none;stroke:#000000;stroke-width:0.57200003;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1;marker-start:url(#marker3257)" />
+ </g>
+ <path
+ style="fill:none;stroke:#000000;stroke-width:0.565;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1;marker-end:url(#marker1935)"
+ d="M 60.326994,66.754768 44.940407,89.337972"
+ id="path3455"
+ inkscape:connector-curvature="0" />
+ <rect
+ transform="scale(1,-1)"
+ y="-234.614"
+ x="-7.7979517"
+ height="33.308411"
+ width="52.738316"
+ id="rect3489"
+ style="fill:#e6e6e6;stroke:#000000;stroke-width:0.65399998;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1" />
+ <text
+ id="text3507"
+ y="215.36565"
+ x="-4.8795586"
+ style="font-style:normal;font-weight:normal;font-size:10.58333302px;line-height:1.25;font-family:sans-serif;letter-spacing:0px;word-spacing:0px;fill:#000000;fill-opacity:1;stroke:none;stroke-width:0.26458332"
+ xml:space="preserve"><tspan
+ style="stroke-width:0.26458332"
+ y="215.36565"
+ x="-4.8795586"
+ id="tspan3503"
+ sodipodi:role="line">fibonacci</tspan><tspan
+ id="tspan3505"
+ style="stroke-width:0.26458332"
+ y="228.59482"
+ x="-4.8795586"
+ sodipodi:role="line">n 0</tspan></text>
+ <path
+ inkscape:connector-curvature="0"
+ id="path3515"
+ d="M 29.715056,225.40506 H 6.4711429"
+ style="fill:none;stroke:#000000;stroke-width:0.57200003;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1;marker-start:url(#marker3519)" />
+ <rect
+ style="fill:#e6e6e6;stroke:#000000;stroke-width:0.65399998;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1"
+ id="rect3863"
+ width="52.738316"
+ height="33.308411"
+ x="-77.610001"
+ y="-234.614"
+ transform="scale(1,-1)" />
+ <text
+ xml:space="preserve"
+ style="font-style:normal;font-weight:normal;font-size:10.58333302px;line-height:1.25;font-family:sans-serif;letter-spacing:0px;word-spacing:0px;fill:#000000;fill-opacity:1;stroke:none;stroke-width:0.26458332"
+ x="-74.691605"
+ y="215.36565"
+ id="text3869"><tspan
+ sodipodi:role="line"
+ id="tspan3865"
+ x="-74.691605"
+ y="215.36565"
+ style="stroke-width:0.26458332">fibonacci</tspan><tspan
+ sodipodi:role="line"
+ x="-74.691605"
+ y="228.59482"
+ style="stroke-width:0.26458332"
+ id="tspan3867">n 1</tspan></text>
+ <path
+ style="fill:none;stroke:#000000;stroke-width:0.57200003;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1;marker-start:url(#marker3887)"
+ d="M -40.096993,225.40506 H -63.340906"
+ id="path3883"
+ inkscape:connector-curvature="0" />
+ <path
+ style="fill:none;stroke:#000000;stroke-width:0.565;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1;marker-end:url(#marker4034)"
+ d="M 113.06531,66.754768 128.452,89.337972"
+ id="path4024"
+ inkscape:connector-curvature="0" />
+ <path
+ style="fill:none;stroke:#000000;stroke-width:0.565;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1;marker-end:url(#marker2077)"
+ d="M -7.7979071,122.64638 -16.335,144.88943"
+ id="path4794"
+ inkscape:connector-curvature="0" />
+ <path
+ style="fill:none;stroke:#000000;stroke-width:0.565;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1;marker-end:url(#marker2189)"
+ d="m 44.940407,122.64638 8.536591,22.24305"
+ id="path4832"
+ inkscape:connector-curvature="0" />
+ <path
+ style="fill:none;stroke:#000000;stroke-width:0.565;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1;marker-end:url(#marker4856)"
+ d="m 128.452,122.64638 -5.163,22.24305"
+ id="path4846"
+ inkscape:connector-curvature="0" />
+ <path
+ style="fill:none;stroke:#000000;stroke-width:0.565;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1;marker-end:url(#marker5142)"
+ d="M 181.19032,122.64638 193.101,144.88943"
+ id="path4996"
+ inkscape:connector-curvature="0" />
+ <path
+ style="fill:none;stroke:#000000;stroke-width:0.565;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1;marker-end:url(#marker5286)"
+ d="m -42.703972,178.62962 -8.536027,22.19725"
+ id="path5276"
+ inkscape:connector-curvature="0" />
+ <path
+ style="fill:none;stroke:#000000;stroke-width:0.565;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:none;stroke-opacity:1;marker-end:url(#marker4306)"
+ d="M 10.034344,178.62962 18.572,200.49975"
+ id="path5608"
+ inkscape:connector-curvature="0" />
+ </g>
+</svg>
diff --git a/notebooks/FAQ.ipynb b/notebooks/FAQ.ipynb
index 53c91c63294b48a14903518915835b0849a74895..536427e50137b3862c524bff733c1a08f9b7eeeb 100644
--- a/notebooks/FAQ.ipynb
+++ b/notebooks/FAQ.ipynb
@@ -4,88 +4,208 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "## Zu den Jupyter-Notebooks\n"
+ "<h1><center> Allgemein </center></h1>"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "- Im Exkurs **\"was mir an python gefällt\"** muss der Code nicht geändert werden. Es reicht, den Code auszuführen mit **\"Strg+Enter\"** und das Ergebnis zu verstehen. Schaut euch den Code an und versucht zu verstehen, was gemacht wird. Einige Anweisungen kennt ihr bereits, andere widerum sind neu. \n",
+ "- Bitte tragt euch in **beide Moodle Kurse** ein. Ankündigungen werden dort veröffentlicht! Wer sich nicht anmeldet und nicht regelmäßig ins Forum schaut, hat Pech gehabt.\n",
+ " - Man kann einstellen, dass man Emails bei neuen Forumbeiträgen bekommt, um keine Neuigkeiten zu verpassen."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "- **Pair-Programming** bitte einhalten: **\"nicht gleichzeitig\"** programmieren, sondern **abwechselnd aktiv** sein. Das ist für alle Beteiligten ein Vorteil!"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "- **Latex**: Tutorium oder Ãœbung. Im Seminar benutzen wir nur Jupyter-Notebooks"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "- **WICHTIG** bei Ankündigungen am Ende der Stunde: Bitte Jupyter Notebooks durcharbeiten oder versuchen. Ich verstehe, dass man nicht immer alle Übungen alleine schafft, aber zumindest die Theorie kann man mit seinem Partner durcharbeiten. \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "- **HILFE** bei Aufgaben: \n",
+ " - Email \n",
+ " - Tutorium\n",
+ " - vorbeikommen (Raum 12)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "- Alternativer Python-Kurs für Interessierte: https://automatetheboringstuff.com/"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Python Tutor\n",
"\n",
- " - Dieser Exkurs soll nur zeigen, zu was python alles fähig ist :)"
+ "Eine gute Hilfe ist die Webseite: http://www.pythontutor.com.\n",
+ "Dort könnt ihr euren Python Code hochladen und Schritt für Schritt durchführen. \n",
+ "Probiert es aus *(Achtung: Sie müssen die Funktion auch dort aufrufen)*. \n",
+ "- Kurze Anleitung:\n",
+ " - Nehmt einen Browser eurer Wahl und ruft http://www.pythontutor.com auf.\n",
+ " - Klickt auf *Visualize your code and get live help now*\n",
+ " - Copy-Paste euren Code in das Textfenster\n",
+ " - Drückt auf Visualize Execution (jetzt solltet ihr auf eine neue Seite gelangt sein)\n",
+ " - Mit den Buttons (First,Back,Forward,Last) könnt ihr jetzt jeden Schritt nachvollziehen, den python macht, wenn ihr den Code im Jupyter-Notebook aufruft. \n",
+ "\n",
+ "\n",
+ "- Der Vorteil ist natürlich, dass ihr nun Schritt für Schritt nachvollziehen könnt, was euer Code macht. \n",
+ " - Es gibt eine print box, wo alles ausgegeben wird, was durch print() auf eurem Display auch ausgegeben werden würde\n",
+ " - Darunter werden Variablen, Funktionen und Methoden angezeigt. \n",
+ "\n",
+ "Besonders hilfreich beim Thema **REKURSION**."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "- Markdownblöcke mit **\"Strg + enter\"** wieder in den Lesemodus bringen"
+ "<h1><center> Zu den Jupyter-Notebooks </center></h1>\n",
+ "\n",
+ "### was mir an python gefällt:\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "- Download: Linksklick auf das Notebook (z.B. seminar03.ipynb) -> Rechtsklick auf Feld \"Open Raw\" -> Ziel speichern unter \n",
- "- Download von Notebooks mit Firefox!\n",
- "- Öffnen von Jupyter-Notebook geht auch mit Internet-Explorer"
+ "- Im Exkurs **\"was mir an python gefällt\"** muss der Code nicht geändert werden. Es reicht, den Code auszuführen mit **\"Strg+Enter\"** und das Ergebnis zu verstehen. Schaut euch den Code an und versucht zu verstehen, was gemacht wird. Einige Anweisungen kennt ihr bereits, andere widerum sind neu. \n",
+ "\n",
+ " - Dieser Exkurs soll zeigen, zu was python alles fähig ist und für was ihr Python in Zukunft benutzen könnt :)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "- Falls ihr einen Codeblock ausführt und ein Stern erscheint: \"In [ * ]\" , bedeutet das, dass der Code gerade ausgeführt wird. Manchmal bleibt das Notebook aber auch einfach hängen, dann benutzt folgende Möglichkeit : Kernel-> restart and clear output. Damit wird das Notebook komplett neu geladen, allerdings müsst ihr die vorherigen Codeblöcke auch neu ausführen."
+ "### Jupyter-Notebooks - Tipps\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "## Allgemein"
+ "- **Markdownblöcke** (das sind normalerweise die Textblöcke) kann man mit **\"Strg + enter\"** wieder in den Lesemodus bringen\n",
+ "- **Codeblöcke** (das sind normalerweise die Blöcke, indem der Pythoncode steht) kann man mit **\"Strg + enter\"** ausführen"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "- Bitte in **beide Moodle Kurse** anmelden. Ankündigungen werden dort veröffentlicht! \n",
- " - Man kann einstellen, dass man Emails bei neuen Forumbeiträgen bekommt."
+ "- **Download**: Linksklick auf das Notebook (z.B. seminar03.ipynb) -> Rechtsklick auf Feld \"Open Raw\" -> Ziel speichern unter \n",
+ "- Download von Notebooks mit Firefox!\n",
+ "- Öffnen von Jupyter-Notebook geht auch mit Internet-Explorer"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "- Latex-Fragen-> Tutorium oder Ãœbung. Im Seminar braucht ihr kein Latex."
+ "- Falls ihr einen Codeblock ausführt und **ein Stern erscheint: \"In [ * ]\" **, bedeutet das, dass der Code gerade ausgeführt wird. \n",
+ "- Manchmal bleibt das Notebook aber auch einfach hängen, dann benutzt folgende Möglichkeit: **Menüleiste-> Kernel-> restart and clear output**. Damit wird das Notebook komplett neu geladen, allerdings müsst ihr die vorherigen Codeblöcke auch neu ausführen."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "- **Pair-Programming** bitte einhalten: **\"nicht gleichzeitig\"** programmieren, sondern **abwechselnd aktiv** sein. Das ist für alle Beteiligten ein Vorteil!"
+ "- Einrücken durch die **\"Tabulatortaste\" (tab)**, um die richtige Formatierung einfach zu bekommen (bei Definitionen von Funktionen, for- oder while-Schleifen, if-Bedingungen, etc.)\n",
+ "- Falsches Einrücken ergibt häufig den Fehler: **IndentationError**\n",
+ "- Beispiel:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def example():\n",
+ " i=0\n",
+ " while i <= 5:\n",
+ " if i<1:\n",
+ " print(\"Mit der tab-Taste kann man immer 'eins weiter' einrücken.\")\n",
+ " elif i==5:\n",
+ " print(\"Mit 'tab' und 'shift' gleichzeitig rückt man 'eins' wieder nach hinten.\")\n",
+ " i=i+1\n",
+ " \n",
+ "example()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "## Rekursion\n",
+ "### Browser-Einstellungen für Jupyter-Notebook\n",
"\n",
- "Eine gute Hilfe ist die Webseite: http://www.pythontutor.com.\n",
- "Dort könnt ihr euren Python Code hochladen und Schritt für Schritt durchführen. \n",
- "Probiert es aus *(Achtung: Sie müssen die Funktion auch dort aufrufen)*. \n",
+ "Jupyter-Notebook wird immer in dem Browser geöffnet, der auf dem Computer als Standardbrowser festgelegt ist.\n",
+ "Im PC-Pool ist das zur Zeit der Internet-Explorer und wir können das leider nicht ändern.\n",
+ "Dadurch funktionieren manche Shortcuts leider nicht.\n",
+ "\n",
+ "Auf euren PC's zu Hause könnt ihr es aber einfach ändern: \n",
"\n",
- "Das funktioniert nicht nur für Rekursion, sonder mit jedem Code, den ihr in Python geschrieben habt."
+ "(Wir empfehlen Firefox als Standardbrowser)\n",
+ "\n",
+ "macOS:\n",
+ "\n",
+ " 1. Öffnen sie die Systemeinstellungen.\n",
+ " 2. Klicken Sie auf „Allgemein“.\n",
+ " 3. Wählen Sie unter „Standard-Webbrowser“ den gewünschten Browser aus.\n",
+ "\n",
+ "Ubuntu Linux:\n",
+ "\n",
+ " 1. Öffnen Sie die System Settings.\n",
+ " 2. Klicken Sie auf „Applications“.\n",
+ " 3. Wählen Sie in der linken Spalte „Default Applications“ aus.\n",
+ " 4. Klicken Sie in der Spalte rechts davon auf „Web Browser“.\n",
+ " 5. Wählen Sie „in the following browser:“ aus.\n",
+ " 6. Wählen Sie den gewünschten Browser aus.\n",
+ "\n",
+ "Windows:\n",
+ "\n",
+ " 1. Öffnen Sie die Systemsteuerung.\n",
+ " 2. Klicken Sie auf „Standardprogramme“.\n",
+ " 3. Klicken Sie auf „Standardprogramme festlegen“.\n",
+ " 4. Klicken Sie in der Liste auf den gewünschten Browser.\n",
+ " 5. Klicken Sie dann auf „Dieses Programm als Standard festlegen“.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "<h1><center> Beispielcode</center></h1>"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "## Beispielrechnungen"
+ "### Kommentare\n",
+ "\n",
+ "- Kommentare in Codeblöcken kann man mit Hilfe von # schreiben"
]
},
{
@@ -94,9 +214,17 @@
"metadata": {},
"outputs": [],
"source": [
- "40/1.61 \n",
- "#Hier rechnen wir 40km in Meilen um. Das Ergebnis, welches Python ausgibt, bitte nicht für weitere Rechnungen verwenden.\n",
- "# Stattdessen können wir einfach den Term in Klammern benutzen (40/1.61) oder die Rechnung in einer Variable speichern (z.B. Meilen= 40/1.61)"
+ "# We are inside a Code block. \n",
+ "# But with the help of # we can still write whatever we want to document our code. This is really helpful.\n",
+ "# Shortcut: Str+/ (comment and uncomment)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "- Zusätzlich gibt es Docstrings (kurz für Documentation strings). Die Syntax sind drei Gänsefüßchen am Anfang und am Ende der Zeichenkette. Damit könnt ihr eure Funktionen und Methoden gut beschreiben, Zeilenumbrüche funktionieren."
]
},
{
@@ -105,27 +233,26 @@
"metadata": {},
"outputs": [],
"source": [
- "#example\n",
- "#Ein Mann hat eine 40km Fahrradtour in 2h absolivert. \n",
- "#1. Wieviele Sekunden pro Meter ist er im Durchschnitt gefahren?\n",
- "#2. Mit wieviel Meter pro Minute war er im Durchschnitt unterwegs?\n",
- "#3. Mit wieviel Meilen pro Stunde war er im Durchschnitt unterwegs?\n",
- "#solution:\n",
+ "def function(): \n",
+ " \"\"\"\n",
+ " Do nothing, but document it.\n",
"\n",
- "#Zeit in verschiedenen Einheiten\n",
- "Stunden=2\n",
- "Minuten=Stunde*60\n",
- "Sekunden=Minute*60\n",
- "#Strecken in verschiedenen Einheiten\n",
- "Kilometer=10\n",
- "Meter=40*1000\n",
- "Meilen=40/1.61\n",
- "print(\"In einer print()-Funktion kann man\",\"mehrere Zeichenketten und Variablen\", \" durch Kommata trennen und zusammen ausgeben\")\n",
- "print(\"Sekunden pro Meter :\", Sekunden/Meter)\n",
- "print(\"Meter pro Mintue :\", Meter/Minuten)\n",
- "print(\"Meilen pro Stunde :\", Meilen/Stunden, \"Perfekt\")\n",
- "print(\"Meilen pro Stunde :\", (40/1.61)/Stunden, \"Okay\")\n",
- "print(\"Meilen pro Stunde :\", 24.844720496894407/Stunden, \"Bitte nicht gerundete Zahlen übernehmen\")"
+ " No, really, it doesn't do anything. \n",
+ " \"\"\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Zahlen - float"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "- Gleitkommazahlen (floats) immer mit **Punkt** statt **Komma* angeben -> 29.99 statt 29,99"
]
},
{
@@ -134,20 +261,12 @@
"metadata": {},
"outputs": [],
"source": [
- "print(\"Division von integers \\n\")\n",
- "#Teilen von Ganzzahlen (integers oder int) mit \"/\" (gibt den genauen Wert zurück, typ=float)\n",
- "print(\"Hier dividieren wir mit Hilfe von /: \",2/60,3/2,8/3, sep='\\t')\n",
- "\n",
- "#Teilen von Ganzzahlen (integers oder int) mit \"//\" (gibt den abgerundeten Wert wieder, typ=int)\n",
- "print(\"Hier dividieren wir mit Hilfe von //: \",2//60,3//2,8//3, sep='\\t')\n",
- "\n",
- "print(\"\\n Division von float und integers \\n\")\n",
- "\n",
- "#Teilen von Float und Ganzzahlen (integers oder int) mit \"/\" (gibt den genauen Wert zurück, typ=float)\n",
- "print(\"Hier dividieren wir mit Hilfe von /: \",2/60.0,3.0/2,8.4/3,sep='\\t')\n",
+ "#Gleitkommazahl durch Punkt getrennt -> RICHTIG\n",
"\n",
- "#Teilen von Float und Ganzzahlen (integers oder int) mit \"//\" (gibt den abgerundeten Wert wieder, typ=float)\n",
- "print(\"Hier dividieren wir mit Hilfe von //: \",2//60.0,3.0//2,8.4//3,sep='\\t')"
+ "preis=29.99\n",
+ "print(preis)\n",
+ "print(type(preis))\n",
+ "# python erkennt die Zahl und gibt die Zahl wieder. "
]
},
{
@@ -156,19 +275,21 @@
"metadata": {},
"outputs": [],
"source": [
- "#Bitte diesen Codeblock einfach ausführen\n",
- "\n",
- "print(\"Variablen: \\n\")\n",
- "test_variable=\"Ich gebe erstmal nichts aus, bin aber gespeichert\"\n",
- "testVariable=\"Ich gebe auch nichts aus, bin ebenso gespeichert\"\n",
- "\n",
- "\n",
- "print(\"Nur durch diese Print-Funktion erzeuge ich einen Output: \\n test_variable:\\t\",test_variable,\"! \\n testVariable: \\t\", testVariable)\n",
+ "# Gleitkommazahl durch Komma getrennt -> FALSCH\n",
"\n",
+ "preis=29,99\n",
+ "print(preis)\n",
+ "type(preis)\n",
+ "# Python erkennt zwei Zahlen, die es in einem Tupel speichert."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Print - Funktion\n",
"\n",
- "#und ich bin nur eine Kommentarzeile. \n",
- "#Ich gebe nichts aus, kann aber beschreiben, was in diesem Codeblock gemacht wird, ohne den Codeblock auszuführen.\n",
- "#Das hilft anderen, den Code zu verstehen."
+ "- Die Print-Funktion \"print()\" kann mehrere Argumente entgegennehmen. Das können ganz verschiedene Datentypen sein. Die verschiedenen Argumente müssen jeweils durch Kommata getrennt werden.\n"
]
},
{
@@ -177,8 +298,42 @@
"metadata": {},
"outputs": [],
"source": [
- "#Bitte diesen Codeblock einfach ausführen\n",
+ "# Beispiele:\n",
+ "\n",
+ "# Der print-Befehl ist eine überaus nützliche Funktion in python. \n",
+ "# Wir können uns damit an jeder Stelle unseres Codes Zwischenergebnisse,\n",
+ "# Ergebnisse, Variablen, etc. ausgeben lassen.\n",
+ "\n",
+ "#Zeichenketten:\n",
+ "print(\"\\n \\n Jetzt kommen wir zu den Zeichenketten \\n\")\n",
+ "print(\"Hallo! Schön, dass du es hierher geschafft hast :)\")\n",
+ "\n",
+ "#Zahlen:\n",
+ "print(\"\\n \\n Jetzt kommen wir zu den Zahlen \\n\")\n",
+ "print(10)\n",
+ "print(10,20,30)\n",
+ "\n",
+ "#Variablen:\n",
+ "print(\"\\n \\n Jetzt kommen wir zu den Variablen \\n\")\n",
+ "a=10\n",
+ "print(a)\n",
+ "\n",
+ "#Verkapselungen:\n",
+ "print(\"\\n \\n Jetzt kommen wir zu den Verkapselungen \\n\")\n",
+ "print(\"Die Lösung lautet:\", 100, \"Hier kann noch mehr Text stehen\")\n",
+ "\n",
+ "print(\"Zeichenketten kann man auch mit dem + Operator verbinden:\"+\" Das kann man hier sehen.\")\n",
"\n",
+ "print(\"Zahlen dagegen werden dadurch addiert und die Summe wird ausgegeben: \", 5+4)\n",
+ "\n",
+ "\n",
+ "a=10\n",
+ "b=20\n",
+ "c=\"Hier könnte alles stehen.\"\n",
+ "print(\"Wir können auch Variablen dazunehmen:\",a,b,c)\n",
+ "\n",
+ "# Jetzt kommen komplizierte Beispiele:\n",
+ "print(\"\\n \\n Jetzt kommen wir zu komplizierte Beispiele \\n\")\n",
"print(\"Durch verschiedene Zeichen kann man den Output der Print-Funktion 'verschönern'. \\n\")\n",
"\n",
"print('\"\\\\n\" : erzeugt einen Zeilenabsatz \\n' )\n",
@@ -195,16 +350,14 @@
"print(\"BeispieL: \",\"Jetzt\", \"werden\", \"wir\", \"zwischen\", \"jeder\", \"Anweisung\", \"einen\", \"Abstand\", \"definieren\", sep=\"\\n\")\n",
"\n",
"\n",
- "#Macht euch den Unterschied zwischen \\t und \\n innerhalb einer Zeichenkette und sep=\"\\n\" klar."
+ "#Macht euch den Unterschied zwischen \\t und \\n innerhalb einer Zeichenkette und sep=\"\\n\" bzw. sep=\"\\t\" klar.\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "## Print - Funktion\n",
- "\n",
- "- Die Print-Funktion \"print()\" kann mehrere Argumente entgegennehmen. Das können ganz verschiedene Datentypen sein. Die verschiedenen Argumente müssen jeweils durch Kommata getrennt werden.\n"
+ "### Code Beispiele"
]
},
{
@@ -212,7 +365,11 @@
"execution_count": null,
"metadata": {},
"outputs": [],
- "source": []
+ "source": [
+ "40/1.61 \n",
+ "#Hier rechnen wir 40km in Meilen um. Das Ergebnis, welches Python ausgibt, bitte nicht für weitere Rechnungen verwenden.\n",
+ "# Stattdessen können wir einfach den Term in Klammern benutzen (40/1.61) oder die Rechnung in einer Variable speichern (z.B. Meilen= 40/1.61)"
+ ]
},
{
"cell_type": "code",
@@ -220,21 +377,27 @@
"metadata": {},
"outputs": [],
"source": [
- "variable1=\"Hello\"\n",
- "variable2=\",\"\n",
- "variable3=\"World\"\n",
- "variable4=\"!\"\n",
+ "#example\n",
+ "#Ein Mann hat eine 40km Fahrradtour in 2h absolivert. \n",
+ "#1. Wieviele Sekunden pro Meter ist er im Durchschnitt gefahren?\n",
+ "#2. Mit wieviel Meter pro Minute war er im Durchschnitt unterwegs?\n",
+ "#3. Mit wieviel Meilen pro Stunde war er im Durchschnitt unterwegs?\n",
+ "#solution:\n",
"\n",
- "print(variable1,variable2,\" Zwischendurch kann man auch eine Zeichenkette einbauen, solange man sie durch Kommata von den Variablen trennt\", variable3, variable4)"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "- Um die print-Funktion zu formatieren und dadurch übersichtlicher zu gestalten, gibt es einige Hilfsmittel:\n",
- "- \"\\n\" : Backslash + n in einer Zeichenkette (d.h. in Anführungszeichen) ergeben eine neue Zeile\n",
- "- \"\\t\" : Backslash + t in einer Zeichenkette (d.h. in Anführungszeichen) ergeben eine Abstand von mehreren Leerzeichen"
+ "#Zeit in verschiedenen Einheiten\n",
+ "Stunden=2\n",
+ "Minuten=Stunde*60\n",
+ "Sekunden=Minute*60\n",
+ "#Strecken in verschiedenen Einheiten\n",
+ "Kilometer=10\n",
+ "Meter=40*1000\n",
+ "Meilen=40/1.61\n",
+ "print(\"In einer print()-Funktion kann man\",\"mehrere Zeichenketten und Variablen\", \" durch Kommata trennen und zusammen ausgeben\")\n",
+ "print(\"Sekunden pro Meter :\", Sekunden/Meter)\n",
+ "print(\"Meter pro Mintue :\", Meter/Minuten)\n",
+ "print(\"Meilen pro Stunde :\", Meilen/Stunden, \"Perfekt\")\n",
+ "print(\"Meilen pro Stunde :\", (40/1.61)/Stunden, \"Okay\")\n",
+ "print(\"Meilen pro Stunde :\", 24.844720496894407/Stunden, \"Bitte nicht gerundete Zahlen übernehmen\")"
]
},
{
@@ -243,26 +406,37 @@
"metadata": {},
"outputs": [],
"source": [
- "variable1=\"Hello\"\n",
- "variable2=\",\"\n",
- "variable3=\"World\"\n",
- "variable4=\"!\"\n",
+ "print(\"Division von integers \\n\")\n",
+ "#Teilen von Ganzzahlen (integers oder int) mit \"/\" (gibt den genauen Wert zurück, typ=float)\n",
+ "print(\"Hier dividieren wir mit Hilfe von /: \",2/60,3/2,8/3, sep='\\t')\n",
+ "\n",
+ "#Teilen von Ganzzahlen (integers oder int) mit \"//\" (gibt den abgerundeten Wert wieder, typ=int)\n",
+ "print(\"Hier dividieren wir mit Hilfe von //: \",2//60,3//2,8//3, sep='\\t')\n",
"\n",
- "print('\"\\\\n\" funktioniert folgendermaßen zwischen Variablen:')\n",
- "print(variable1,variable2,\"\\n\",variable3, variable4)\n",
- "print(\"oder auch innerhalb einer Zeichenkette\")\n",
- "print(\"Hello, \\n World !\")\n",
+ "print(\"\\n Division von float und integers \\n\")\n",
"\n",
+ "#Teilen von Float und Ganzzahlen (integers oder int) mit \"/\" (gibt den genauen Wert zurück, typ=float)\n",
+ "print(\"Hier dividieren wir mit Hilfe von /: \",2/60.0,3.0/2,8.4/3,sep='\\t')\n",
"\n",
- "print('\"\\\\t\" funktioniert analog.')\n"
+ "#Teilen von Float und Ganzzahlen (integers oder int) mit \"//\" (gibt den abgerundeten Wert wieder, typ=float)\n",
+ "print(\"Hier dividieren wir mit Hilfe von //: \",2//60.0,3.0//2,8.4//3,sep='\\t')"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "- Zu guter Letzt kann man noch einen allgemeinen Abstand zwischen den Argumenten definieren, der standardmäßig ein Leerzeichen ist. Dadurch gibt man ganz am Ende einer Print-Funktion folgende Anweisung: sep= \n",
- "\n"
+ "## Importieren von Modulen und Bibliotheken"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "- Stellen Datentypen oder Funktionen für alle Python-Programme bereit\n",
+ "- Syntax: `import module` \n",
+ "- Konvention: Steht **immer am Anfang des Codes**\n",
+ "- Beispiel:"
]
},
{
@@ -271,33 +445,45 @@
"metadata": {},
"outputs": [],
"source": [
- "print(\"Standard: ein Leerzeichen : \",variable1,variable2,variable3, variable4)\n",
- "print(\"Variante: kein Zeichen : \",variable1,variable2,variable3, variable4, sep='')\n",
- "print(\"Variante: tab-Abstand : \", variable1,variable2,variable3, variable4, sep='\\t')\n",
- "print(\"Variante: neue Zeile : \", variable1,variable2,variable3, variable4, sep='\\n')\n",
- "print(\"Variante: drei Punkte (man kann jegliches Zeichen angeben) : \", variable1,variable2,variable3, variable4, sep='...')\n"
+ "import math\n",
+ "import turtle\n",
+ "import csv\n",
+ "\n",
+ "#hier steht Code"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "## Zahlen - float"
+ "## Funktionen\n",
+ "\n",
+ "Funktion funktionieren in Python wie mathematische Funktionen aus der Schule: \n",
+ "\n",
+ "Stellt euch die Funktion f(x,y)=x*y vor. In Python definieren wir sie wie folgt:"
]
},
{
- "cell_type": "markdown",
+ "cell_type": "code",
+ "execution_count": null,
"metadata": {},
+ "outputs": [],
"source": [
- "- WICHTIG: Bei Ankündigung von Michel: Bitte Jupyter Notebooks durcharbeiten oder wenigstens versuchen. Ich verstehe, dass man nicht immer alle Übungen alleine schafft, aber zumindest die Theorie kann man mit seinem Partner durcharbeiten. \n",
- "- Falls Hilfe benötigt wird -> Michel: Email oder vorbeikommen | Tutorium Dienstags"
+ "def f(x,y):\n",
+ " return x*y"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "- Gleitkommazahlen (floats) immer mit \".\" statt \",\" angeben -> 29.99 statt 29,99"
+ "Jetzt haben wir die Funktion zwar definiert, aber sie gibt noch kein Ergebnis zurück. Das passiert nur, wenn wir die Funktion aufrufen. \n",
+ "\n",
+ "Um die Funktion aufzurufen, müssen wir die Parameter x und y explizit angeben, z.B. x=5 und y=3. \n",
+ "\n",
+ "In der Schule haben wir früher Folgendes geschrieben: f(5,3)=5*3=15. \n",
+ "\n",
+ "In Python machen wir nichts anderes, nur das Berechnen überlassen wir python:"
]
},
{
@@ -306,12 +492,23 @@
"metadata": {},
"outputs": [],
"source": [
- "#Gleitkommazahl durch Punkt getrennt -> RICHTIG\n",
+ "def f(x,y):\n",
+ " return x*y\n",
"\n",
- "preis=29.99\n",
- "print(preis)\n",
- "print(type(preis))\n",
- "# python erkennt die Zahl und gibt die Zahl wieder. "
+ "print(\"Wenn eine Funktion einen return-Rückgabewert hat, muss man die Funktion durch print() aufrufen, um das Ergebnis angezeigt zu bekommen. \\n\")\n",
+ "f(5,3)\n",
+ "print(\"Wie man sieht, wird nichts auf das Display ausgegeben. Also verschachteln wir unser Funktionsaufruf f(5,3) in einen print()-Aufruf. \\n\")\n",
+ "\n",
+ "print(\"Es gibt verschiedene Wege:\")\n",
+ "print(f(5,3)) \n",
+ "\n",
+ "print(\"\\nAlternative 1:\")\n",
+ "print(f(x=5,y=3)) \n",
+ "\n",
+ "print(\"\\nAlternative 2:\")\n",
+ "variable_x=5 \n",
+ "variable_y=3\n",
+ "print(f(variable_x, variable_y)) "
]
},
{
@@ -320,42 +517,22 @@
"metadata": {},
"outputs": [],
"source": [
- "# Gleitkommazahl durch Komma getrennt -> FALSCH\n",
+ "def beispiel(x):\n",
+ " print(x)\n",
+ " \n",
+ "print(\"Falls die Funktion kein return hat, sondern nur print-Anweisungen, dann reicht es, die Funktion aufzufen.\") \n",
+ "print(\"print() innerhalb der Funktion gibt x aus. \\n\")\n",
"\n",
- "preis=29,99\n",
- "print(preis)\n",
- "type(preis)\n",
- "# Python erkennt zwei Zahlen, die es in einem Tupel speichert."
+ "\n",
+ "beispiel(\"Das ist ein Funktionsaufruf und diese Zeichenkette ist unser Parameter x\")\n",
+ "\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "## Importieren von Modulen und Bibliotheken"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "- Stellen Datentypen oder Funktionen für alle Python-Programme bereit\n",
- "- Syntax: `import module` \n",
- "- Konvention: Steht **immer am Anfang des Codes**\n",
- "- Beispiel:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "import math\n",
- "import turtle\n",
- "import csv\n",
- "\n",
- "#hier steht Code"
+ "**Fazit**: Um eine Funktion aufzurufen und ein Ergebnis herauszubekommen, reicht es nicht, die Funktion zu definieren. Sie muss anschließend **aufgerufen** werden. Die **Parameter müssen explizit** angegeben werden."
]
},
{
@@ -575,136 +752,6 @@
"turtle.mainloop()\n",
"turtle.bye()"
]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Funktionen\n",
- "\n",
- "Funktion funktionieren in Python wie mathematische Funktionen aus der Schule: \n",
- "\n",
- "Stellt euch die Funktion f(x,y)=x*y vor. In Python definieren wir sie wie folgt:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "def f(x,y):\n",
- " return x*y"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Jetzt haben wir die Funktion zwar definiert, aber sie gibt noch kein Ergebnis zurück. Das passiert nur, wenn wir die Funktion aufrufen. \n",
- "\n",
- "Um die Funktion aufzurufen, müssen wir die Parameter x und y explizit angeben, z.B. x=5 und y=3. \n",
- "\n",
- "In der Schule haben wir früher Folgendes geschrieben: f(5,3)=5*3=15. \n",
- "\n",
- "In Python machen wir nichts anderes, nur das Berechnen überlassen wir python:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "print(\"Es gibt verschiedene Wege: \\n \\n\")\n",
- "\n",
- "print(\"Lösung von f(x=5,y=3) : \", f(x=5,y=3)) \n",
- "print(\"\\nAlternative 1:\")\n",
- "print(\"Lösung von f(5,3) : \", f(5,3)) \n",
- "print(\"\\nAlternative 2:\")\n",
- "variable_x=5\n",
- "variable_y=3\n",
- "print(\"Lösung von f(variable_x, variable_y) : \", f(variable_x, variable_y)) "
- ]
- },
- {
- "cell_type": "raw",
- "metadata": {},
- "source": [
- "Fazit: Um eine Funktion aufzurufen und ein Ergebnis herauszubekommen, reicht es nicht, die Funktion zu definieren. Sie muss anschließend aufgerufen werden. Die Parameter müssen explizit angegeben werden."
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Browser-Einstellungen für Jupyter-Notebook\n",
- "\n",
- "Jupyter-Notebook wird immer in dem Browser geöffnet, der auf dem Computer als Standardbrowser festgelegt ist.\n",
- "Im PC-Pool ist das zur Zeit der Internet-Explorer und wir können das leider nicht ändern.\n",
- "Dadurch funktionieren manche Shortcuts leider nicht.\n",
- "\n",
- "Auf euren PC's zu Hause könnt ihr es aber einfach ändern: \n",
- "\n",
- "(Wir empfehlen Firefox als Standardbrowser)\n",
- "\n",
- "macOS:\n",
- "\n",
- " 1. Öffnen sie die Systemeinstellungen.\n",
- " 2. Klicken Sie auf „Allgemein“.\n",
- " 3. Wählen Sie unter „Standard-Webbrowser“ den gewünschten Browser aus.\n",
- "\n",
- "Ubuntu Linux:\n",
- "\n",
- " 1. Öffnen Sie die System Settings.\n",
- " 2. Klicken Sie auf „Applications“.\n",
- " 3. Wählen Sie in der linken Spalte „Default Applications“ aus.\n",
- " 4. Klicken Sie in der Spalte rechts davon auf „Web Browser“.\n",
- " 5. Wählen Sie „in the following browser:“ aus.\n",
- " 6. Wählen Sie den gewünschten Browser aus.\n",
- "\n",
- "Windows:\n",
- "\n",
- " 1. Öffnen Sie die Systemsteuerung.\n",
- " 2. Klicken Sie auf „Standardprogramme“.\n",
- " 3. Klicken Sie auf „Standardprogramme festlegen“.\n",
- " 4. Klicken Sie in der Liste auf den gewünschten Browser.\n",
- " 5. Klicken Sie dann auf „Dieses Programm als Standard festlegen“.\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Tipps und Tricks \n",
- "- Einrücken durch die \"Tabulatortaste\", um die richtige Formatierung einfach zu bekommen (bei Definitionen von Funktionen, for- oder while-Schleifen, if-Bedingungen, etc.)\n",
- "- Beispiel:"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "def example():\n",
- " i=0\n",
- " while i <= 5:\n",
- " if i<1:\n",
- " print(\"Mit der tab-Taste kann man immer 'eins weiter' einrücken.\")\n",
- " elif i==5:\n",
- " print(\"Mit 'tab' und 'shift' gleichzeitig rückt man 'eins' wieder nach hinten.\")\n",
- " i=i+1\n",
- " \n",
- "example()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "- Alternativer Python-Kurs für Interessierte: https://automatetheboringstuff.com/"
- ]
}
],
"metadata": {
diff --git "a/notebooks/einf\303\274hrung_jn.ipynb" "b/notebooks/einf\303\274hrung_jn.ipynb"
new file mode 100644
index 0000000000000000000000000000000000000000..1ddade9fa602a7889b0501987848e85e1069ee36
--- /dev/null
+++ "b/notebooks/einf\303\274hrung_jn.ipynb"
@@ -0,0 +1,900 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "<h1>Table of Contents<span class=\"tocSkip\"></span></h1>\n",
+ "<div class=\"toc\"><ul class=\"toc-item\"><li><span><a href=\"#Jupyter-Notebook-Grundlagen\" data-toc-modified-id=\"Jupyter-Notebook-Grundlagen-1\"><span class=\"toc-item-num\">1 </span>Jupyter Notebook Grundlagen</a></span><ul class=\"toc-item\"><li><span><a href=\"#Standardbrowser\" data-toc-modified-id=\"Standardbrowser-1.1\"><span class=\"toc-item-num\">1.1 </span>Standardbrowser</a></span><ul class=\"toc-item\"><li><span><a href=\"#Anleitungen\" data-toc-modified-id=\"Anleitungen-1.1.1\"><span class=\"toc-item-num\">1.1.1 </span>Anleitungen</a></span></li></ul></li><li><span><a href=\"#Shortcuts\" data-toc-modified-id=\"Shortcuts-1.2\"><span class=\"toc-item-num\">1.2 </span>Shortcuts</a></span><ul class=\"toc-item\"><li><span><a href=\"#Beispiel:-Markdown-Zelle-vs.-Code-Zelle\" data-toc-modified-id=\"Beispiel:-Markdown-Zelle-vs.-Code-Zelle-1.2.1\"><span class=\"toc-item-num\">1.2.1 </span>Beispiel: Markdown Zelle vs. Code Zelle</a></span></li></ul></li></ul></li><li><span><a href=\"#Python-Grundlagen\" data-toc-modified-id=\"Python-Grundlagen-2\"><span class=\"toc-item-num\">2 </span>Python Grundlagen</a></span><ul class=\"toc-item\"><li><span><a href=\"#Grundlegende-Datentypen\" data-toc-modified-id=\"Grundlegende-Datentypen-2.1\"><span class=\"toc-item-num\">2.1 </span>Grundlegende Datentypen</a></span></li><li><span><a href=\"#Listen\" data-toc-modified-id=\"Listen-2.2\"><span class=\"toc-item-num\">2.2 </span>Listen</a></span></li><li><span><a href=\"#Mengen\" data-toc-modified-id=\"Mengen-2.3\"><span class=\"toc-item-num\">2.3 </span>Mengen</a></span></li><li><span><a href=\"#Ranges\" data-toc-modified-id=\"Ranges-2.4\"><span class=\"toc-item-num\">2.4 </span>Ranges</a></span></li><li><span><a href=\"#Tupel\" data-toc-modified-id=\"Tupel-2.5\"><span class=\"toc-item-num\">2.5 </span>Tupel</a></span></li><li><span><a href=\"#Dictionaries\" data-toc-modified-id=\"Dictionaries-2.6\"><span class=\"toc-item-num\">2.6 </span>Dictionaries</a></span></li><li><span><a href=\"#If-Anweisungen\" data-toc-modified-id=\"If-Anweisungen-2.7\"><span class=\"toc-item-num\">2.7 </span>If-Anweisungen</a></span></li><li><span><a href=\"#Schleifen\" data-toc-modified-id=\"Schleifen-2.8\"><span class=\"toc-item-num\">2.8 </span>Schleifen</a></span></li><li><span><a href=\"#Funktionen\" data-toc-modified-id=\"Funktionen-2.9\"><span class=\"toc-item-num\">2.9 </span>Funktionen</a></span></li></ul></li><li><span><a href=\"#----------------Praktisch-für-Python,-aber-nicht-für-unseren-Kurs------------------\" data-toc-modified-id=\"----------------Praktisch-für-Python,-aber-nicht-für-unseren-Kurs-------------------3\"><span class=\"toc-item-num\">3 </span><font color=\"red\">--------------- Praktisch für Python, aber nicht für unseren Kurs -----------------</font></a></span><ul class=\"toc-item\"><li><span><a href=\"#Lambda-Funktionen\" data-toc-modified-id=\"Lambda-Funktionen-3.1\"><span class=\"toc-item-num\">3.1 </span>Lambda-Funktionen</a></span></li><li><span><a href=\"#List-Comprehensions\" data-toc-modified-id=\"List-Comprehensions-3.2\"><span class=\"toc-item-num\">3.2 </span>List Comprehensions</a></span></li><li><span><a href=\"#Klassen\" data-toc-modified-id=\"Klassen-3.3\"><span class=\"toc-item-num\">3.3 </span>Klassen</a></span></li></ul></li></ul></div>"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Jupyter Notebook Grundlagen\n",
+ "\n",
+ "**INFO:** Falls Sie im Python Programmierkurs sind und dies ihr erstes geöffnetes Jupyter Notebook ist, Herzlichen Glückwunsch! :)\n",
+ "\n",
+ "**INFO 2:** Falls Sie im Python Programmierkurs sind und dies ihr erstes geöffnetes Jupyter Notebook ist, lesen Sie nur bis bis zum Kapitel \"Python Grundlagen\". Danach wechseln Sie zum Notebook *seminar00.ipynb*\n",
+ "\n",
+ "- open-source, browserbasiertes Tool für verschiedene Programmiersprachen (wir benutzen Python)\n",
+ "- **Vorteil**: Code, Visualisierungen und Text / Erklärungen in einem Dokument\n",
+ "- Notebook besteht aus Blöcken bzw. Zellen\n",
+ "- Unter der Zelle wird der Rückgabewert des letzten Statements ausgegeben\n",
+ "- Quellcode kann auf mehrere Blöcke aufgeteilt werden (Variablen behalten ihre Gültigkeit/Sichtbarkeit)\n",
+ "- Es gibt zwei Arten von Blöcken: \"Code\" ist für Python-Code, \"Markdown\" ist für Texte, die Sie mit Hilfe der [Markdown-Syntax](https://de.wikipedia.org/wiki/Markdown#Auszeichnungsbeispiele) formatieren können.\n",
+ "- Sie können auf Text doppelt klicken, um sich den Markdown-Quellcode anzuzeigen. Probieren Sie es mit diesem Text aus.\n",
+ "- durch die Tastenkombination \"Strg\" und \"Enter\" oder durch Drücken von dem \"Run\" Button oben im Menü kommen Sie wieder in den Lesemodus \n",
+ "- Wenn Sie mal etwas \"kaputtgespielt\" haben, hilft es evtl., im \"Kernel\"-Menü den \"Restart\"-Eintrag auszuwählen.\n",
+ "\n",
+ "\n",
+ "\n",
+ "## Standardbrowser\n",
+ "\n",
+ "Bitte verwenden Sie **nicht** Safari oder Internet Explorer. Auch mit Windows Edge gab es in der Vergangenheit Probleme. Wir empfehlen die Verwendung von Firefox, aber auch Google Chrome lief in der Vergangenheit problemlos. Wenn Sie unsicher sind, was ihr aktueller Standardbrowser ist, folgen Sie einfach der folgenden Anleitung zum Ändern des Standardbrowsers und gehen Sie sicher, dass der richtige Standardbrowser ausgewählt ist.\n",
+ "\n",
+ "### Anleitungen\n",
+ "\n",
+ "**Änderung des Standardbrowsers in...** \n",
+ "\n",
+ "*macOS:* \n",
+ "1. Öffnen sie die Systemeinstellungen.\n",
+ "2. Klicken Sie auf „Allgemein“.\n",
+ "3. Wählen Sie unter „Standard-Webbrowser“ den gewünschten Browser aus.\n",
+ "\n",
+ "*Ubuntu Linux:* \n",
+ "1. Öffnen Sie die System Settings.\n",
+ "2. Klicken Sie auf „Applications“.\n",
+ "3. Wählen Sie in der linken Spalte „Default Applications“ aus.\n",
+ "4. Klicken Sie in der Spalte rechts davon auf „Web Browser“.\n",
+ "5. Wählen Sie „in the following browser:“ aus.\n",
+ "6. Wählen Sie den gewünschten Browser aus.\n",
+ "\n",
+ "*Windows:* \n",
+ "1. Öffnen Sie die Systemsteuerung.\n",
+ "2. Klicken Sie auf „Standardprogramme“.\n",
+ "3. Klicken Sie auf „Standardprogramme festlegen“.\n",
+ "4. Klicken Sie in der Liste auf den gewünschten Browser.\n",
+ "5. Klicken Sie dann auf „Dieses Programm als Standard festlegen“.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "## Shortcuts\n",
+ "\n",
+ "**Bitte probieren Sie alle unten stehenden Befehle und verstehen Sie, was gemacht wird. Das ist die Basis, die Sie für das Arbeiten mit Jupyter Notebooks brauchen.**\n",
+ "\n",
+ "Übersicht: *Menü Help -> Keyboard Shortcuts*\n",
+ "\n",
+ "Wichtigste Shortcuts: \n",
+ "\n",
+ "- *Enter*: Editiermodus für selektierte Zelle (grün umrandet)\n",
+ "- *Esc*: Editiermodus verlassen/Kommandomodus (blau umrandet)\n",
+ "- *Strg + Enter*: Selektierte Zelle ausführen\n",
+ "- *Shift + Enter*: Selektierte Zelle ausführen und in nächste Zelle springen\n",
+ "\n",
+ "Im Editiermodus:\n",
+ "- *Tab*: Autocomplete oder Einrücken\n",
+ "- *Shift + Tab*: Einrücken rückwärts\n",
+ "\n",
+ "Im Kommando-/Lesemodus:\n",
+ "- *B*: Zelle darunter einfügen\n",
+ "- *A*: Zelle darüber einfügen\n",
+ "- *DD*: Zelle löschen\n",
+ "- *M*: Zelltyp Markdown (für formatierte beschreibende Texte, zB diese Zelle)\n",
+ "- *Y*: Zelltyp Code (Default)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Beispiel: Markdown Zelle vs. Code Zelle"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Dies ist eine **Markdown Zelle**. Hier kann jeglicher Text geschrieben werden. Durch Strg+Enter wird er in den Lesemodus gebracht, durch ein einfach Enter (oder Doppelklick) in den Editiermodus.\n",
+ "\n",
+ "Hier werden keine Rechnungen ausgeführt, siehe:\n",
+ "\n",
+ "5+3\n",
+ "\n",
+ "In diesen Feldern werden Erklärungen, Aufgabenstellungen und schriftliche Antworten von euch stehen."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Das ist eine **Code Zelle**, bei Strg+Enter wird die folgende Rechnung ausgeführt und darunter angezeigt\n",
+ "# Mit Enter kommt man in den Editiermodus, mit Strg+Enter wird der Code ausgeführt.\n",
+ "# Der Text kann hier nur stehen, da eine Raute am Anfang der Zeile steht. \n",
+ "# Dadurch werden diese Zeilen nicht ausgeführt.\n",
+ "\n",
+ "5+3\n",
+ "\n",
+ "# In diesen Zellen wird der Python Code geschrieben, manchmal müssen Sie ihn schreiben, \n",
+ "# manchmal steht der Code schon dort und muss von Ihnen nur ausgeführt werden."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Python Grundlagen\n",
+ "- Dynamisch typisierte Sprache\n",
+ "- Statt geschweifter Klammern für Codeblöcke (Funktionen, Schleifen) wird Code mit vier Leerzeichen (pro Hierarchieebene) eingerückt\n",
+ "- Die meisten Editoren ersetzen Tab automatisch durch vier Leerzeichen\n",
+ "- Kommentare beginnen mit Raute #"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Grundlegende Datentypen\n",
+ "Zahlentypen (int/float) sind größtenteils äquivalent zu Java. Strings können mit doppelten oder einfachen Anführungszeichen deklariert werden."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Variablen definieren\n",
+ "\n",
+ "a = 2*2.0\n",
+ "b = 5\n",
+ "\n",
+ "# Ausgabe \n",
+ "\n",
+ "print(a + b)\n",
+ "\n",
+ "# Diese Zelle auswählen und mit `<SHIFT> + <ENTER>` ausführen.\n",
+ "# Der letzte Rückgabewert der Zelle wird dann unten ausgegeben,\n",
+ "# hier also der Wert von `a+b`:b\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Die grundlegenden Rechenoperationen __`+`, `-`, `*`, `/`__ und __`**`__ sind ebenfalls in Python verfügbar und verhalten sich, wie man es erwartet:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# äquivalent zu a = a + 1\n",
+ "a += 1\n",
+ "\n",
+ "print(a)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Potenzieren\n",
+ "\n",
+ "2**4"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Division\n",
+ "\n",
+ "2/4"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Es gibt verschiedene Variablentypen:\n",
+ " - int (Ganzzahl, z.B. 1, 20, 52432432)\n",
+ " - float (Gleitkommazahl, z.B. 1.423, 1/3, 0.23487235723)\n",
+ " - str (Zeichenkette, z.B. \"Hello World\", 'this is a string')\n",
+ " - bool (Wahrheitswerte, z.B. True, False)\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "\n",
+ "\n",
+ "# Zeichenketten bzw. strings\n",
+ "\n",
+ "text1 = 'Hallo '\n",
+ "text2 = \"Welt\"\n",
+ "\n",
+ "print (text1 + text2)\n",
+ "\n",
+ "# Andere Datentypen müssen explizit in Strings konvertiert werden,\n",
+ "# wenn sie an einen String angehängt werden sollen.\n",
+ "print(text1 + str(1))\n",
+ "\n",
+ "# oder man muss sie durch Kommata trennen:\n",
+ "\n",
+ "print(text1,1)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Zeichenkette zu float \n",
+ "float('1')\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# integer zu float \n",
+ "\n",
+ "float(1)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "*None* entspricht *null* in Java."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "myvar = None"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(myvar)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if myvar is None:\n",
+ " print('x ist nicht definiert')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Listen\n",
+ "Listen werden mit eckigen Klammern oder list() initialisiert."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "l = [1,2,3,3]\n",
+ "l.append(4)\n",
+ "\n",
+ "print(l)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Vorsicht bei der Kombination von Listen. append hängt die übergebene Variable als einzelnen Listeneintrag an die Liste an."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "l.append([5, 6])\n",
+ "\n",
+ "print(l)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Zur Kombination von zwei Listen wird der +-Operator verwendet."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "l2 = l + [5,6]\n",
+ "\n",
+ "print(l2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Mengen\n",
+ "Mengen können mit geschweiften Klammern oder set() initialisiert werden."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "s = {1,2,3,3}\n",
+ "s2 = set([2,3,4,5])\n",
+ "\n",
+ "print(s)\n",
+ "print(s.intersection(s2))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "s.add(9)\n",
+ "s.remove(2)\n",
+ "s"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Mit list() und set() können die Typen auch ineinander konvertiert werden."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "list(s)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "set([1,2,3])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Ranges\n",
+ "Auflistung von Zahlen, werden z.Bsp. für for-Schleifen mit Index verwendet."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for i in range(5):\n",
+ " print(i)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Tupel\n",
+ "Für sortierete Werte mit fester Komponentenanzahl und fester Bedeutung für jeden Eintrag."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "essen = 'Chili'\n",
+ "preis = 2.51\n",
+ "boneintrag = (essen, preis)\n",
+ "\n",
+ "print(boneintrag)\n",
+ "print(boneintrag[0])\n",
+ "print(boneintrag[1])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "(essen2, preis2) = boneintrag\n",
+ "\n",
+ "print(essen2)\n",
+ "print(preis2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Klammern können oft weggelassen werden"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "boneintrag = essen, preis\n",
+ "essen2, preis2 = boneintrag\n",
+ "\n",
+ "print(boneintrag)\n",
+ "print(essen2)\n",
+ "print(preis2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Dictionaries\n",
+ "Äquivalent zu Maps."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "d = {'Chili': 1.90, 'Penne': 2.50}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "d.keys()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "d.values()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for key, val in d.items():\n",
+ " print('{}: {}'.format(key, val))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "d['Chili']"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "d['Burger'] = 4.90\n",
+ "d"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "del d['Burger']\n",
+ "d"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## If-Anweisungen"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if 2>1 or 1>2:\n",
+ " print ('Bedingung erfüllt.')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "y = 10\n",
+ "x = 5 if y > 10 else 4\n",
+ "\n",
+ "print(x)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Schleifen"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "x = 5\n",
+ "while x > 0:\n",
+ " x -= 1\n",
+ "x"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for x in ['a', 'b', 'c']:\n",
+ " print(x)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Funktionen"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def sum_upto(n):\n",
+ " return n*(n+1)/2\n",
+ "\n",
+ "sum_upto(4)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Zur besseren Übersicht (insbesondere bei vielen Parametern) können diese auch namentlich zugewiesen werden."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sum_upto(n=4)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Funktionen können *Default-Parameter* haben, d.h. Werte, die von der Funktion als Standardwert verwendet werden (wenn kein anderer Wert übergeben wird). Default-Parameter müssen am Ende der Funktion stehen und übergeben werden."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def fun_with_default(x=3):\n",
+ " print('Parameter is {}'.format(x))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fun_with_default()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fun_with_default(x=4)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Funktionen können wie Variablen referenziert werden (Pointer auf die Funktion) und zum Beispiel als Parameter übergeben werden."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def calc_and_print(calc_function, n):\n",
+ " calc_result = calc_function(n)\n",
+ " print(calc_result)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "calc_and_print(sum_upto, 4)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# <font color='red'>--------------- Praktisch für Python, aber nicht für unseren Kurs -----------------</font> \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Lambda-Funktionen\n",
+ "I.d.R. für Inline-Funktionen. Können zum Beispiel an Funktionen als Parameter übergeben oder als Variable deklariert werden. Lambdas enthalten ein einzelnes Statement, dessen Wert automatisch der Rückgabewert ist."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "calc_square = lambda x: x**2\n",
+ "calc_square(3)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "calc_and_print(calc_square, 4)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "calc_and_print(lambda x: x**3, 4)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## List Comprehensions"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "y = [x**2 for x in range(10)]\n",
+ "y"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "xy = [(x, x**2) for x in range(10) if x%2 == 0]\n",
+ "xy"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Klassen\n",
+ "Objekte einer Klasse bekommen bei Methodenaufrufen als ersten Parameter automatisch das *\"self\"*-Objekt übergeben (vgl. *this* in Java). Dieser Parameter muss also immer auch als erster Parameter einer Klassenmethode übergeben werden. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class Vehicle():\n",
+ " # Constructor\n",
+ " def __init__(self, n_wheels=4, noise='beep'):\n",
+ " self.n_wheels = n_wheels\n",
+ " self.noise = noise\n",
+ " \n",
+ " def make_noise(self):\n",
+ " print(self.noise)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "basicVehicle = Vehicle()\n",
+ "basicVehicle.make_noise()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Properties sind immer von außen sichtbar und lassen sich verändern. Properties, die nicht zur Veränderung gedacht sind, werden nach Konvention durch zwei Unterstriche im Namen gekennzeichnet."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "basicVehicle.n_wheels"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Vererbung ist in Python möglich. In der Regel wird aber Duck-Typing verwendet. \n",
+ "\n",
+ "“When I see a bird that walks like a duck and swims like a duck and quacks like a duck, I call that bird a duck.â€"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "bike = Vehicle(n_wheels=2, noise='ring')\n",
+ "bike.make_noise()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class Bike(Vehicle):\n",
+ " def __init__(self):\n",
+ " self.n_wheels = 2\n",
+ " self.noise = 'ring'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "Bike().make_noise()"
+ ]
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "name": "python",
+ "pygments_lexer": "ipython3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/notebooks/hausaufgabe1.ipynb b/notebooks/hausaufgabe1.ipynb
index 763ebd60b917f07695cd3add6ba990b6532654df..6cd73c1567300b2a625183f3301e36512b3e3d31 100644
--- a/notebooks/hausaufgabe1.ipynb
+++ b/notebooks/hausaufgabe1.ipynb
@@ -1,5 +1,13 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "<h1>Table of Contents<span class=\"tocSkip\"></span></h1>\n",
+ "<div class=\"toc\"><ul class=\"toc-item\"><li><span><a href=\"#Aufgabe-1\" data-toc-modified-id=\"Aufgabe-1-1\"><span class=\"toc-item-num\">1 </span>Aufgabe 1</a></span></li><li><span><a href=\"#Aufgabe-2\" data-toc-modified-id=\"Aufgabe-2-2\"><span class=\"toc-item-num\">2 </span>Aufgabe 2</a></span></li><li><span><a href=\"#Aufgabe-3\" data-toc-modified-id=\"Aufgabe-3-3\"><span class=\"toc-item-num\">3 </span>Aufgabe 3</a></span></li></ul></div>"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {},
@@ -8,7 +16,17 @@
"\n",
"Geben Sie diese Hausaufgabe gemeinsam mit Ihrem/r Partner/in ab. Füllen Sie dazu dieses Notebook aus und speichern Sie es ab (Disketten-Icon oben links). Laden Sie dann die Datei (hausaufgabe1.ipynb) in Moodle hoch. Verwenden Sie Kommentare im Python-Quellcode und Markdown-Textboxen im Jupyter-Notebook ([Syntax-Beispiele](https://de.wikipedia.org/wiki/Markdown#Auszeichnungsbeispiele)) um ihr Programm zu kommentieren.\n",
"\n",
- "Wir wünschen viel Erfolg beim Lösen der Aufgaben!\n"
+ "Bitte ändern Sie den Dateinamen ihrer Hausaufgabe zu: **hausaufgabe1_nachnamePartner1_nachnamePartner2.ipynb**\n",
+ "\n",
+ "z.B. hausaufgabe1_schwab_jaeschke.ipynb\n",
+ "\n",
+ "Das können Sie einfach machen, indem Sie **jetzt** oben links auf `hausaufgabe1` klicken und den neuen Namen eingeben.\n",
+ "\n",
+ "Nutzen Sie das Wissen aus den bisher bearbeiteten Notebooks (1-3). \n",
+ "\n",
+ "Wir wünschen viel Erfolg beim Lösen der Aufgaben!\n",
+ "\n",
+ "**Tipp**: Nutzen Sie http://pythontutor.com, um ihren Code nachvollziehen zu können und Fehler zu finden!"
]
},
{
@@ -17,7 +35,11 @@
"source": [
"## Aufgabe 1\n",
"\n",
- "Was gibt jede der folgenden Anweisungen aus? Erklären Sie jeweils die Ausgabe."
+ "Was gibt jede der folgenden Anweisungen aus? Erklären Sie jeweils die Ausgabe. \n",
+ "Welche Funktionen werden genutzt und was machen diese Funktionen?\n",
+ "Entweder Sie nutzen Kommentare (mit Hilfe von der Raute #) im Code oder Sie schreiben die Antworten in eine extra Markdown Zeile.\n",
+ "\n",
+ "Falls Sie Kommentare nutzen, nehmen Sie mehrere Zeilen pro Anweisung, damit ihre Antwort in die Breite der Codezelle passt und man nicht hin- und herscrollen muss. (Sie finden heraus, was ich meine, wenn es passiert ;) )\n"
]
},
{
@@ -44,10 +66,13 @@
"cell_type": "markdown",
"metadata": {},
"source": [
+ "**Tipp**: Wichtig bei den folgenden Aufgaben ist der Umgang mit Zeichenketten und der `print`-Funktion. Das haben Sie in den seminar-Notebooks schon gelernt. Gehen Sie diese zu Beginn der Hausaufgabe noch einmal durch und achten Sie, mit welchen Operatoren man Zeichenketten zusammenfügen und manipulieren kann.\n",
+ "\n",
"## Aufgabe 2\n",
"\n",
"Ihre Aufgabe ist es, eine Funktion `boxprint` zu implementieren, die eine als Argument übergegebene Zeichenkette innerhalb einer Box ausgibt. Die horizontalen Linien der Box sollen durch `-` erzeugt werden, die vertikalen Linien durch `|` und die Ecken durch `+`. Zwischen der Zeichenkette und dem linken und rechten Rand der Box soll jeweils genau ein Leerzeichen stehen. \n",
"\n",
+ "\n",
"Beispiel: Bei Ãœbergabe des Arguments `Hello World!` soll die Funktion folgende Ausgabe erzeugen:"
]
},
@@ -70,7 +95,19 @@
"\n",
"- \n",
"- \n",
- "- \n"
+ "- \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def boxprint(zeichenkette):\n",
+ " '''Implementieren Sie hier ihre Funktion. Dieses Kommentar können Sie löschen.\n",
+ " ''' \n"
]
},
{
@@ -79,11 +116,10 @@
"metadata": {},
"outputs": [],
"source": [
- "# Implementieren Sie hier ihre Funktion\n",
- " \n",
"# Testen Sie hier ihre Funktion; fügen Sie auch eigene Tests hinzu\n",
"boxprint(\"Hello World!\")\n",
- "boxprint(\"Dieser Text muss auch in die Box passen.\")"
+ "boxprint(\"Dieser Text muss auch in die Box passen.\")\n",
+ "boxprint(\"und dieser Text auch..................................................... !\")"
]
},
{
@@ -125,7 +161,9 @@
" |_____| |_____| ~ - . _ _ _ _ _>\n",
"```\n",
"\n",
- "Nutzen Sie dazu Ihre bei der Programmierung von `boxprint` gesammelte Erfahrung.\n",
+ "Nutzen Sie dazu Ihre bei der Programmierung von `boxprint` gesammelte Erfahrung. Auch hier soll das Argument eine variable Länge aufweisen können, die \"Sprechbox\" soll sich anpassen.\n",
+ "\n",
+ "Tipp: Man kann den Stegosaurus im Editiermodus kopieren, Sie müssen nicht jedes Zeichen selbst abtippen.\n",
"\n",
"\n",
"Freiwillige Erweiterung für Fortgeschrittene: Erweitern Sie die Funktion um ein Argument, mit dem eine maximale Breite (Anzahl Zeichen) übergeben werden kann, so dass die ausgegebene Box nicht breiter ist. Implementieren Sie dann die Behandlung von Zeichenketten, die länger als die vorgegebene Breite sind. Sie haben zwei Möglichkeiten: a) die Zeichenkette abschneiden, b) die Zeichenkette umbrechen. Entscheiden Sie sich für eine der beiden Varianten. Hinweis: auf die ersten `k` Zeichen einer Zeichenkette `s` können Sie mittels `s[0:k]` zugreifen. Analog können Sie auf das 2. bis 4. Zeichen mittels `s[1:4]` zugreifen, usw."
@@ -136,7 +174,25 @@
"execution_count": null,
"metadata": {},
"outputs": [],
- "source": []
+ "source": [
+ "def stegosay():\n",
+ " '''Implementieren Sie hier ihre Funktion. Dieses Kommentar können Sie löschen. \n",
+ " Das/Die Argument/e müssen Sie sich dieses Mal selbst überlegen.\n",
+ " ''' \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Testen Sie hier ihre Funktion; fügen Sie auch eigene Tests hinzu\n",
+ "stegosay(\"Wo bleibt mein Frühstück?\")\n",
+ "stegosay(\"Dieser Text muss auch in die Box passen.\")\n",
+ "stegosay(\"und dieser Text auch..................................................... !\")"
+ ]
},
{
"cell_type": "markdown",
@@ -181,7 +237,7 @@
" *\n",
"```\n",
"Hinweise:\n",
- "- Sie können die Aufgabe auch ohne eine Schleife lösen, aber schöner ist es mit einer Schleife. Sie kennen die Syntax und Semantik der `while`-Schleife schon aus der Vorlesung. Sie funktioniert in Python genau so, wie sie für den Pseudocode definiert wurde. \n",
+ "- Sie können die Aufgabe auch ohne eine Schleife lösen, aber **schöner ist es mit einer Schleife**. Sie kennen die Syntax und Semantik der `while`-Schleife schon aus der Vorlesung. Sie funktioniert in Python genau so, wie sie für den Pseudocode definiert wurde. \n",
"- Sie müssen selbst entscheiden, wieviele Werte Sie im verlangten Intervall berechnen. Die Kurve oben wurde mit einem Rasterabstand von 0.2 berechnet (d.h., für die Werte 0, 0.2, 0.4, 0.6, ..., 6.2). \n",
"- Denken Sie daran, dass Sie mit der `int`-Funktion eine Gleitkommazahl in eine ganze Zahl umwandeln können (der Dezimalanteil wird abgeschnitten).\n",
"- Damit Sie die Funktion `math.sin` nutzen können, müssen Sie anfangs das `math`-Modul importieren."
@@ -194,10 +250,22 @@
"outputs": [],
"source": [
"def sinprint():\n",
- " # Implementieren Sie hier die Funktion sinprint\n",
+ " '''Implementieren Sie hier ihre Funktion. Dieses Kommentar können Sie löschen. \n",
+ " Diese Funktion kann man ohne Argument implementieren. Wenn es für Sie einfacher ist, \n",
+ " können Sie gerne eins hinzufügen.\n",
+ " ''' \n",
"\n",
"\n",
- "sinprint() # Testaufruf"
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Bitte nutzen Sie diese Zelle, um Ihre Funktion zweimal mit verschiedenen Argumenten aufzurufen."
]
},
{
@@ -219,10 +287,22 @@
"metadata": {},
"outputs": [],
"source": [
- "# Implementieren Sie hier die Funktion funcprint\n",
+ "def funcprint():\n",
+ " '''Implementieren Sie hier ihre Funktion. Dieses Kommentar können Sie löschen. \n",
+ " Das/Die Argument/e müssen Sie sich dieses Mal selbst überlegen.\n",
+ " ''' \n",
"\n",
- "# Testen Sie hier die Funktion funcprint\n",
- "funcprint(math.erf)"
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Bitte nutzen Sie diese Zelle, um Ihre Funktion zweimal mit verschiedenen Argumenten aufzurufen."
]
},
{
@@ -243,7 +323,21 @@
"execution_count": null,
"metadata": {},
"outputs": [],
- "source": []
+ "source": [
+ "def funcprint_advanced():\n",
+ " '''Implementieren Sie hier ihre Funktion. Dieses Kommentar können Sie löschen. \n",
+ " Das/Die Argument/e müssen Sie sich dieses Mal selbst überlegen.\n",
+ " ''' "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Bitte nutzen Sie diese Zelle, um Ihre Funktion zweimal mit verschiedenen Argumenten aufzurufen."
+ ]
},
{
"cell_type": "markdown",
diff --git a/notebooks/hausaufgabe2.ipynb b/notebooks/hausaufgabe2.ipynb
index 34ed630d457d684cec72861659d630a42683b0c0..41d7d6939c96039abe7cc0ca83e0b9a0485b4c4c 100644
--- a/notebooks/hausaufgabe2.ipynb
+++ b/notebooks/hausaufgabe2.ipynb
@@ -6,15 +6,22 @@
"source": [
"# 2. Hausaufgabe\n",
"\n",
- "Geben Sie diese Hausaufgabe gemeinsam mit Ihrem/r Partner/in ab. Füllen Sie dazu dieses Notebook aus und speichern Sie es ab (Disketten-Icon oben links). Laden Sie dann die Datei (hausaufgabe2.ipynb) in Moodle hoch. Verwenden Sie Kommentare im Python-Quellcode und Markdown-Textboxen im Jupyter-Notebook ([Syntax-Beispiele](https://de.wikipedia.org/wiki/Markdown#Auszeichnungsbeispiele)) um ihr Programm zu kommentieren.\n",
+ "Geben Sie diese Hausaufgabe gemeinsam mit Ihrem/r Partner/in ab. Füllen Sie dazu dieses Notebook aus und speichern Sie es ab (Disketten-Icon oben links). Laden Sie dann die Datei (hausaufgabe2_nachname1_nachname2.ipynb) in Moodle hoch. Verwenden Sie Kommentare im Python-Quellcode und Markdown-Textboxen im Jupyter-Notebook ([Syntax-Beispiele](https://de.wikipedia.org/wiki/Markdown#Auszeichnungsbeispiele)) um ihr Programm zu kommentieren.\n",
"\n",
"\n",
- "* Geben Sie bitte Ihrem **Notebook einen Namen**, sodass es Ihnen und Ihrem Partner zugeordnet werden kann (z.B. *nachname1_nachname2_hausaufgabe2.ipynb*)\n",
+ "* Geben Sie bitte Ihrem **Notebook einen Namen**, sodass es Ihnen und Ihrem Partner zugeordnet werden kann (z.B. *hausaufgabe2_nachname1_nachname2.ipynb*)\n",
"* Für das Aufwärmen sind in den Seminar-Notebooks schon Musterlösungen gegeben, die nur geringfügig angepasst werden müssen. Falls Sie eine davon nutzen, **ändern Sie zumindest die Namen der Argumente, Literale und Variablen.** \n",
- "* Fügen Sie außerdem **Kommentare ** zu jedem Code hinzu, mit denen Sie erklären, was die Funktion macht (Schleife, Bedingungen, etc. beschreiben). \n",
+ "* Fügen Sie außerdem **Kommentare** zu ihrem Code hinzu, mit denen Sie erklären, was die Funktion macht (Schleife, Bedingungen, etc. beschreiben). Dies kann man durch zwei Varianten machen:\n",
+ " - \\# \n",
+ " - Mit Hilfe der Raute kann ein Kommentar in einem Codeblock stehen, um einzelne Codesgemente zu beschreiben und zu interpretieren\n",
+ " - z.B. : #.B. Kommentar zu einzelnen Code-Segmenten\n",
+ " - ''' '''\n",
+ " - Hier kann ein Kommentar stehen, der die Funktion als Ganzes beschreibt\n",
+ " - z.B. ''' Beschreibung einer Funktion \n",
+ " \n",
"* Schauen Sie sich das notebook **[FAQ.ipynb](FAQ.ipynb)** an, hier sind turtle-Methoden beschrieben, die Sie in dieser Hausaufgabe benötigen. \n",
"* In jedem Codeblock steht eine **Testfunktion**, die am Ende die von Ihnen definierte Funktion aufruft. Dies sollte funktionieren (dort kann man auch direkt ablesen, wieviele und welche Argumente gebraucht werden). Anfangs können Sie den Aufruf gerne auskommentieren, damit nicht immer eine Fehlermeldung angezeigt wird (danach wieder Kommentare entfernen).\n",
- "* Schreiben Sie bitte zu jeder definierten Funktion einen **Funktionsaufruf mit eigens definierten *turtles* und Parametern**.\n",
+ "* Schreiben Sie bitte zu jeder definierten Funktion einen **Funktionsaufruf mit eigens definierten *turtle-Objekten* und Parametern**.\n",
"* Nutzen Sie **Schleifen** in allen Aufgaben, in denen Sie geometrische Figuren zeichnen müssen (Sie haben diese in den Seminaren kennengelernt)!\n",
"\n",
"\n",
diff --git a/notebooks/hausaufgabe3.ipynb b/notebooks/hausaufgabe3.ipynb
index 622b3fff488a0ac146b174e4031847e434dee483..e62c2d19c2eef042cdec496e0efe00dbac5d17d9 100644
--- a/notebooks/hausaufgabe3.ipynb
+++ b/notebooks/hausaufgabe3.ipynb
@@ -8,6 +8,16 @@
"\n",
"Geben Sie diese Hausaufgabe gemeinsam mit Ihrem/r Partner/in ab. Füllen Sie dazu dieses Notebook aus und speichern Sie es ab (Disketten-Icon oben links). Laden Sie dann die Datei (`hausaufgabe3.ipynb`) in Moodle hoch. Verwenden Sie Kommentare im Python-Quellcode und Markdown-Textboxen im Jupyter-Notebook ([Syntax-Beispiele](https://de.wikipedia.org/wiki/Markdown#Auszeichnungsbeispiele)) um ihr Programm zu kommentieren. Für diese Hausaufgabe sollten Sie das 4. bis 6. Kapitel durchgearbeitet haben, da Rekursion, Verzweigungen und Funktionen mit Rückgabewert benötigt werden.\n",
"\n",
+ "\n",
+ "* Geben Sie bitte Ihrem **Notebook einen Namen**, sodass es Ihnen und Ihrem Partner zugeordnet werden kann (z.B. *hausaufgabe2_nachname1_nachname2.ipynb*)\n",
+ "* Fügen Sie außerdem **Kommentare** zu ihrem Code hinzu, mit denen Sie erklären, was die Funktion macht (Schleife, Bedingungen, etc. beschreiben). Dies kann man durch zwei Varianten machen:\n",
+ " - \\# \n",
+ " - Mit Hilfe der Raute kann ein Kommentar in einem Codeblock stehen, um einzelne Codesgemente zu beschreiben und zu interpretieren\n",
+ " - z.B. : # Kommentar zu einzelnen Code-Segmenten\n",
+ " - ''' '''\n",
+ " - Hier kann ein Kommentar stehen, der die Funktion als Ganzes beschreibt\n",
+ " - z.B. ''' Beschreibung einer Funktion '''\n",
+ " \n",
"Wir wünschen viel Erfolg beim Lösen der Aufgaben!\n"
]
},
@@ -33,7 +43,17 @@
"metadata": {},
"outputs": [],
"source": [
- " # Implementieren und testen Sie hier die beiden Funktionen"
+ " # Implementieren Sie hier die beiden Funktionen\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Rufen Sie hier ihre Funktionen auf, um sie zu testen"
]
},
{
@@ -59,7 +79,7 @@
" else:\n",
" recurse(n-1, n+s)\n",
"\n",
- "recurse(3, 0)"
+ "recurse(5, 0)"
]
},
{
@@ -98,11 +118,20 @@
"metadata": {},
"outputs": [],
"source": [
- " # Implementieren und testen Sie hier ihre Funktion\n",
+ " # Implementieren Sie hier ihre Funktion\n",
"\n",
" "
]
},
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Rufen Sie hier ihre Funktionen auf, um sie zu testen"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {},
@@ -261,6 +290,19 @@
"outputs": [],
"source": []
},
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Aufgabe 5 (Zusatz):\n",
+ "\n",
+ "Nutzen Sie Rekursion (falls nicht schon in Hausaufgabe2 benutzt), um Ihre Schildkröte ein Kunstwerk malen zu lassen. Schauen Sie in Notebook 5 nach, um sich inspirieren zu lassen.\n",
+ "\n",
+ "Diese Aufgabe ist freiwillig. \n",
+ "\n",
+ "Sie können gerne wieder kreativ werden."
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {},
diff --git a/notebooks/hausaufgabe4.ipynb b/notebooks/hausaufgabe4.ipynb
index 1db1033bc29ea5d9b8884db6c7a6c80a77e4e5f6..d5bf0adfe07894f497fd3563f550d399b1bb59dc 100644
--- a/notebooks/hausaufgabe4.ipynb
+++ b/notebooks/hausaufgabe4.ipynb
@@ -6,7 +6,16 @@
"source": [
"# 4. Hausaufgabe\n",
"\n",
- "Geben Sie diese Hausaufgabe gemeinsam mit Ihrem/r Partner/in ab. Füllen Sie dazu dieses Notebook aus und speichern Sie es ab (Disketten-Icon oben links). Laden Sie dann die Datei (`hausaufgabe4.ipynb`) in Moodle hoch. Verwenden Sie Kommentare im Python-Quellcode und Markdown-Textboxen im Jupyter-Notebook ([Syntax-Beispiele](https://de.wikipedia.org/wiki/Markdown#Auszeichnungsbeispiele)) um ihr Programm zu kommentieren. Für diese Hausaufgabe sollten Sie alles bis zum 7. Kapitel durchgearbeitet haben, da Iteration, Rekursion, Verzweigungen und Funktionen mit Rückgabewert benötigt werden.\n",
+ "Geben Sie diese Hausaufgabe gemeinsam mit Ihrem/r Partner/in ab. Füllen Sie dazu dieses Notebook aus und speichern Sie es ab (Disketten-Icon oben links). Laden Sie dann die Datei (`hausaufgabe4.ipynb`) in Moodle hoch. Verwenden Sie Kommentare im Python-Quellcode und Markdown-Textboxen im Jupyter-Notebook ([Syntax-Beispiele](https://de.wikipedia.org/wiki/Markdown#Auszeichnungsbeispiele)) um ihr Programm zu kommentieren. Für diese Hausaufgabe sollten Sie alles bis zum 10. Kapitel durchgearbeitet haben, da Iteration, Rekursion, Verzweigungen und Funktionen mit Rückgabewert benötigt werden.\n",
+ "\n",
+ "\n",
+ "- Geben Sie bitte Ihrem Notebook einen Namen, sodass es Ihnen und Ihrem Partner zugeordnet werden kann (z.B. nachname1_nachname2_hausaufgabe2.ipynb)\n",
+ "- Fügen Sie außerdem Kommentare / Docstrings zu jedem Code hinzu, mit denen Sie erklären, was die Funktion macht (Schleife, Bedingungen, etc. beschreiben). **Falls das nicht gemacht wird, wird der Code nicht bewertet.**\n",
+ "- Falls es **Musterlösungen in den Übungen** gibt, können Sie gerne diese Code übernehmen (eigener Code ist natürlich schöner). Falls Sie das machen, muss aber durch ihre Kommentare hervorgehen, dass Sie den Code verstanden haben.\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
"\n",
"Wir wünschen viel Erfolg beim Lösen der Aufgaben!"
]
@@ -17,6 +26,18 @@
"source": [
"## Aufgabe 1\n",
"\n",
+ "Nennen Sie das Thema, was für Sie bis jetzt am schwersten zu verstehen war und nennen Sie einen Vorschlag, wie Sie es einfacher verstanden hätten. \n",
+ "\n",
+ "Beispiel:\n",
+ "Die print()-Funktion habe ich am Anfang überhaupt nicht verstanden. Zwar gab es eine Definition in den Seminarnotebooks, aber das das war zu unverständlich. Ich hätte mir gewünscht, dass Michel die Funktion an der Tafel vorgestellt hätte und uns gezeigt hätte, wie man sie einsetzt."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Aufgabe 2\n",
+ "\n",
"*(Dies ist [Aufgabe 1 im 7. Kapitel](https://scm.cms.hu-berlin.de/ibi/python/blob/master/notebooks/seminar07.ipynb#aufgabe-1).)*\n",
"\n",
"Kopieren Sie die Schleife aus [Abschnitt 7.5](seminar07.ipynb#7.5-Quadratwurzeln) und verkapseln Sie sie in eine Funktion `mysqrt` die einen Parameter `a` erwartet, einen sinnvollen Wert für `x` wählt und eine Näherung für die Quadratwurzel von `a` zurückliefert."
@@ -77,7 +98,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "## Aufgabe 2\n",
+ "## Aufgabe 3\n",
"\n",
"*(Dies ist [Aufgabe 2 im 7. Kapitel](https://scm.cms.hu-berlin.de/ibi/python/blob/master/notebooks/seminar07.ipynb#aufgabe-2).)*\n",
"\n",
@@ -134,7 +155,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "## Aufgabe 3\n",
+ "## Aufgabe 4\n",
"\n",
"Ziel dieser Aufgabe ist, dass Sie üben, fremden Code zu lesen, zu verstehen und zu verändern. \n",
"In [Aufgabe 3 im 7. Kapitel](https://scm.cms.hu-berlin.de/ibi/python/blob/master/notebooks/seminar07.ipynb#aufgabe-3) wird eine Methode zur näherungsweisen Berechnung von $\\pi$ vorgestellt, einschließlich des [Quellcodes](http://thinkpython2.com/code/pi.py). Verändern Sie diesen Quellcode, so dass stattdessen die Näherungsformel \n",
@@ -159,6 +180,81 @@
"print(estimate_pi())"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Aufgabe 5\n",
+ "\n",
+ "Schreiben Sie jeweils eine Funktion, die als Argument eine Zeichenkette erwartet und\n",
+ " - prüft, ob das erste Zeichen der Zeichenkette ein Kleinbuchstaben ist.\n",
+ " - prüft, ob das erste und das letzte Zeichen Kleinbuchstaben sind.\n",
+ " - prüft, ob alle Zeichen der Zeichenkette Zahlen sind.\n",
+ " - alle Zahlen der Zeichenkette ausgibt.\n",
+ " - die Stelle ausgibt, an der eine Zahl gefunden wurde.\n",
+ " \n",
+ " Rufen Sie ihre Funktionen mit verschiedenen Parametern auf, um sie auf Funktionalität zu testen.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Die nachfolgenden Aufgaben können Sie erst lösen, wenn sie das notebook seminar09.ipynb durchgearbeitet haben"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Aufgabe 6 - freiwillig\n",
+ "\n",
+ "Diese Aufgabe basiert auf einem Rätsel welches im Radioprogramm [Car Talk](http://www.cartalk.com/content/puzzlers) gesendet wurde. \n",
+ "\n",
+ "> Gib' mir ein Wort mit zwei aufeinanderfolgenden doppelten Buchstaben. Ich gebe Dir ein paar Wörter, die sich fast dafür qualifizieren (aber nur fast!) - beispielsweise das Wort Kommission, K-o-m-m-i-s-s-i-o-n. Es wäre gut, aber leider hat sich das \"i\" zwischen \"mm\" und \"ss\" eingeschlichen. Oder \"Ballett\" - wenn wir das \"e\" entfernen könnten, würde es klappen. Aber es gibt mindestens ein Wort, welches zwei aufeinanderfolgende Paare von (jeweils gleichen) Buchstaben hat und vielleicht ist es das einzige solche Wort. Welches Wort ist es?\n",
+ "\n",
+ "Schreiben Sie ein Programm, um das Wort zu finden. Die Lösung für englische Wörter (http://thinkpython2.com/code/cartalk1.py) findet sogar Wörter mit drei aufeinanderfolgenden Buchstabenpaaren (die es im Deutschen vermutlich nicht gibt, zumindest nicht in der hier verwendeten Wortliste). "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Implementieren Sie hier das Programm"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Augabe 7 - freiwillig\n",
+ "Ein ähnliches Problem:\n",
+ "\n",
+ "\n",
+ "\n",
+ "[Consecutive Vowels](https://xkcd.com/853/), Randall Munroe\n",
+ "\n",
+ "Schreiben Sie ein Programm, welches das Wort mit den meisten hintereinander auftauchenden Vokalen in unserer Wortliste findet."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Implementieren Sie hier das Programm"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {},
diff --git a/notebooks/pics/string_indices.svg b/notebooks/pics/string_indices.svg
index c5e2f22cc509dbe73ab2be024134c81e09b19a80..1d4b5076b1f43571d1c3c92b2639b7efd88eaff4 100644
--- a/notebooks/pics/string_indices.svg
+++ b/notebooks/pics/string_indices.svg
@@ -14,7 +14,7 @@
viewBox="0 0 90.216782 23.421493"
version="1.1"
id="svg8"
- inkscape:version="0.92.1 r15371"
+ inkscape:version="0.92.2 5c3e80d, 2017-08-06"
sodipodi:docname="string_indices.svg">
<defs
id="defs2">
@@ -62,10 +62,10 @@
inkscape:document-units="mm"
inkscape:current-layer="layer1"
showgrid="false"
- inkscape:window-width="1920"
- inkscape:window-height="1009"
- inkscape:window-x="1024"
- inkscape:window-y="34"
+ inkscape:window-width="1440"
+ inkscape:window-height="855"
+ inkscape:window-x="0"
+ inkscape:window-y="1"
inkscape:window-maximized="1"
fit-margin-top="0"
fit-margin-left="0"
@@ -79,7 +79,7 @@
<dc:format>image/svg+xml</dc:format>
<dc:type
rdf:resource="http://purl.org/dc/dcmitype/StillImage" />
- <dc:title></dc:title>
+ <dc:title />
</cc:Work>
</rdf:RDF>
</metadata>
@@ -97,15 +97,16 @@
y="43.162796" />
<text
xml:space="preserve"
- style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-size:6.53554153px;line-height:100%;font-family:'DejaVu Sans Mono';-inkscape-font-specification:'DejaVu Sans Mono';text-align:center;letter-spacing:0px;word-spacing:0px;writing-mode:lr-tb;text-anchor:middle;fill:#000000;fill-opacity:1;stroke:none;stroke-width:0.54462844px;stroke-linecap:butt;stroke-linejoin:miter;stroke-opacity:1"
- x="77.938126"
- y="54.116028"
- id="text4487"><tspan
+ style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-size:6.85094547px;line-height:100%;font-family:'DejaVu Sans Mono';-inkscape-font-specification:'DejaVu Sans Mono';text-align:center;letter-spacing:0px;word-spacing:0px;writing-mode:lr-tb;text-anchor:middle;fill:#000000;fill-opacity:1;stroke:none;stroke-width:0.57091236px;stroke-linecap:butt;stroke-linejoin:miter;stroke-opacity:1"
+ x="75.100517"
+ y="56.787315"
+ id="text4487"
+ transform="scale(1.0377083,0.96366194)"><tspan
sodipodi:role="line"
id="tspan4485"
- x="77.938126"
- y="54.116028"
- style="font-size:11.61874104px;stroke-width:0.54462844px">"banana"</tspan></text>
+ x="75.100517"
+ y="56.787315"
+ style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-size:12.17945766px;font-family:Arial;-inkscape-font-specification:Arial;stroke-width:0.57091236px">"banana"</tspan></text>
<text
xml:space="preserve"
style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-size:6.53554153px;line-height:100%;font-family:'DejaVu Sans Mono';-inkscape-font-specification:'DejaVu Sans Mono';text-align:center;letter-spacing:0px;word-spacing:0px;writing-mode:lr-tb;text-anchor:middle;fill:#000000;fill-opacity:1;stroke:none;stroke-width:0.54462844px;stroke-linecap:butt;stroke-linejoin:miter;stroke-opacity:1"
@@ -116,7 +117,7 @@
id="tspan4489"
x="27.685129"
y="52.778156"
- style="stroke-width:0.54462844px">fruit</tspan></text>
+ style="stroke-width:0.54462844px;-inkscape-font-specification:Arial;font-family:Arial;font-weight:normal;font-style:normal;font-stretch:normal;font-variant:normal">fruit</tspan></text>
<path
style="fill:none;fill-rule:evenodd;stroke:#000000;stroke-width:0.54548609;stroke-linecap:butt;stroke-linejoin:miter;stroke-miterlimit:4;stroke-dasharray:1.09097222, 0.54548611;stroke-dashoffset:0;stroke-opacity:1"
d="M 56.353885,43.112153 V 61.127172"
@@ -167,7 +168,7 @@
id="tspan4888"
x="33.670418"
y="66.219002"
- style="stroke-width:0.54462844px">Index</tspan></text>
+ style="stroke-width:0.54462844px;-inkscape-font-specification:Arial;font-family:Arial;font-weight:normal;font-style:normal;font-stretch:normal;font-variant:normal">Index</tspan></text>
<text
xml:space="preserve"
style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-size:6.53554153px;line-height:100%;font-family:'DejaVu Sans Mono';-inkscape-font-specification:'DejaVu Sans Mono';text-align:center;letter-spacing:0px;word-spacing:0px;writing-mode:lr-tb;text-anchor:middle;fill:#000000;fill-opacity:1;stroke:none;stroke-width:0.54462844px;stroke-linecap:butt;stroke-linejoin:miter;stroke-opacity:1"
@@ -178,7 +179,7 @@
id="tspan4892"
x="56.425217"
y="66.104126"
- style="stroke-width:0.54462844px">0</tspan></text>
+ style="stroke-width:0.54462844px;-inkscape-font-specification:Arial;font-family:Arial;font-weight:normal;font-style:normal;font-stretch:normal;font-variant:normal">0</tspan></text>
<text
xml:space="preserve"
style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-size:6.53554153px;line-height:100%;font-family:'DejaVu Sans Mono';-inkscape-font-specification:'DejaVu Sans Mono';text-align:center;letter-spacing:0px;word-spacing:0px;writing-mode:lr-tb;text-anchor:middle;fill:#000000;fill-opacity:1;stroke:none;stroke-width:0.54462844px;stroke-linecap:butt;stroke-linejoin:miter;stroke-opacity:1"
@@ -189,7 +190,7 @@
id="tspan4896"
x="63.385426"
y="66.017967"
- style="stroke-width:0.54462844px">1</tspan></text>
+ style="stroke-width:0.54462844px;-inkscape-font-specification:Arial;font-family:Arial;font-weight:normal;font-style:normal;font-stretch:normal;font-variant:normal">1</tspan></text>
<text
xml:space="preserve"
style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-size:6.53554153px;line-height:100%;font-family:'DejaVu Sans Mono';-inkscape-font-specification:'DejaVu Sans Mono';text-align:center;letter-spacing:0px;word-spacing:0px;writing-mode:lr-tb;text-anchor:middle;fill:#000000;fill-opacity:1;stroke:none;stroke-width:0.54462844px;stroke-linecap:butt;stroke-linejoin:miter;stroke-opacity:1"
@@ -200,7 +201,7 @@
id="tspan4900"
x="70.722176"
y="66.104126"
- style="stroke-width:0.54462844px">2</tspan></text>
+ style="stroke-width:0.54462844px;-inkscape-font-specification:Arial;font-family:Arial;font-weight:normal;font-style:normal;font-stretch:normal;font-variant:normal">2</tspan></text>
<text
xml:space="preserve"
style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-size:6.53554153px;line-height:100%;font-family:'DejaVu Sans Mono';-inkscape-font-specification:'DejaVu Sans Mono';text-align:center;letter-spacing:0px;word-spacing:0px;writing-mode:lr-tb;text-anchor:middle;fill:#000000;fill-opacity:1;stroke:none;stroke-width:0.54462844px;stroke-linecap:butt;stroke-linejoin:miter;stroke-opacity:1"
@@ -211,7 +212,7 @@
id="tspan4904"
x="77.845131"
y="66.104126"
- style="stroke-width:0.54462844px">3</tspan></text>
+ style="stroke-width:0.54462844px;-inkscape-font-specification:Arial;font-family:Arial;font-weight:normal;font-style:normal;font-stretch:normal;font-variant:normal">3</tspan></text>
<text
xml:space="preserve"
style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-size:6.53554153px;line-height:100%;font-family:'DejaVu Sans Mono';-inkscape-font-specification:'DejaVu Sans Mono';text-align:center;letter-spacing:0px;word-spacing:0px;writing-mode:lr-tb;text-anchor:middle;fill:#000000;fill-opacity:1;stroke:none;stroke-width:0.54462844px;stroke-linecap:butt;stroke-linejoin:miter;stroke-opacity:1"
@@ -222,7 +223,7 @@
id="tspan4908"
x="84.942558"
y="66.017967"
- style="stroke-width:0.54462844px">4</tspan></text>
+ style="stroke-width:0.54462844px;-inkscape-font-specification:Arial;font-family:Arial;font-weight:normal;font-style:normal;font-stretch:normal;font-variant:normal">4</tspan></text>
<text
xml:space="preserve"
style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-size:6.53554153px;line-height:100%;font-family:'DejaVu Sans Mono';-inkscape-font-specification:'DejaVu Sans Mono';text-align:center;letter-spacing:0px;word-spacing:0px;writing-mode:lr-tb;text-anchor:middle;fill:#000000;fill-opacity:1;stroke:none;stroke-width:0.54462844px;stroke-linecap:butt;stroke-linejoin:miter;stroke-opacity:1"
@@ -233,7 +234,7 @@
id="tspan4912"
x="92.113373"
y="66.017967"
- style="stroke-width:0.54462844px">5</tspan></text>
+ style="stroke-width:0.54462844px;-inkscape-font-specification:arial;font-family:arial;font-weight:normal;font-style:normal;font-stretch:normal;font-variant:normal">5</tspan></text>
<text
xml:space="preserve"
style="font-style:normal;font-variant:normal;font-weight:normal;font-stretch:normal;font-size:6.53554153px;line-height:100%;font-family:'DejaVu Sans Mono';-inkscape-font-specification:'DejaVu Sans Mono';text-align:center;letter-spacing:0px;word-spacing:0px;writing-mode:lr-tb;text-anchor:middle;fill:#000000;fill-opacity:1;stroke:none;stroke-width:0.54462844px;stroke-linecap:butt;stroke-linejoin:miter;stroke-opacity:1"
@@ -244,6 +245,6 @@
id="tspan4916"
x="99.2108"
y="66.104126"
- style="stroke-width:0.54462844px">6</tspan></text>
+ style="stroke-width:0.54462844px;-inkscape-font-specification:Arial;font-family:Arial;font-weight:normal;font-style:normal;font-stretch:normal;font-variant:normal">6</tspan></text>
</g>
</svg>
diff --git "a/notebooks/programmierspa\303\237_spiele.ipynb" "b/notebooks/programmierspa\303\237_spiele.ipynb"
new file mode 100644
index 0000000000000000000000000000000000000000..cbe2c4afdb4159d28348447459c903a63b305810
--- /dev/null
+++ "b/notebooks/programmierspa\303\237_spiele.ipynb"
@@ -0,0 +1,178 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Einführungsaufgaben\n",
+ "\n",
+ "## neue Bibliothek\n",
+ "### nb_black \n",
+ "- Installation (Terminal / Anaconda prompt): <code>$ [sudo] pip install nb_black </code>\n",
+ "- https://github.com/dnanhkhoa/nb_black\n",
+ "- uncompromising Python code formatter\n",
+ "- makes code review faster\n",
+ "- Apply by putting this code <code>%load_ext nb_black </code> into the first cell in your Notebook, run it and that's all :)\n",
+ "- based on black\n",
+ " - https://pypi.org/project/black/\n",
+ " - for \"normal\" python scripts\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%load_ext nb_black"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Würfeln\n",
+ "\n",
+ "\n",
+ "1. Erstelle eine Funktion <code>dice</code>, die einen Würfel x-mal würfelt. (x soll die Eingabe der Funktion sein). \n",
+ "2. Gebe eine Statistik aus, wie oft welcher Wert gewürfelt wurde.\n",
+ " - Tipp: Nutze die Bibliothek random, um zufällige Werte zu generieren.\n",
+ " - Tipp: Nutze Schleifen (while, for)\n",
+ "3. Verkürze deinen Code durch List Comprehension "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def dice(x):\n",
+ " \"\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Codetest\n",
+ "dice(1000000)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Schere, Stein, Papier\n",
+ "\n",
+ "1. Erstelle ein Schere-Stein-Papier-Spiel, der eine Eingabe (durch <code> input() </code>) von dir entgegennimmt und den Computer eine zufällige Antwort generieren lässt. Anschließend soll die Funktion ausgeben, wer gewonnen hat.\n",
+ " - Nutze Schleifen (for, while)\n",
+ " - Bedingungen (if-statements)\n",
+ " - Nutze die Bibliothek random\n",
+ " - Akzeptiere Groß-und Kleinschreibung"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def ssp():\n",
+ " \"\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ssp()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Plotten\n",
+ "\n",
+ "1. Plotte eine sinus und eine cosinus Kurve. \n",
+ " - Nutze die Bibliothek numpy, um die sinus und cosinus Funktion zu benutzen\n",
+ " - Nutze die Bibliothek matplotlib, um die Kurven zu zeichnen\n",
+ "2. Gebe dem Plot eine Überschrift, Achsenbeschriftungen, Einschränkungen der x-Achse (-360° bis 360°) und eine Legende."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Hangman\n",
+ "\n",
+ "\n",
+ "\n",
+ "1. Erstelle ein Hangman-Spiel in mehreren Schritten (https://de.wikipedia.org/wiki/Galgenm%C3%A4nnchen). Die nächsten Schritte sind Tipps, wie ihr vorgehen könnt. Das ist nur eine von vielen Möglichkeiten. Probiert es selbst aus, ihr könnt gerne auch einen anderen Weg gehen.\n",
+ "2. Erstelle eine Funktion, die zwei Strings entgegennimmt und alle Indizes wiedergibt, an denen der erste String im zweiten String erscheint. \n",
+ " - Nutze die Bibliothek <code>re</code> und ggf. die Funktion <code>finditer</code> (Man kann die Ausgabe von <code>finditer</code> durchlaufen und durch <code>start()</code> auf den Index zugreifen. Siehe auch die Dokumentation und Beispiele im Internet) \n",
+ " \n",
+ "3. Anschließend erweitere die Funktion, sodass die Funktion nur noch das Wort entgegennimmt und du per Eingabe (<code>input()</code>) nacheinander mehrere Buchstaben eingeben kannst (z.B. per Schleife, siehe -> <code>while true:</code>). Auch hier sollen wieder alle Indizes ausgegeben werden, an denen die einzelnen Buchstaben im Wort erscheinen.\n",
+ "4. Erstelle zunächst eine Bedingung, die checkt, ob der Buchstabe im Wort vorkommt. Falls ja, gebe den Buchstaben aus. Wenn nein, gebe bitte eine Nachricht aus, dass die Eingabe falsch war.\n",
+ "5. Was brauchen wir noch? In jedem Schritt die Ausgabe von dem unvollständigen Wort mit den schon gefundenen Buchstaben. \n",
+ " - eine Liste mit sovielen Elementen, wie es Buchstaben im Wort gibt. Jedes Element ist ein Minus oder Unterstrich\n",
+ " - Erweitere die Bedingung aus 4), indem du in der Liste das Element mit dem zur Zeit eingegebenen Buchstaben ersetzt\n",
+ "6. Jetzt brauchen wir noch Abbruchbedingungen in der Schleife durch <code>return</code>. Wo müssen diese hin? \n",
+ "7. Wir können jetzt durch einen Counter die Anzahl der Versuche limitieren. (zusätzliche Bedingung?)\n",
+ "8. Ein Willkommenstext wäre außerdem schön.\n",
+ "9. Anstatt eines Wortes soll die Funktion nun eine Liste von Wörtern entgegennehmen und zufällig eins aussuchen, um das gespielt wird. Dann weißt du auch nicht mehr, welches dran ist.\n",
+ "10. Anzahl der Fehlversuche variabel setzen (z.B. bei jedem neuen Spiel einsetzbar, verschiedene Schwierigkeitsstufen, abhängig von der Länge des Wortes, etc.)\n",
+ "11. Ein Hangman-Bild bei jedem Fehlversuch anzeigen und jedes Mal erweitern.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# hier ist ein Bild, was ihr theoretisch zur Visualisierung nehmen könnt.\n",
+ "# Ihr könnt euch aber auch ein eigenes ausdenken. Vielleicht gibt es coolere.\n",
+ "hangman = \"\"\" \n",
+ "\n",
+ " ______\n",
+ " | |\n",
+ " o |\n",
+ " \\|/ |\n",
+ " | |\n",
+ " / \\ | \n",
+ " / \\ \n",
+ "\"\"\"\n",
+ "print(hangman)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "name": "python",
+ "pygments_lexer": "ipython3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/notebooks/recap.ipynb b/notebooks/recap.ipynb
new file mode 100644
index 0000000000000000000000000000000000000000..84959d78d8f5199b7def5dd1ff0868f2c829e840
--- /dev/null
+++ b/notebooks/recap.ipynb
@@ -0,0 +1,778 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Python Grundlagen\n",
+ "- Dynamisch typisierte Sprache\n",
+ "- Statt geschweifter Klammern für Codeblöcke (Funktionen, Schleifen) wird Code mit vier Leerzeichen (pro Hierarchieebene) eingerückt\n",
+ "- Die meisten Editoren ersetzen Tab automatisch durch vier Leerzeichen\n",
+ "- Kommentare beginnen mit Raute #"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Krasse neue Bibliothek\n",
+ "\n",
+ "Formatiert euren Code nach jeder Ausführung\n",
+ "\n",
+ "- für \"normale\" python scripte: **black**\n",
+ "\n",
+ "- für jupyter notebooks: **nb_black**\n",
+ "\n",
+ "- Installation: *pip install nb_black*\n",
+ "\n",
+ "- Ausführung: Einfach **%load_ext nb_black** in einem Codeblock einmalig ausführen"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%load_ext nb_black"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Grundlegende Datentypen\n",
+ "Zahlentypen (int/float) sind größtenteils äquivalent zu Java. Strings können mit doppelten oder einfachen Anführungszeichen deklariert werden."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "a = 2 * 2.0\n",
+ "b = 5\n",
+ "\n",
+ "print(a + b)\n",
+ "print(type(a))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "a += 1\n",
+ "# ist kurz für\n",
+ "a = a + 1\n",
+ "# a++ existiert nicht\n",
+ "\n",
+ "print(a)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "2 ** 4 # Potenzen"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "2 / 4 # Brüche"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "text1 = \"Hallo \"\n",
+ "text2 = \"Welt\"\n",
+ "\n",
+ "print(text1 + text2)\n",
+ "\n",
+ "# Andere Datentypen müssen explizit in Strings konvertiert werden,\n",
+ "# wenn sie an einen String angehängt werden sollen.\n",
+ "print(text1 + str(1))\n",
+ "# ansonsten muss per Komma getrennt werden\n",
+ "print(text1, 1)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "float(\"1\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "float(1)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "*None* entspricht *null* in Java."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "myvar = None"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(myvar)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if myvar is None:\n",
+ " print(\"x ist nicht definiert\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Listen\n",
+ "Listen werden mit eckigen Klammern oder list() initialisiert."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "l1 = []\n",
+ "l = [1, 2, 3, 3]\n",
+ "l.append(4)\n",
+ "\n",
+ "print(l1)\n",
+ "print(l)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Vorsicht bei der Kombination von Listen. append hängt die übergebene Variable als einzelnen Listeneintrag an die Liste an."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "l.append([5, 6])\n",
+ "\n",
+ "print(l)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Zur Kombination von zwei Listen wird der +-Operator verwendet."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "l2 = l + [5, 6]\n",
+ "\n",
+ "print(l2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Mengen\n",
+ "Mengen können mit geschweiften Klammern oder set() initialisiert werden."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "s = {1, 2, 3, 3}\n",
+ "s2 = set([2, 3, 4, 5])\n",
+ "\n",
+ "print(s)\n",
+ "print(s.intersection(s2))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "s.add(9)\n",
+ "s.remove(2)\n",
+ "s"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Mit list() und set() können die Typen auch ineinander konvertiert werden."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "list(s)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "set([1, 2, 3])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Ranges\n",
+ "Auflistung von Zahlen, werden z.Bsp. für for-Schleifen mit Index verwendet."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for i in range(5):\n",
+ " print(i)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Tupel\n",
+ "Für sortierete Werte mit fester Komponentenanzahl und fester Bedeutung für jeden Eintrag."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "essen = \"Chili\"\n",
+ "preis = 2.51\n",
+ "boneintrag = (essen, preis)\n",
+ "\n",
+ "print(boneintrag)\n",
+ "print(boneintrag[0])\n",
+ "print(boneintrag[1])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "(essen2, preis2) = boneintrag\n",
+ "\n",
+ "print(essen2)\n",
+ "print(preis2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Klammern können oft weggelassen werden"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "boneintrag = essen, preis\n",
+ "essen2, preis2 = boneintrag\n",
+ "\n",
+ "print(boneintrag)\n",
+ "print(essen2)\n",
+ "print(preis2)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Dictionaries\n",
+ "Äquivalent zu Maps."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "d = {\"Chili\": 1.90, \"Penne\": 2.50}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "d.keys()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "d.values()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for key, val in d.items():\n",
+ " print(\"{}: {}\".format(key, val))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "d[\"Chili\"]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "d[\"Burger\"] = 4.90\n",
+ "d"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "del d[\"Burger\"]\n",
+ "d"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## If-Anweisungen"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if 2 > 1 or 1 > 2:\n",
+ " print(\"Bedingung erfüllt.\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "y = 10\n",
+ "x = 5 if y > 10 else 4\n",
+ "\n",
+ "print(x)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Schleifen"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "x = 5\n",
+ "while x > 0:\n",
+ " x -= 1\n",
+ "x"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for x in [\"a\", \"b\", \"c\"]:\n",
+ " print(x)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Funktionen"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def sum_upto(n):\n",
+ " return n * (n + 1) / 2\n",
+ "\n",
+ "\n",
+ "sum_upto(4)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Zur besseren Übersicht (insbesondere bei vielen Parametern) können diese auch namentlich zugewiesen werden."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sum_upto(n=4)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Funktionen können *Default-Parameter* haben, d.h. Werte, die von der Funktion als Standardwert verwendet werden (wenn kein anderer Wert übergeben wird). Default-Parameter müssen am Ende der Funktion stehen und übergeben werden."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def fun_with_default(x=3):\n",
+ " print(\"Parameter is {}\".format(x))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fun_with_default()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fun_with_default(x=4)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Funktionen können wie Variablen referenziert werden (Pointer auf die Funktion) und zum Beispiel als Parameter übergeben werden."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def calc_and_print(calc_function, n):\n",
+ " calc_result = calc_function(n)\n",
+ " print(calc_result)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "calc_and_print(sum_upto, 4)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Lambda-Funktionen\n",
+ "I.d.R. für Inline-Funktionen. Können zum Beispiel an Funktionen als Parameter übergeben oder als Variable deklariert werden. Lambdas enthalten ein einzelnes Statement, dessen Wert automatisch der Rückgabewert ist."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "calc_square = lambda x: x ** 2\n",
+ "calc_square(3)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "calc_and_print(calc_square, 4)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "calc_and_print(lambda x: x ** 3, 4)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## List Comprehensions"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "y = [x ** 2 for x in range(10)]\n",
+ "y"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "xy = [(x, x ** 2) for x in range(10) if x % 2 == 0]\n",
+ "xy"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Klassen\n",
+ "Objekte einer Klasse bekommen bei Methodenaufrufen als ersten Parameter automatisch das *\"self\"*-Objekt übergeben (vgl. *this* in Java). Dieser Parameter muss also immer auch als erster Parameter einer Klassenmethode übergeben werden. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class Vehicle:\n",
+ " # Constructor\n",
+ " def __init__(self, n_wheels=4, noise=\"beep\"):\n",
+ " self.n_wheels = n_wheels\n",
+ " self.noise = noise\n",
+ "\n",
+ " def make_noise(self):\n",
+ " print(self.noise)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "basicVehicle = Vehicle()\n",
+ "basicVehicle.make_noise()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Properties sind immer von außen sichtbar und lassen sich verändern. Properties, die nicht zur Veränderung gedacht sind, werden nach Konvention durch zwei Unterstriche im Namen gekennzeichnet."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "basicVehicle.n_wheels"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Vererbung ist in Python möglich. In der Regel wird aber Duck-Typing verwendet. \n",
+ "\n",
+ "“When I see a bird that walks like a duck and swims like a duck and quacks like a duck, I call that bird a duck.â€"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "bike = Vehicle(n_wheels=2, noise=\"ring\")\n",
+ "bike.make_noise()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class Bike(Vehicle):\n",
+ " def __init__(self):\n",
+ " self.n_wheels = 2\n",
+ " self.noise = \"ring\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "Bike().make_noise()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Jupyter Notebook Grundlagen\n",
+ "- Notebook besteht aus Zellen\n",
+ "- Unter der Zelle wird der Rückgabewert des letzten Statements ausgegeben\n",
+ "- Quellcode kann auf mehrere Zellen aufgeteilt werden (Variablen behalten ihre Gültigkeit/Sichtbarkeit)\n",
+ "- Variablen sind auch nach dem Löschen von Zellen weiter sichtbar. Um den Speicher zu bereinigen *Kernel -> Restart*"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Shortcuts\n",
+ "Ãœbersicht: *Help -> Keyboard Shortcuts*\n",
+ "- *Enter*: Editiermodus für selektierte Zelle (grün)\n",
+ "- *Esc*: Editiermodus verlassen/Kommandomodus (blau)\n",
+ "- *Shift+Strg*: Selektierte Zelle ausführen\n",
+ "- *Shift+Enter*: Selektierte Zelle ausführen und in nächste Zelle springen\n",
+ "\n",
+ "Im Editiermodus:\n",
+ "- Tab: Autocomplete oder Einrücken\n",
+ "\n",
+ "Im Kommandomodus:\n",
+ "- *B*: Zelle darunter einfügen\n",
+ "- *A*: Zelle darüber einfügen\n",
+ "- *DD*: Zelle löschen\n",
+ "- *M*: Zelltyp Markdown (für formatierte beschreibende Texte)\n",
+ "- *Y*: Zelltyp Code (Default)"
+ ]
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "name": "python",
+ "pygments_lexer": "ipython3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/notebooks/seminar00.ipynb b/notebooks/seminar00.ipynb
index d1e9b895645b994eb044860726bfd368b0b4ff4d..e90d467d021a221eb9d23fb010278266330d65cd 100644
--- a/notebooks/seminar00.ipynb
+++ b/notebooks/seminar00.ipynb
@@ -6,11 +6,29 @@
"source": [
"# Seminar Problemorientierte Programmierung\n",
"\n",
- "Diese Notebooks sind im Wesentlichen eine Ãœbersetzung der 2. Ausgabe des Buches \"Think Python\" von Allen B. Downey. Sie finden den originalen Text hier: http://greenteapress.com/wp/think-python-2e/.\n",
+ "Falls Sie im Python Programmierkurs sind und dies ihr erstes geöffnetes Jupyter Notebook ist: \n",
+ "\n",
+ "**Herzlichen Glückwunsch! Sie haben die erste Hürde gemeistert. :)**\n",
+ "\n",
+ "Diese Notebooks sind im Wesentlichen eine Ãœbersetzung der 2. Ausgabe des Buches \"Think Python\" von Allen B. Downey. Sie finden den originalen Text [hier](http://greenteapress.com/wp/think-python-2e/).\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "<h1>Table of Contents<span class=\"tocSkip\"></span></h1>\n",
+ "<div class=\"toc\"><ul class=\"toc-item\"><li><span><a href=\"#Lernziele-und-Ablauf-diese-Seminars\" data-toc-modified-id=\"Lernziele-und-Ablauf-diese-Seminars-1\"><span class=\"toc-item-num\">1 </span>Lernziele und Ablauf diese Seminars</a></span></li><li><span><a href=\"#Tipps\" data-toc-modified-id=\"Tipps-2\"><span class=\"toc-item-num\">2 </span>Tipps</a></span></li><li><span><a href=\"#Wiederkehrende-Abschnitte\" data-toc-modified-id=\"Wiederkehrende-Abschnitte-3\"><span class=\"toc-item-num\">3 </span>Wiederkehrende Abschnitte</a></span></li><li><span><a href=\"#Hinweise-zur-Benutzung-von-Jupyter\" data-toc-modified-id=\"Hinweise-zur-Benutzung-von-Jupyter-4\"><span class=\"toc-item-num\">4 </span>Hinweise zur Benutzung von Jupyter</a></span><ul class=\"toc-item\"><li><span><a href=\"#Jupyter-Notebook-Grundlagen-und-Informationen\" data-toc-modified-id=\"Jupyter-Notebook-Grundlagen-und-Informationen-4.1\"><span class=\"toc-item-num\">4.1 </span>Jupyter Notebook Grundlagen und Informationen</a></span></li><li><span><a href=\"#Standardbrowser\" data-toc-modified-id=\"Standardbrowser-4.2\"><span class=\"toc-item-num\">4.2 </span>Standardbrowser</a></span><ul class=\"toc-item\"><li><span><a href=\"#Anleitungen\" data-toc-modified-id=\"Anleitungen-4.2.1\"><span class=\"toc-item-num\">4.2.1 </span>Anleitungen</a></span></li></ul></li><li><span><a href=\"#Shortcuts\" data-toc-modified-id=\"Shortcuts-4.3\"><span class=\"toc-item-num\">4.3 </span>Shortcuts</a></span><ul class=\"toc-item\"><li><span><a href=\"#Beispiel:-Markdown-Zelle-vs.-Code-Zelle\" data-toc-modified-id=\"Beispiel:-Markdown-Zelle-vs.-Code-Zelle-4.3.1\"><span class=\"toc-item-num\">4.3.1 </span>Beispiel: Markdown Zelle vs. Code Zelle</a></span></li></ul></li></ul></li><li><span><a href=\"#Exkurs:-Was-mir-an-Python-gefällt:\" data-toc-modified-id=\"Exkurs:-Was-mir-an-Python-gefällt:-5\"><span class=\"toc-item-num\">5 </span>Exkurs: Was mir an Python gefällt:</a></span></li></ul></div>"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
"\n",
"## Lernziele und Ablauf diese Seminars\n",
"\n",
- "Unser Lernziel ist, dass Sie Programmieren lernen (mit Python :-). Bis dahin ist es ein weiter Weg. Der beste Tipp ist: üben, üben, üben.\n",
+ "Unser Lernziel ist, dass Sie Programmieren lernen (mit Python :-)). Bis dahin ist es ein weiter Weg. Der beste Tipp ist: üben, üben, üben.\n",
"\n",
"Das Seminar wird wie folgt ablaufen:\n",
"\n",
@@ -29,26 +47,138 @@
" - Denken Sie daran, alle Code-Blöcke auszuführen. \"Unbekannter\" Code führt in Jupyter häufig zu leicht vermeidbaren Fehlern.\n",
" - Falls Sie mal nicht weiterkommen: helfen Sie sich gegenseitig und versuchen Sie verschiedene Dinge. Schreiben Sie Ihr Problem z.B. einfach mal ganz genau hier im Notebook auf. Oft hilft das Aufschreiben eines Problems schon bei der Lösung eines Problems.\n",
"\n",
- "## Wiederkehrende Abschnitte:\n",
+ "## Wiederkehrende Abschnitte\n",
"\n",
" - **Exkurse** sind Material, welches Sie sich nur anschauen brauchen, falls es Sie interessiert. Bitte schauen Sie sich die Exkurse eher zu Hause an, als während des Seminars, damit Sie vorwärts kommen. Die Inhalte der Exkurse sind nicht notwendig, um vorwärts zu kommen, aber hilfreich, um mehr zu lernen.\n",
" - **Debugging-Abschnitte** erklären, wie Sie Fehler finden und beheben können.\n",
" - **Glossar-Abschnitte** listen die Begriffe auf, die im Kapitel vermittelt wurden. Es ist eine gute Übung für zu Hause, jeden Begriff dort noch einmal in eigenen Worten zu definieren.\n",
- " - Schließlich gibt es **Übungen**, diese sollten Sie unbedingt durchführen und erst fortfahren, wenn Sie die Aufgaben lösen konnten und verstanden haben.\n",
+ " - Schließlich gibt es **Übungen**, diese sollten Sie unbedingt durchführen und erst fortfahren, wenn Sie die Aufgaben lösen konnten und verstanden haben."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
" \n",
"## Hinweise zur Benutzung von Jupyter\n",
"\n",
- " - Sie kommen deutlich schneller vorwärts, wenn Sie Tastaturkürzel nutzen (und nicht die Maus). Im \"Help\"-Menü gibt es dazu den \"Keyboard Shortcuts\"-Eintrag. Sie können aber auch einfach die Tastenkombination `ESC h` drücken (das bedeutet: die `ESC`-Taste drücken und dann die Taste h). Wichtigste Kombinationen: `ESC b` fügt einen neuen Block ein, `STRG-ENTER` (oder `STRG-RETURN`, also `STRG` gedrückt halten und dann `RETURN` drücken) führt den aktuellen Block aus, `ESC m` ändert den Typ des aktuellen Blocks auf Markdown (und `ESC y` zu Python), usw.\n",
- " - Alternativ können Sie auch die Knöpfe oben mit der Maus bedienen.\n",
- " - Es gibt zwei Arten von Blöcken: \"Code\" ist für Python-Code, \"Markdown\" ist für Texte, die Sie mit Hilfe der [Markdown-Syntax](https://de.wikipedia.org/wiki/Markdown#Auszeichnungsbeispiele) formatieren können.\n",
- " - Sie können auf Text doppelt klicken, um sich den Markdown-Quellcode anzuzeigen. Probieren Sie es mit diesem Text aus.\n",
- " - Wenn Sie mal etwas \"kaputtgespielt\" haben, hilft es evtl., im \"Kernel\"-Menü den \"Restart\"-Eintrag auszuwählen.\n",
- " - Mit der Funktion help können Sie in Python zu vielen Funktionen Hilfe erhalten. Die offizielle Python-Dokumentation finden Sie hier: https://docs.python.org/3/.\n",
+ "### Jupyter Notebook Grundlagen und Informationen\n",
+ "\n",
+ "- open-source, browserbasiertes Tool für verschiedene Programmiersprachen (wir benutzen Python)\n",
+ "- **Vorteil**: Code, Visualisierungen und Text / Erklärungen in einem Dokument\n",
+ "- Notebook besteht aus Blöcken bzw. Zellen\n",
+ "- Unter der Zelle wird der Rückgabewert des letzten Statements ausgegeben\n",
+ "- Quellcode kann auf mehrere Blöcke aufgeteilt werden (Variablen behalten ihre Gültigkeit/Sichtbarkeit)\n",
+ "- Es gibt zwei Arten von Blöcken: \"Code\" ist für Python-Code, \"Markdown\" ist für Texte, die Sie mit Hilfe der [Markdown-Syntax](https://de.wikipedia.org/wiki/Markdown#Auszeichnungsbeispiele) formatieren können.\n",
+ "- Sie können auf Text doppelt klicken, um sich den Markdown-Quellcode anzuzeigen. Probieren Sie es mit diesem Text aus.\n",
+ "- durch die Tastenkombination \"Strg\" und \"Enter\" oder durch Drücken von dem \"Run\" Button oben im Menü kommen Sie wieder in den Lesemodus \n",
+ "- Wenn Sie mal etwas \"kaputtgespielt\" haben, hilft es evtl., im \"Kernel\"-Menü den \"Restart\"-Eintrag auszuwählen.\n",
+ "\n",
+ "### Standardbrowser\n",
+ "\n",
+ "Bitte verwenden Sie **nicht** Safari oder Internet Explorer. Auch mit Windows Edge gab es in der Vergangenheit Probleme. Wir empfehlen die Verwendung von Firefox, aber auch Google Chrome lief in der Vergangenheit problemlos. Wenn Sie unsicher sind, was ihr aktueller Standardbrowser ist, folgen Sie einfach der folgenden Anleitung zum Ändern des Standardbrowsers und gehen Sie sicher, dass der richtige Standardbrowser ausgewählt ist.\n",
+ "\n",
+ "#### Anleitungen\n",
+ "\n",
+ "**Änderung des Standardbrowsers in...** \n",
+ "\n",
+ "*macOS:* \n",
+ "1. Öffnen sie die Systemeinstellungen.\n",
+ "2. Klicken Sie auf „Allgemein“.\n",
+ "3. Wählen Sie unter „Standard-Webbrowser“ den gewünschten Browser aus.\n",
+ "\n",
+ "*Ubuntu Linux:* \n",
+ "1. Öffnen Sie die System Settings.\n",
+ "2. Klicken Sie auf „Applications“.\n",
+ "3. Wählen Sie in der linken Spalte „Default Applications“ aus.\n",
+ "4. Klicken Sie in der Spalte rechts davon auf „Web Browser“.\n",
+ "5. Wählen Sie „in the following browser:“ aus.\n",
+ "6. Wählen Sie den gewünschten Browser aus.\n",
+ "\n",
+ "*Windows:* \n",
+ "1. Öffnen Sie die Systemsteuerung.\n",
+ "2. Klicken Sie auf „Standardprogramme“.\n",
+ "3. Klicken Sie auf „Standardprogramme festlegen“.\n",
+ "4. Klicken Sie in der Liste auf den gewünschten Browser.\n",
+ "5. Klicken Sie dann auf „Dieses Programm als Standard festlegen“.\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Shortcuts\n",
+ "\n",
+ "**Bitte probieren Sie alle unten stehenden Befehle und verstehen Sie, was gemacht wird. Das ist die Basis, die Sie für das Arbeiten mit Jupyter Notebooks brauchen.**\n",
+ "\n",
+ "Übersicht: *Menü Help -> Keyboard Shortcuts*\n",
+ "\n",
+ "Wichtigste Shortcuts: \n",
+ "\n",
+ "- *Enter*: Editiermodus für selektierte Zelle (grün umrandet)\n",
+ "- *Esc*: Editiermodus verlassen/Kommandomodus (blau umrandet)\n",
+ "- *Strg + Enter*: Selektierte Zelle ausführen\n",
+ "- *Shift + Enter*: Selektierte Zelle ausführen und in nächste Zelle springen\n",
"\n",
+ "Im Editiermodus:\n",
+ "- *Tab*: Autocomplete oder Einrücken\n",
+ "- *Shift + Tab*: Einrücken rückwärts\n",
+ "\n",
+ "Im Kommando-/Lesemodus:\n",
+ "- *B*: Zelle darunter einfügen\n",
+ "- *A*: Zelle darüber einfügen\n",
+ "- *DD*: Zelle löschen\n",
+ "- *M*: Zelltyp Markdown (für formatierte beschreibende Texte, zB diese Zelle)\n",
+ "- *Y*: Zelltyp Code (Default)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Beispiel: Markdown Zelle vs. Code Zelle"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Dies ist eine **Markdown Zelle**. Hier kann jeglicher Text geschrieben werden. Durch Strg+Enter wird er in den Lesemodus gebracht, durch ein einfach Enter (oder Doppelklick) in den Editiermodus.\n",
+ "\n",
+ "Hier werden keine Rechnungen ausgeführt, siehe:\n",
+ "\n",
+ "5+3\n",
+ "\n",
+ "In diesen Feldern werden Erklärungen, Aufgabenstellungen und schriftliche Antworten von euch stehen."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Das ist eine **Code Zelle**, bei Strg+Enter wird die folgende Rechnung ausgeführt und darunter angezeigt\n",
+ "# Mit Enter kommt man in den Editiermodus, mit Strg+Enter wird der Code ausgeführt.\n",
+ "# Der Text kann hier nur stehen, da eine Raute am Anfang der Zeile steht. \n",
+ "# Dadurch werden diese Zeilen nicht ausgeführt.\n",
+ "\n",
+ "31+11\n",
+ "\n",
+ "# In diesen Zellen wird der Python Code geschrieben, manchmal müssen Sie ihn schreiben, \n",
+ "# manchmal steht der Code schon dort und muss von Ihnen nur ausgeführt werden."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
"## Exkurs: Was mir an Python gefällt:\n",
"\n",
"In dieser Rubrik, die normalerweise am Anfang eines Kapitels steht, möchte ich Ihnen zeigen, wofür ich Python nutze und warum ich es mag. Sie werden vielleicht noch nicht verstehen, was ich genau mache, aber Sie sehen damit schon einmal die Möglichkeiten von Python und können später darauf zurückgreifen. Da dies ein Exkurs ist, können Sie diese Rubrik gerne auch erst einmal überspringen.\n",
"\n",
+ "**Hier müssen Sie den Code NIE verändern. Einfach Ausführen durch: *Strg+Enter* oder im Menü unter *> Run*.** \n",
+ "*Sollten Sie den Code doch einmal versehentlich verändert haben, sodass der Exkurs nicht mehr korrekt funktioniert, können Sie das Jupyter-Notebook erneut in Gitlab herunterladen*\n",
+ "\n",
+ "\n",
"Ich finde toll, dass ich mit Python ganz einfach Zufallsexperimente durchtesten kann. Das hilft mir, Stochastik besser zu verstehen. Z.B. das Würfeln mit zwei Würfeln:"
]
},
@@ -63,7 +193,7 @@
"# Werte initialisieren, größter möglicher Wert bei zwei Würfeln: 6+6=12 \n",
"haeufigkeiten = [0 for i in range(13)]\n",
"\n",
- "wuerfe = 100000\n",
+ "wuerfe = 1000\n",
"for i in range(wuerfe):\n",
" # Würfelsumme für zwei Würfel zählen\n",
" haeufigkeiten[random.randrange(1,7) + random.randrange(1,7)] += 1\n",
diff --git a/notebooks/seminar01.ipynb b/notebooks/seminar01.ipynb
index 9b6df042cac97dcde5c9d74592e0213238345b4d..ef271eeb7e58025fb30daa1b5eb9d4dbab839351 100644
--- a/notebooks/seminar01.ipynb
+++ b/notebooks/seminar01.ipynb
@@ -4,12 +4,25 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "# Seminar Problemorientierte Programmierung\n",
- "\n",
- "## Kapitel 1: Die Ersten Programme\n",
+ "# Kapitel 1: Die Ersten Programme\n",
"__[Chapter 1 The Way of the Program](http://greenteapress.com/thinkpython2/html/thinkpython2002.html)__\n",
"\n",
- "### Ihre Lernziele:\n",
+ "**Wichtig:** Bevor Sie anfangen dieses Jupyter-Notebook zu Bearbeiten schauen Sie sich bitte zuerst [das Einführungsnotebook](notebooks_einführung_jn.ipynb) so wie [das 0. Seminarnotebook](notebooks_seminar00.ipynb) an. Diese enthalten wichtige Hinweiße für das Verwenden von Jupyter-Notebooks. Wenn Sie die Notebooks in das selbe Verzeichnis heruntergeladen und nicht umbenannt haben, können Sie die Links verwenden um die entsprechenden Notebooks zu öffen, andernfalls können Sie die Notebooks ebenfalls auf [Gitlab](https://scm.cms.hu-berlin.de/ibi/python/-/tree/master/notebooks) finden."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "<h1>Table of Contents<span class=\"tocSkip\"></span></h1>\n",
+ "<div class=\"toc\"><ul class=\"toc-item\"><li><span><a href=\"#Ihre-Lernziele:\" data-toc-modified-id=\"Ihre-Lernziele:-1\"><span class=\"toc-item-num\">1 </span>Ihre Lernziele:</a></span></li><li><span><a href=\"#Exkurs:-Was-mir-an-Python-gefällt:\" data-toc-modified-id=\"Exkurs:-Was-mir-an-Python-gefällt:-2\"><span class=\"toc-item-num\">2 </span>Exkurs: Was mir an Python gefällt:</a></span></li><li><span><a href=\"#Programme\" data-toc-modified-id=\"Programme-3\"><span class=\"toc-item-num\">3 </span>Programme</a></span><ul class=\"toc-item\"><li><span><a href=\"#Eine-erste-Anweisung\" data-toc-modified-id=\"Eine-erste-Anweisung-3.1\"><span class=\"toc-item-num\">3.1 </span>Eine erste Anweisung</a></span></li><li><span><a href=\"#Python-Programme-starten\" data-toc-modified-id=\"Python-Programme-starten-3.2\"><span class=\"toc-item-num\">3.2 </span>Python-Programme starten</a></span></li><li><span><a href=\"#Arithmetik\" data-toc-modified-id=\"Arithmetik-3.3\"><span class=\"toc-item-num\">3.3 </span>Arithmetik</a></span></li></ul></li><li><span><a href=\"#Werte-und-Datentypen\" data-toc-modified-id=\"Werte-und-Datentypen-4\"><span class=\"toc-item-num\">4 </span>Werte und Datentypen</a></span></li><li><span><a href=\"#Formale-und-natürliche-Sprachen\" data-toc-modified-id=\"Formale-und-natürliche-Sprachen-5\"><span class=\"toc-item-num\">5 </span>Formale und natürliche Sprachen</a></span></li><li><span><a href=\"#Exkurs:-Programmierer\" data-toc-modified-id=\"Exkurs:-Programmierer-6\"><span class=\"toc-item-num\">6 </span>Exkurs: Programmierer</a></span></li><li><span><a href=\"#Debugging\" data-toc-modified-id=\"Debugging-7\"><span class=\"toc-item-num\">7 </span>Debugging</a></span></li><li><span><a href=\"#Glossar\" data-toc-modified-id=\"Glossar-8\"><span class=\"toc-item-num\">8 </span>Glossar</a></span></li><li><span><a href=\"#Übung\" data-toc-modified-id=\"Übung-9\"><span class=\"toc-item-num\">9 </span>Übung</a></span><ul class=\"toc-item\"><li><span><a href=\"#Aufgabe-1\" data-toc-modified-id=\"Aufgabe-1-9.1\"><span class=\"toc-item-num\">9.1 </span>Aufgabe 1</a></span></li><li><span><a href=\"#Aufgabe-2\" data-toc-modified-id=\"Aufgabe-2-9.2\"><span class=\"toc-item-num\">9.2 </span>Aufgabe 2</a></span></li></ul></li></ul></div>"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Ihre Lernziele:\n",
"Beschreiben Sie in 2-3 Stichpunkten was Sie heute lernen wollen. Sie können diesen Text durch Doppelklick bearbeiten.\n",
" \n",
" - \n",
@@ -24,7 +37,9 @@
"source": [
"## Exkurs: Was mir an Python gefällt:\n",
"\n",
- "Ich finde toll, dass mir Python Berechnungen mit Datumsangaben sehr vereinfacht:"
+ "Ich finde toll, dass mir Python Berechnungen mit Datumsangaben sehr vereinfacht:\n",
+ "\n",
+ "Bitte beachten Sie, dass Sie **erst den Code ausführen (Strg + Enter)** und anschließend in das neue Eingabefeld Ihren Geburtstag eingeben."
]
},
{
@@ -49,7 +64,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "### Programme\n",
+ "## Programme\n",
"\n",
"Was ist ein Programm?\n",
"\n",
@@ -92,7 +107,7 @@
"\n",
"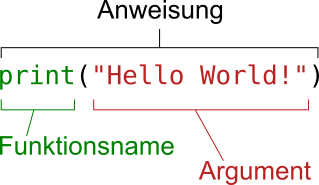\n",
"\n",
- "Das Ergebnis dieses Funktionsaufrufs ist, dass die Zeichenkette auf dem Bildschirm ausgegeben wird.\n",
+ "Das Ergebnis dieses Funktionsaufrufs ist, dass die Zeichenkette auf dem Bildschirm ausgegeben wird. \n",
"\n",
"Probieren Sie es nun selber und geben Sie eine Zeichenkette Ihrer Wahl aus, indem Sie die Zeichenkette in Gänsefüßchen der `print`-Funktion als **Argument** übergeben: "
]
@@ -121,6 +136,10 @@
"\n",
"Wenn wir ein Programm (hier einer der Blöcke mit Python-Code) starten, dann starten wir im Hintergrund den sogenannten **Python-Interpreter**. Das ist ein Programm, welches den Python-Code liest, für den Computer übersetzt und ausführt. Wir können den Python-Interpreter auch ohne Jupyter aufrufen und dort direkt Python-Anweisungen eingeben oder Programme starten, die wir in einer Datei gespeichert haben. Für den Anfang bleiben wir aber bei Jupyter, weil wir hier Programme und Erklärungen leicht kombinieren können.\n",
"\n",
+ "\n",
+ "**Tipp**: Nutzen Sie http://pythontutor.com, um Ihren Code nachvollziehen zu können und Fehler zu finden!\n",
+ "\n",
+ "\n",
"### Arithmetik\n",
"\n",
"Neben Zeichenketten sind Zahlen ein wichtiges Mittel zur Informationsdarstellung. Wir können mit der `print`-Funktion auch Zahlen ausgeben, diese müssen wir nicht in Gänsefüßchen einschließen:"
@@ -216,7 +235,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "### Werte und Datentypen\n",
+ "## Werte und Datentypen\n",
"\n",
"Ein **Wert**, also z.B. eine Zahl oder eine Zeichenkette, ist eines der grundlegenden Dinge, die in einem Programm verarbeitet werden. Beispiele für Werte, die wir schon gesehen haben sind `\"Hello World!\"`, `17` und `3.1415926`. Diese Werte haben verschiedenen **Datentypen**:\n",
"- `\"Hello World!\"` ist eine **Zeichenkette** (Englisch: *string*)\n",
@@ -271,7 +290,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "Was passiert, wenn wir Werte wie `\"42\"` und `\"3.14\"`mit Gänsefüßchen einfassen wie Zeichenketten? Finden Sie es heraus indem Sie den folgenden Codeblock nutzen."
+ "Was passiert, wenn wir Werte wie `\"42\"` und `\"3.14\"`mit Gänsefüßchen einfassen wie Zeichenketten? Sind es Zeichenketten oder Zahlen? Finden Sie es heraus indem Sie den folgenden Codeblock nutzen."
]
},
{
@@ -285,9 +304,6 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "Sind es Zeichenketten oder Zahlen?\n",
- "\n",
- "\n",
"In Python gibt es noch weitere Datentypen, die wir später kennenlernen werden. Hier schon einmal ein Überblick: \n",
"\n",
"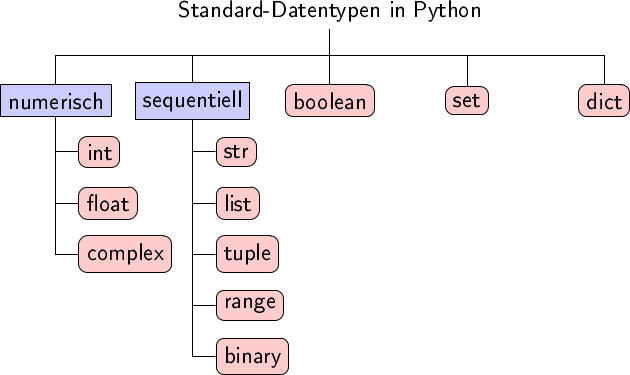"
@@ -297,25 +313,25 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "### Formale und natürliche Sprachen\n",
+ "## Formale und natürliche Sprachen\n",
"\n",
"Besonders ausführlich wird der Unterschied zwischen natürlicher und formaler Sprache in [Abschnitt 1.6](http://greenteapress.com/thinkpython2/html/thinkpython2002.html#sec11) des englischen Buchs behandelt.\n",
"\n",
"Grundsätzlich jedoch sind **natürliche Sprachen** Sprachen, die gesprochen werden, wie zum Beispiel Deutsch, Englisch oder Französisch. Sie werden nicht von Menschen entworfen und entwickeln sich natürlich.\n",
"\n",
"**Formale Sprachen** sind von Menschen für bestimmte Zwecke entworfene Sprachen. Das hier relevanteste Beispiel sind **Programmiersprachen**.\n",
- "Sie haben meist sehr strenge **Syntax-Regeln**, die ihre Struktur bestimmen. Dabei gibt es Regeln zu den erlaubten Zeichen und zu der erlaubten Struktur. Während der menschenliche **Parser** häufig mit sprachlichen Regelbrüchen umgehen kann, kann es der **Parser** im Computer nicht.\n",
+ "Sie haben meist sehr strenge **Syntax-Regeln**, die ihre Struktur bestimmen. Dabei gibt es Regeln zu den erlaubten Zeichen und zu der erlaubten Struktur. Während der menschliche **Parser** häufig mit sprachlichen Regelbrüchen umgehen kann, kann es der **Parser** im Computer nicht.\n",
"\n",
">Die§ ist ein gr@mmatikalisch k0rrekter S@tz mit ungültigen Zeichen. Satz dieser nur erlaubte Zeichen aber Grammatik falsche hat. \n",
"\n",
- "Wichtige Unterschiede sind, dass näturliche Sprache zweideutig, redundant und voller Symbolismus sein darf, formale Sprache aber nicht."
+ "Wichtige Unterschiede sind, dass natürliche Sprache zweideutig, redundant und voller Symbolismus sein darf, formale Sprache aber nicht."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "### Exkurs: Programmierer\n",
+ "## Exkurs: Programmierer\n",
"\n",
"Wir können effektiver programmieren, wenn wir eine **Entwicklungsumgebung** benutzen. Meistens ist das ein Texteditor, der einem das Programmieren erleichtert, indem z.B. der Quelltext farblich hervorgehoben wird - wie hier in Jupyter auch. Es gibt einen [seit Jahren schwelenden \"Streit\"](https://en.wikipedia.org/wiki/Editor_war), welcher Editor der beste ist: Emacs oder Vi. Randall Munroe (Autor des Webcomics [XKCD](https://xkcd.com/)) hat das auf seine ganz eigene Art verarbeitet:\n",
"\n",
@@ -328,10 +344,10 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "### Debugging\n",
+ "## Debugging\n",
"\n",
"Als Programmierer/innen machen wir häufiger Fehler. Diese Fehler werden **bugs** genannt und der Vorgang, Sie zu finden und zu beheben **debugging**. Dies kann zu starken (negativen) Gefühlen führen. \n",
- "Es lässt sich darauf zurück führen, dass wir Computer unterbewusst wie Menschen behandeln und darum auf unkooperative Computer genauso reagieren wie auf unkooperative Mitmenschen. Es kann helfen darauf vorbereitet zu sein und den Computer als Mitarbeiter zu sehen, der sehr schnell und gut rechnen kann aber sehr genaue Anweisungen braucht.\n",
+ "Es lässt sich darauf zurückführen, dass wir Computer unterbewusst wie Menschen behandeln und darum auf unkooperative Computer genauso reagieren wie auf unkooperative Mitmenschen. Es kann helfen darauf vorbereitet zu sein und den Computer als Mitarbeiter zu sehen, der sehr schnell und gut rechnen kann aber sehr genaue Anweisungen braucht.\n",
"\n",
"Obwohl es sehr frustrierend sein kann zu lernen wie man diese Fehler findet und behebt ist es eine wertvolle Fähigkeit und in dieser Kategorie werden wir uns regelmäßig Tipps und Strategien des Debugging anschauen, die Ihnen hoffentlich helfen. \n",
"\n",
@@ -342,13 +358,13 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "### Glossar\n",
+ "## Glossar\n",
"\n",
"Legen wir uns eine Liste mit den wichtigsten Begriffen an, die wir im Kapitel 1 gelernt haben:\n",
"\n",
"- Anweisung: \n",
"- Programm: \n",
- "- `print`-Funktion:\n",
+ "- **`print`-Funktion**:\n",
"- Argument:\n",
"- Operator:\n",
"- Wert: \n",
@@ -367,16 +383,16 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "### Ãœbung\n",
+ "## Ãœbung\n",
"\n",
"Diese Übung ist ein wichtiger Teil des Seminars. Bitte fahren Sie erst fort, wenn Sie die Aufgaben selbständig lösen konnten. Sie geben Ihnen die Möglichkeit, das Gelernte zu überprüfen und zu vertiefen.\n",
"\n",
- "#### Aufgabe 1\n",
+ "### Aufgabe 1\n",
"\n",
"Wann immer wir etwas neues ausprobieren, sollten wir versuchen, absichtlich einen Fehler zu machen. Probieren Sie z.B. \n",
"- Was passiert, wenn Sie im \"Hello World\"-Programm eines der Gänsefüßchen weglassen?\n",
"- Was passiert, wenn Sie beide weglassen?\n",
- "- Was passiert, wenn sie `print` falsch schreiben?\n",
+ "- Was passiert, wenn Sie `print` falsch schreiben?\n",
"- Was passiert, wenn Sie beim Aufruf der `print`-Funktion eine oder beide der Klammern weglassen?\n",
"Probieren Sie es aus:"
]
@@ -412,9 +428,9 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "#### Aufgabe 2\n",
+ "### Aufgabe 2\n",
"\n",
- "Nutzen Sie Python als Taschenrechner:\n",
+ "Nutzen Sie Python als Taschenrechner: Keine Sorge, während Sie hier zwar Textaufgaben lösen müssen ist dies nicht das Ziel der Übung. Wenn Sie nicht weiterkommen schauen Sie sich zuerst die Hinweiße an und fragen Sie gegebenenfalls um Hilfe. Es geht hier darum zu verstehen, wie man diese Aufgabe in Python lösen kann, der Rechenweg ist eher Zweitrangig.\n",
"\n",
"- Wieviele Sekunden entsprechen 42 Minuten und 42 Sekunden?"
]
@@ -430,7 +446,30 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "- Wieviele Meilen entsprechen 10 Kilometer (Hinweis: eine Meile ist 1.61 Kilometer lang)"
+ "<details>\n",
+ " <summary type=\"button\" class=\"btn btn-success\">Lösung</summary>\n",
+ " <div class=\"alert alert-success\" role=\"alert\">\n",
+ "\n",
+ "2562 Sekunden\n",
+ " \n",
+ " </div> \n",
+ "</details>"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "- Wieviele Meilen entsprechen 10 Kilometer \n",
+ "\n",
+ "<details>\n",
+ " <summary type=\"button\" class=\"btn btn-info\">Hinweiß</summary>\n",
+ " <div class=\"alert alert-info\" role=\"alert\">\n",
+ "\n",
+ "Eine Meile ist 1.61 Kilometer lang\n",
+ " \n",
+ " </div> \n",
+ "</details>"
]
},
{
@@ -444,7 +483,33 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "- Wenn Sie ein Rennen über 10 Kilometer in 42 Minuten und 42 Sekunden beenden, was ist Ihre Durchschnittsgeschwindigkeit (Zeit pro Meile in Minuten und Sekunden)? Was ist Ihre Durchschnittsgeschwindigkeit in Meilen pro Stunde?"
+ "\n",
+ "<details>\n",
+ " <summary type=\"button\" class=\"btn btn-success\">Lösung</summary>\n",
+ " <div class=\"alert alert-success\" role=\"alert\">\n",
+ "\n",
+ "6.21 Meilen\n",
+ " \n",
+ " </div> \n",
+ "</details>"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "- Wenn Sie ein Rennen über 10 Kilometer in 42 Minuten und 42 Sekunden beenden, was ist Ihre Durchschnittsgeschwindigkeit (**Zeit pro Meile** in Minuten und Sekunden)? Was ist Ihre Durchschnittsgeschwindigkeit in **Meilen pro Stunde**?\n",
+ "\n",
+ "\n",
+ "<details>\n",
+ " <summary type=\"button\" class=\"btn btn-info\">Hinweiße</summary>\n",
+ " <div class=\"alert alert-info\" role=\"alert\">\n",
+ "1. Zuerst müssen Sie herausfinden wie viele Meilen das Rennen lang ist. Das können Sie im vorherigen Teil der Aufgabe erfahren <br> \n",
+ "2. Es ist leichter zu rechnen wenn es weniger Einheiten gibt. Sie haben bereits ausgerechnet wie viele Sekunden 42 Minuten und 2 Sekunden sind. <br>\n",
+ "3. Um die Zeit pro Meile zu errechnen teilen Sie die Gesamtzeit durch die Anzahl an Meilen und Rechnen dann die Zeit von Sekunden in Minuten um. Die Zahl muss kleiner werden, überlegen Sie also wie viele Sekunden einer Minute entsprechen und teilen Sie durch diesen Wert. <br>\n",
+ "4. Um dann die Geschwindigkeit in Meilen pro Stunde zu berechnen gehen Sie analog vor. Teilen Sie die Gesamtzahl an Meilen durch die Dauer des Rennen, dabei rechnen Sie diese Zahl direkt in Stunden um (Wie viele Sekunden in einer Minute * Wie viele Minuten in einer Stunde)\n",
+ " </div> \n",
+ "</details>"
]
},
{
@@ -458,13 +523,15 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "##### Ergebnisse\n",
- "\n",
- "([Spoiler Alert](https://xkcd.com/109/), Randall Munroe)\n",
- "\n",
- "\n",
"\n",
- "2562 Sekunden, 6.21 Meilen, Die Durchschnittsgeschwindigkeit beträgt 6,88 Minuten pro Meile bzw. 8,73 Meilen pro Stunde"
+ "<details>\n",
+ " <summary type=\"button\" class=\"btn btn-success\">Lösung</summary>\n",
+ " <div class=\"alert alert-success\" role=\"alert\">\n",
+ " \n",
+ "Die Durchschnittsgeschwindigkeit beträgt 6,88 Minuten pro Meile bzw. 8,73 Meilen pro Stunde\n",
+ " \n",
+ " </div> \n",
+ "</details>"
]
},
{
diff --git a/notebooks/seminar02.ipynb b/notebooks/seminar02.ipynb
index 1dd09edbe582885603acadde172067ced7a09955..69d5c38a3cdbffeb2123d26eccd66995d9317c6a 100644
--- a/notebooks/seminar02.ipynb
+++ b/notebooks/seminar02.ipynb
@@ -1,11 +1,23 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "<h1>Table of Contents<span class=\"tocSkip\"></span></h1>\n",
+ "<div class=\"toc\"><ul class=\"toc-item\"><li><span><a href=\"#Kapitel-2:-Variablen,-Ausdrücke-und-Anweisungen\" data-toc-modified-id=\"Kapitel-2:-Variablen,-Ausdrücke-und-Anweisungen-1\"><span class=\"toc-item-num\">1 </span>Kapitel 2: Variablen, Ausdrücke und Anweisungen</a></span><ul class=\"toc-item\"><li><span><a href=\"#Ihre-Lernziele\" data-toc-modified-id=\"Ihre-Lernziele-1.1\"><span class=\"toc-item-num\">1.1 </span>Ihre Lernziele</a></span></li><li><span><a href=\"#Exkurs:-Was-mir-an-Python-gefällt\" data-toc-modified-id=\"Exkurs:-Was-mir-an-Python-gefällt-1.2\"><span class=\"toc-item-num\">1.2 </span>Exkurs: Was mir an Python gefällt</a></span></li><li><span><a href=\"#Zuweisung\" data-toc-modified-id=\"Zuweisung-1.3\"><span class=\"toc-item-num\">1.3 </span>Zuweisung</a></span></li><li><span><a href=\"#(Variablen)Namen\" data-toc-modified-id=\"(Variablen)Namen-1.4\"><span class=\"toc-item-num\">1.4 </span>(Variablen)Namen</a></span></li><li><span><a href=\"#Ausdrücke-und-Anweisungen\" data-toc-modified-id=\"Ausdrücke-und-Anweisungen-1.5\"><span class=\"toc-item-num\">1.5 </span>Ausdrücke und Anweisungen</a></span></li><li><span><a href=\"#Reihenfolge-von-Operatoren\" data-toc-modified-id=\"Reihenfolge-von-Operatoren-1.6\"><span class=\"toc-item-num\">1.6 </span>Reihenfolge von Operatoren</a></span></li><li><span><a href=\"#Operatoren-für-Zeichenketten\" data-toc-modified-id=\"Operatoren-für-Zeichenketten-1.7\"><span class=\"toc-item-num\">1.7 </span>Operatoren für Zeichenketten</a></span></li></ul></li><li><span><a href=\"#Kommentare\" data-toc-modified-id=\"Kommentare-2\"><span class=\"toc-item-num\">2 </span>Kommentare</a></span><ul class=\"toc-item\"><li><span><a href=\"#Debugging\" data-toc-modified-id=\"Debugging-2.1\"><span class=\"toc-item-num\">2.1 </span>Debugging</a></span></li><li><span><a href=\"#Glossar\" data-toc-modified-id=\"Glossar-2.2\"><span class=\"toc-item-num\">2.2 </span>Glossar</a></span></li><li><span><a href=\"#Übung\" data-toc-modified-id=\"Übung-2.3\"><span class=\"toc-item-num\">2.3 </span>Übung</a></span><ul class=\"toc-item\"><li><span><a href=\"#Aufgabe-1\" data-toc-modified-id=\"Aufgabe-1-2.3.1\"><span class=\"toc-item-num\">2.3.1 </span>Aufgabe 1</a></span></li><li><span><a href=\"#Aufgabe-2\" data-toc-modified-id=\"Aufgabe-2-2.3.2\"><span class=\"toc-item-num\">2.3.2 </span>Aufgabe 2</a></span></li><li><span><a href=\"#Ergebnisse\" data-toc-modified-id=\"Ergebnisse-2.3.3\"><span class=\"toc-item-num\">2.3.3 </span>Ergebnisse</a></span></li></ul></li><li><span><a href=\"#print-Tutorial\" data-toc-modified-id=\"print-Tutorial-2.4\"><span class=\"toc-item-num\">2.4 </span><code>print</code> Tutorial</a></span></li></ul></li></ul></div>"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Seminar Problemorientierte Programmierung\n",
"\n",
+ "**Bevor Sie mit diesem Notebook starten, gehen Sie zurück in das vorherige Notebook und schauen Sie sich mindestens das Glossar an, um zu wiederholen, was Sie letztes Notebook gelernt haben.**\n",
+ "\n",
+ "\n",
+ "\n",
"## Kapitel 2: Variablen, Ausdrücke und Anweisungen\n",
"[Chapter 2: Variables, expressions and statements](http://greenteapress.com/thinkpython2/html/thinkpython2003.html).\n",
"\n",
@@ -25,7 +37,7 @@
"\n",
"### Exkurs: Was mir an Python gefällt\n",
"\n",
- "Dieses Programm durchsucht alle Jupyter Notebooks in dem Verzeichnes in dem dieses Notebook gespeichert ist. "
+ "Dieses Programm durchsucht alle Jupyter Notebooks in dem Verzeichnis in dem dieses Notebook gespeichert ist. "
]
},
{
@@ -178,7 +190,11 @@
"source": [
"Erklärungen:\n",
"- Der Name `mehr@` ist nicht erlaubt, weil das Zeichen `@` nicht zu den Zeichen gehört, aus denen ein Name bestehen darf.\n",
- "- Der Name `class` ist anders, denn er enthält nur erlaubte Zeichen. Warum gibt es dennoch einen Fehler? Der Grund ist, dass `class` ein sogenanntes **Schlüsselwort** ist. Schlüsselwörter helfen Python, die Struktur eines Programms zu erkennen und dürfen daher nicht als Namen für Variablen (und Funktionen) verwendet werden. In Python 3 gibt es die folgenden Schlüsselwörter: `False None True and as assert break class continue def del elif else except finally for from global if import in is lambda nonlocal not or pass raise return try while with yield`. Sie brauchen sich die Liste nicht zu merken. In den meisten Entwicklungsumgebungen (Programmen zum Bearbeiten von Quellcode - wie z.B. Jupyter) werden diese Wörter farblich hervorgehoben und Sie werden somit gewarnt, falls Sie eines dieser Wörter als Variablennamen verwenden wollen."
+ "- Der Name `class` ist anders, denn er enthält nur erlaubte Zeichen. Warum gibt es dennoch einen Fehler? Der Grund ist, dass `class` ein sogenanntes **Schlüsselwort** ist. Schlüsselwörter helfen Python, die Struktur eines Programms zu erkennen und dürfen daher nicht als Namen für Variablen (und Funktionen) verwendet werden. In Python 3 gibt es die folgenden Schlüsselwörter: `False None True and as assert break class continue def del elif else except finally for from global if import in is lambda nonlocal not or pass raise return try while with yield`. Sie brauchen sich die Liste nicht zu merken. In den meisten Entwicklungsumgebungen (Programmen zum Bearbeiten von Quellcode - wie z.B. Jupyter) werden diese Wörter farblich hervorgehoben und Sie werden somit gewarnt, falls Sie eines dieser Wörter als Variablennamen verwenden wollen.\n",
+ "\n",
+ "\n",
+ "\n",
+ "([Keep it simple, stupid](http://www.commitstrip.com/en/2016/09/01/keep-it-simple-stupid/), CommitStrip.com)"
]
},
{
@@ -595,7 +611,10 @@
"\n",
"- [\"Good code is its own best documentation.\" (Steve McConnell)](http://de.wikipedia.org/wiki/Steve_McConnell)\n",
"- [\"Yes your Code does need comments\" (Mike Grouchy)](http://mikegrouchy.com/blog/2013/03/yes-your-code-does-need-comments.html)\n",
- "- [Funny comments](https://stackoverflow.com/questions/184618/what-is-the-best-comment-in-source-code-you-have-ever-encountered)"
+ "- [Funny comments](https://stackoverflow.com/questions/184618/what-is-the-best-comment-in-source-code-you-have-ever-encountered)\n",
+ "\n",
+ "\n",
+ "([Programming Elements – Comments](https://prairieworldcomicsblog.wordpress.com/2018/01/26/programming-elements-comments/), William Wise)"
]
},
{
@@ -627,6 +646,7 @@
"- Syntaxfehler:\n",
"- Laufzeitfehler:\n",
"- semantischer Fehler:\n",
+ "- `print`-Funktion:\n",
"\n",
"Ergänzen Sie die Liste in eigenen Worten. Das ist eine gute Erinnerungs- und Übungsmöglichkeit.\n",
"\n"
@@ -745,6 +765,120 @@
"Volumen 523.599; Die gesamte Bestellung würde 1126,89€ kosten; Ankunft ist 7:30 Uhr und 6 Sekunden"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### `print` Tutorial \n",
+ "\n",
+ "Hier lernen Sie einige Tricks kennen, um mit der `print`-Funktion ihre Ausgabe formatieren können.\n",
+ "Bis jetzt haben Sie gelernt, dass man sich mit Hilfe der `print`-Funktion Zeichenketten, Zahlen, Variablen. etc. ausgeben lassen kann. \n",
+ "Zeichenketten müssen dabei immer in Anführungszeichen stehen. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(\"Hallo Welt!\")\n",
+ "\n",
+ "print(42)\n",
+ "print(52-10)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Man kann auch mehrere Argumente übergeben, diese müssen durch ein Komma getrennt werden.\n",
+ "Die Ausgabe erfolgt mit einem Leerzeichen getrennt."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(42, 35.32-9.0, \"Hallo Welt\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "und natürlich können Sie sich auch Variablen ausgeben lassen:\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "a = 42\n",
+ "b = \"Die Antwort lautet:\"\n",
+ " \n",
+ "print(b,a)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Um längere Ausgaben, mehrere Variablen ,etc. schöner zu formatieren, gibt es einige Tricks.\n",
+ "Einmal kann man der Funktionen einen extra Parameter übergeben, der einstellt, durch welches Zeichen die verschiedenen Argumente getrennt werden sollen.\n",
+ "\n",
+ "Standardmäßig und wie oben gesehen, wird die Ausgabe mehrerer Argumente jeweils durch ein Leerzeichen getrennt.\n",
+ "Durch Hinzufügen des Parameter `print(b,a ,sep=\" \")` (MERKE: `sep` steht für `separator`) können Sie spezifizieren, welches Zeichen als Trennzeichen genommen wird. Schauen wir uns einige Beispiele an:\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "a = 42\n",
+ "b = \"Die Antwort lautet:\"\n",
+ "\n",
+ "# wenn `sep` nicht angegeben ist, wird standardmäßig ein Leerzeichen zwischen den Argumenten in `print` verwendet\n",
+ "print(b,a)\n",
+ "# Jetzt geben wir explizit an, dass der separator ein Leerzeichen sein soll, d.h., die Ausgabe ändert sich nicht.\n",
+ "print(b,a, sep = \" \")\n",
+ "# Jetzt soll der separator zwei Leerzeichen sein:\n",
+ "print(b,a, sep = \" \")\n",
+ "# und jetzt soll der separator ein `tab` (4 Leerzeichen) sein, das wird durch `\\t`angegeben\n",
+ "print(b,a, sep = \"\\t\")\n",
+ "# nun soll der separator ein Zeilenumbruch sein, das wird durch `\\n`angegeben\n",
+ "print(b,a, sep = \"\\n\")\n",
+ "# zum schluss kann man noch triple quotes (drei Anführungszeichen am Anfang und drei am Ende) nutzen,\n",
+ "# um Text in mehreren Zeilen zu schreiben: ''' '''\n",
+ "print(''' \n",
+ "Erste Zeile\n",
+ "Zweite Zeile\n",
+ "''')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Die Befehle `\\t`und `\\n` funktionieren auch innerhalb einer Zeichenkette:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(\"Hallo \\t Welt,\\n die Antwort lautet\\n42\")"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {},
diff --git a/notebooks/seminar03.ipynb b/notebooks/seminar03.ipynb
index c82307eda92a853e0ed01257c51e68e54e9b2ad2..01379e0bbd9013fee0b925aa2ec8f17278995e82 100644
--- a/notebooks/seminar03.ipynb
+++ b/notebooks/seminar03.ipynb
@@ -1,11 +1,21 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "<h1>Table of Contents<span class=\"tocSkip\"></span></h1>\n",
+ "<div class=\"toc\"><ul class=\"toc-item\"><li><span><a href=\"#Kapitel-3:-Funktionen\" data-toc-modified-id=\"Kapitel-3:-Funktionen-1\"><span class=\"toc-item-num\">1 </span>Kapitel 3: Funktionen</a></span><ul class=\"toc-item\"><li><span><a href=\"#Ihre-Lernziele\" data-toc-modified-id=\"Ihre-Lernziele-1.1\"><span class=\"toc-item-num\">1.1 </span>Ihre Lernziele</a></span></li><li><span><a href=\"#Exkurs:-Was-mir-an-Python-gefällt\" data-toc-modified-id=\"Exkurs:-Was-mir-an-Python-gefällt-1.2\"><span class=\"toc-item-num\">1.2 </span>Exkurs: Was mir an Python gefällt</a></span></li><li><span><a href=\"#Warum?\" data-toc-modified-id=\"Warum?-1.3\"><span class=\"toc-item-num\">1.3 </span>Warum?</a></span></li><li><span><a href=\"#3.1-Funktionsaufrufe\" data-toc-modified-id=\"3.1-Funktionsaufrufe-1.4\"><span class=\"toc-item-num\">1.4 </span>3.1 Funktionsaufrufe</a></span></li><li><span><a href=\"#3.2-Mathematische-Funktionen\" data-toc-modified-id=\"3.2-Mathematische-Funktionen-1.5\"><span class=\"toc-item-num\">1.5 </span>3.2 Mathematische Funktionen</a></span></li><li><span><a href=\"#3.3-Verknüpfung\" data-toc-modified-id=\"3.3-Verknüpfung-1.6\"><span class=\"toc-item-num\">1.6 </span>3.3 Verknüpfung</a></span></li><li><span><a href=\"#3.4-Neue-Funktionen-hinzufügen\" data-toc-modified-id=\"3.4-Neue-Funktionen-hinzufügen-1.7\"><span class=\"toc-item-num\">1.7 </span>3.4 Neue Funktionen hinzufügen</a></span></li><li><span><a href=\"#3.5-Definition-von-Funktionen-und-deren-Aufruf\" data-toc-modified-id=\"3.5-Definition-von-Funktionen-und-deren-Aufruf-1.8\"><span class=\"toc-item-num\">1.8 </span>3.5 Definition von Funktionen und deren Aufruf</a></span></li><li><span><a href=\"#3.6-Kontrollfluss\" data-toc-modified-id=\"3.6-Kontrollfluss-1.9\"><span class=\"toc-item-num\">1.9 </span>3.6 Kontrollfluss</a></span></li><li><span><a href=\"#3.7-Parameter-und-Argumente\" data-toc-modified-id=\"3.7-Parameter-und-Argumente-1.10\"><span class=\"toc-item-num\">1.10 </span>3.7 Parameter und Argumente</a></span></li><li><span><a href=\"#3.8-Variablen-und-Parameter-sind-lokal\" data-toc-modified-id=\"3.8-Variablen-und-Parameter-sind-lokal-1.11\"><span class=\"toc-item-num\">1.11 </span>3.8 Variablen und Parameter sind lokal</a></span></li><li><span><a href=\"#3.9-Stapel-Diagramme\" data-toc-modified-id=\"3.9-Stapel-Diagramme-1.12\"><span class=\"toc-item-num\">1.12 </span>3.9 Stapel-Diagramme</a></span></li><li><span><a href=\"#3.10-Funktionen-mit-Rückgabewert\" data-toc-modified-id=\"3.10-Funktionen-mit-Rückgabewert-1.13\"><span class=\"toc-item-num\">1.13 </span>3.10 Funktionen mit Rückgabewert</a></span></li><li><span><a href=\"#3.11-Exkurs:-Eigene-Funktionen-mit-Rückgabewert\" data-toc-modified-id=\"3.11-Exkurs:-Eigene-Funktionen-mit-Rückgabewert-1.14\"><span class=\"toc-item-num\">1.14 </span>3.11 Exkurs: Eigene Funktionen mit Rückgabewert</a></span></li><li><span><a href=\"#3.12-Debugging\" data-toc-modified-id=\"3.12-Debugging-1.15\"><span class=\"toc-item-num\">1.15 </span>3.12 Debugging</a></span></li><li><span><a href=\"#3.13-Glossar\" data-toc-modified-id=\"3.13-Glossar-1.16\"><span class=\"toc-item-num\">1.16 </span>3.13 Glossar</a></span></li></ul></li><li><span><a href=\"#3.14-Übung\" data-toc-modified-id=\"3.14-Übung-2\"><span class=\"toc-item-num\">2 </span>3.14 Übung</a></span><ul class=\"toc-item\"><li><span><a href=\"#Aufgabe-1\" data-toc-modified-id=\"Aufgabe-1-2.1\"><span class=\"toc-item-num\">2.1 </span>Aufgabe 1</a></span><ul class=\"toc-item\"><li><span><a href=\"#Aufgabe-1a\" data-toc-modified-id=\"Aufgabe-1a-2.1.1\"><span class=\"toc-item-num\">2.1.1 </span>Aufgabe 1a</a></span><ul class=\"toc-item\"><li><span><a href=\"#Lückentext\" data-toc-modified-id=\"Lückentext-2.1.1.1\"><span class=\"toc-item-num\">2.1.1.1 </span>Lückentext</a></span></li></ul></li><li><span><a href=\"#Aufgabe-1b\" data-toc-modified-id=\"Aufgabe-1b-2.1.2\"><span class=\"toc-item-num\">2.1.2 </span>Aufgabe 1b</a></span></li><li><span><a href=\"#Aufgabe-2\" data-toc-modified-id=\"Aufgabe-2-2.1.3\"><span class=\"toc-item-num\">2.1.3 </span>Aufgabe 2</a></span></li><li><span><a href=\"#Aufgabe-3\" data-toc-modified-id=\"Aufgabe-3-2.1.4\"><span class=\"toc-item-num\">2.1.4 </span>Aufgabe 3</a></span><ul class=\"toc-item\"><li><span><a href=\"#1.\" data-toc-modified-id=\"1.-2.1.4.1\"><span class=\"toc-item-num\">2.1.4.1 </span>1.</a></span></li><li><span><a href=\"#2.\" data-toc-modified-id=\"2.-2.1.4.2\"><span class=\"toc-item-num\">2.1.4.2 </span>2.</a></span></li></ul></li><li><span><a href=\"#Bonusaufgabe\" data-toc-modified-id=\"Bonusaufgabe-2.1.5\"><span class=\"toc-item-num\">2.1.5 </span>Bonusaufgabe</a></span></li></ul></li></ul></li></ul></div>"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Seminar Problemorientierte Programmierung\n",
"\n",
+ "**Bevor Sie mit diesem Notebook starten, gehen Sie zurück in das vorherige Notebook und schauen Sie sich mindestens das Glossar an, um zu wiederholen, was Sie letztes Notebook gelernt haben.**\n",
+ "\n",
"## Kapitel 3: Funktionen\n",
"[Chapter 3: Functions](http://greenteapress.com/thinkpython2/html/thinkpython2004.html)\n",
"\n",
@@ -192,6 +202,13 @@
"outputs": [],
"source": []
},
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "**Tipp**: Nutzen Sie http://pythontutor.com, um ihren Code nachvollziehen zu können und Fehler zu finden!"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {},
diff --git a/notebooks/seminar03extra.ipynb b/notebooks/seminar03extra.ipynb
index 91029266945dadaa32f83231594bb7dc4982e138..4f31ba5e55ce4712b9c3cbbeda38e16328e1376a 100644
--- a/notebooks/seminar03extra.ipynb
+++ b/notebooks/seminar03extra.ipynb
@@ -70,10 +70,10 @@
"source": [
"\n",
"1. In der ersten Zeile wird das `re`-Modul importiert. Das muss einmal am Anfang unseres Programms passieren. Hier im Jupyter-Notebook reicht es, wenn das Modul in einem Block importiert wird - sobald der Block ausgeführt wurde, kann es in allen folgenden Blöcken verwendet werden.\n",
- "2. In der nächsten Zeile wird -mittels der Punkt-Notation- die `findall`-Funktion im `re`-Modul aufgerufen.\n",
+ "2. In der nächsten Zeile wird - mittels der Punkt-Notation - die `findall`-Funktion im `re`-Modul aufgerufen.\n",
"3. Der Funktion werden zwei Argumente übergeben: `r'f[a-z]*'` und `'which foot or hand fell fastest'`.\n",
"4. Das erste Argument ist ein regulärer Ausdruck. Reguläre Ausdrücke werden in Hochkommata `''` eingeschlossen und beginnen mit einem `r`. \n",
- "5. Das heißt der eigentliche reguläre Ausdruck lautet `f[a-z]*`. Dieser Ausdruck beschreibt Zeichenketten, die mit einem `f` beginnen und von beliebig vielen - auch 0! - (`*`) Kleinbuchstaben (`[a-z]`) gefolgt werden. Dabei beschreibt der Ausdruck `[a-z]` in eckigen Klammern ein Zeichen, welches die Werte `a` bis `z` haben darf, das `*` dahinter besagt, dass dieses Zeichen beliebig oft wiederholt werden darf.\n",
+ "5. Das heißt, der eigentliche reguläre Ausdruck lautet `f[a-z]*`. Dieser Ausdruck beschreibt Zeichenketten, die mit einem `f` beginnen und von beliebig vielen - auch 0! - (`*`) Kleinbuchstaben (`[a-z]`) gefolgt werden. Dabei beschreibt der Ausdruck `[a-z]` in eckigen Klammern ein Zeichen, welches die Werte `a` bis `z` haben darf, das `*` dahinter besagt, dass dieses Zeichen beliebig oft wiederholt werden darf.\n",
"6. Das zweite Argument (`'which foot or hand fell fastest'`) ist die Zeichenkette, in der wir nach Teilzeichenketten suchen, die auf den übergebenen regulären Ausdruck passen.\n",
"\n",
"Das Ergebnis des Aufrufs von `findall` ist eine Liste der Teilzeichenketten, die auf das Muster passen - in unserem Beispiel sind das die Zeichenketten `foot`, `fell` und `fastest`. \n",
@@ -166,6 +166,234 @@
"Es gibt noch viele andere gute Tutorials zu regulären Ausdrücken, z.B. [hier](https://ryanstutorials.net/regular-expressions-tutorial/) oder [hier](https://www.python-kurs.eu/re.php). Sie können auch eine dieser Anleitungen durcharbeiten, wenn Sie damit besser zurechtkommen."
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### 3.4 weitere nützliche Funktionen des `re`-Moduls\n",
+ "\n",
+ "Sie haben in den Tutorials einige regulären Ausdrücke kennengelernt. Nun können wir weitere Funktionen des `re`-Moduls benutzen. Im Folgenden werden mehrere Funktionen vorgestellt. Anschließend können Sie diese in Übungen testen.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### 3.4.1 Suchen und Matchen \n",
+ "\n",
+ "Die Funktion `findall(regex,string)` haben sie schon kennengelernt:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import re\n",
+ "re.findall(r'f[a-z]*', 'which foot or hand fell fastest')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Zudem gibt es eine Funktion `search(regex,string)`. Die Argumente sind diesselben wie bei `findall`.\n",
+ "Diese Funktion durchsucht eine Zeichenkette *string* nach dem Vorkommen eines Teilstrings, der auf den regulären Ausdruck *regex* passt. Der erste gefundene Teilstring wird zurückgeliefert. Die Rückgabe ist ein sogennantes *match-Objekt*."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import re\n",
+ "object1 = re.search(r'f[a-z]*', 'which foot or hand fell fastest')\n",
+ "\n",
+ "object2 = re.search(r'f[a-z]*', 'The regex did not match anything.')\n",
+ "\n",
+ "print(object1,\"\\n\",object2)\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Ein *match-Objekt* enthält die Methoden `group()`, `span()`, `start()` und `end()`, die man im folgenden Beispiel im selbsterklärenden Einsatz sieht: "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "object1 = re.search(r'f[a-z]*', 'which foot or hand fell fastest')\n",
+ "print(object1.group())\n",
+ "print(object1.span())\n",
+ "print(object1.start())\n",
+ "print(object1.end())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Es gibt zuletzt noch eine dritte Funktion `match(regex,string)`. Diese Funktion checkt, ob ein Teilstring, der auf den regulären Ausdruck *regex* passt, am Anfang der Zeichenkette *string* vorkommt, Die Rückgabe ist wieder ein *match-Objekt*."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "object1 = re.match(r'f[a-z]*', 'foot or hand fell fastest')\n",
+ "object2 = re.match(r'f[a-z]*', 'which foot or hand fell fastest')\n",
+ "print(object2)\n",
+ "print(object1)\n",
+ "print(object1.group())\n",
+ "print(object1.span())\n",
+ "print(object1.start())\n",
+ "print(object1.end())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### 3.4.1 Ãœbung:\n",
+ "\n",
+ "Denken Sie sich eine Zeichenkette und einen regulären Ausdruck aus, die die Unterschiede der drei kennengelernten Funktionen wiedergibt. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### 3.4.2 Ersetzen "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Das `re`-Modul stellt nicht nur Funktionen zum Durchsuchen von Zeichenketten zur Verfügung. Mit der Funktion `re.sub(regex, replacement, string)` kann man Teilstrings ersetzen. Jede Übereinstimmung des regulären Ausdrucks *regex* in der Zeichenkette *string* wird durch die Zeichenkette *replacement* ersetzt."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "re.sub(r'f[a-z]*', 'beer', 'which foot or hand fell fastest')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### 3.4.3 Kompilieren\n",
+ "\n",
+ "Wenn man bestimmte reguläre Ausdrücke mehrmals benutzen möchte, kann man die Funktion `compile(regex)` benutzen. Diese Funktion kompiliert einen regulären Ausdruck *regex* in eine regex-Objekt. Dieses kann man dann für weitere Funktionen nutzen."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "regex_1 = re.compile(r'f[a-z]*')\n",
+ "\n",
+ "print(regex_1.findall('which foot or hand fell fastest'))\n",
+ "\n",
+ "print(regex_1.search('which foot or hand fell fastest'))\n",
+ "\n",
+ "print(regex_1.match('which foot or hand fell fastest'))\n",
+ "\n",
+ "print(regex_1.sub('beer','which foot or hand fell fastest'))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Aufgaben\n",
+ "\n",
+ "#### Aufgabe 1\n",
+ "Schreiben Sie eine Funktion, die eine Zeichenkette als Parameter entgegennimmt und überprüft, ob die Zeichenkette nur Kleinbuchstaben und Zahlen enthält. \n",
+ "Benutzen Sie reguläre Ausdrücke und die obigen Funktionen."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Aufgabe 2\n",
+ "\n",
+ "Schreiben Sie eine Funktion, die eine Zeichenkette als Parameter entgegennimmt und überprüft, ob die Zeichenkette einen Teilstring enthält, der aus einem \"a\" und nachfolgend aus mindestens einem \"b\" besteht. (z.B. \"abb\", \"abbbbb\", \"abbbbbbbbbbbbbbbb\"). \n",
+ "Benutzen Sie reguläre Ausdrücke und die obigen Funktionen.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Aufgabe 3\n",
+ "\n",
+ "Schreiben Sie eine Funktion, die eine Zeichenkette als Parameter entgegennimmt und alle darin enthaltenen Leerzeichen durch ein Minus ersetzt. \n",
+ "Benutzen Sie reguläre Ausdrücke und die obigen Funktionen."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Aufgabe 4\n",
+ "\n",
+ "Schreiben Sie eine Funktion, die eine Zeichenkette *s* und eine natürliche Zahl *n* als Parameter entgegennimmt und alle Wörter der Länge n aus der Zeichenkette *s* entfernt. \n",
+ "Benutzen Sie reguläre Ausdrücke und die obigen Funktionen."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ },
{
"cell_type": "markdown",
"metadata": {},
diff --git a/notebooks/seminar04.ipynb b/notebooks/seminar04.ipynb
index 08dd9b41b4898ba4f512690e15b854e19e89d3c6..a8993369a4fda28984c86a23ad78499109a3de68 100644
--- a/notebooks/seminar04.ipynb
+++ b/notebooks/seminar04.ipynb
@@ -353,7 +353,12 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "Ein Stück Quellcode in eine Funktion zu packen, nennt man \"Verkapselung\" (Englisch: *encapsulation*). Ein Vorteil der Verkapselung ist, dass für ein Stück Code ein Name vergeben wird, der wie eine Art Dokumentation wirkt, also sagt, was der Code macht. Ein anderer Vorteil ist, dass wir den Code leicht wiederverwenden können, denn es ist deutlich praktischer, eine Funktion zweimal aufzurufen, als den Quellcode im Funktionsrumpf zu kopieren."
+ "Ein Stück Quellcode in eine Funktion zu packen, nennt man \"Verkapselung\" (Englisch: *encapsulation*). Ein Vorteil der Verkapselung ist, dass für ein Stück Code ein Name vergeben wird, der wie eine Art Dokumentation wirkt, also sagt, was der Code macht. Ein anderer Vorteil ist, dass wir den Code leicht wiederverwenden können, denn es ist deutlich praktischer, eine Funktion zweimal aufzurufen, als den Quellcode im Funktionsrumpf zu kopieren.\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "([Code Quality](https://xkcd.com/1513/), Randall Munroe)"
]
},
{
diff --git a/notebooks/seminar05.ipynb b/notebooks/seminar05.ipynb
index 64d0a176b7c949fec77b514de3e7912b232e1639..66b888bf9e609ba157477aa8af01e2b5f5139e4a 100644
--- a/notebooks/seminar05.ipynb
+++ b/notebooks/seminar05.ipynb
@@ -122,7 +122,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "Alternativ können wir auch den Operator `%` zur **Restberechnung** verwenden. Dieser teilt zwei ganze Zahlen und gibt uns den Rest zurück:"
+ "Alternativ können wir auch den Operator `%` zur **Restberechnung** (siehe **modulo**) verwenden. Dieser teilt zwei ganze Zahlen und gibt uns den Rest zurück:"
]
},
{
@@ -150,7 +150,14 @@
"metadata": {},
"outputs": [],
"source": [
- "4711 % 100"
+ "print(4711 % 100)\n",
+ "\n",
+ "print(8 % 7)\n",
+ "\n",
+ "print (15 % 7)\n",
+ "\n",
+ "rest = 15 % 7\n",
+ "print(\"Der Rest von 15 / 7 ist\", rest)"
]
},
{
@@ -810,7 +817,7 @@
"outputs": [],
"source": [
"x = 5\n",
- " y = 6"
+ "y = 6"
]
},
{
diff --git a/notebooks/seminar06.ipynb b/notebooks/seminar06.ipynb
index 8b6174df8f7a05daaf52aee0f00f3fc4668cbd46..413df13040bfb5edbf59cc75946d532409e049d3 100644
--- a/notebooks/seminar06.ipynb
+++ b/notebooks/seminar06.ipynb
@@ -30,7 +30,7 @@
"source": [
"## Exkurs: Was mir an Python gefällt\n",
"\n",
- "Dieser Code enthält das Grundgerüst, um eine auf TCP basierende Serveranwendung zu programmieren."
+ "Das Modul os stellt Funktionen bereit, um Funktionalitäten des Betriebssystems zu nutzen. Beispielsweise können wir damit Verzeichnis-Inhalte auflisten, durch Verzeichnisse navigieren, Informationen zu Dateien bekommen und Dateieigenschaften verändern. Das folgende Programm gibt eine Liste aller Jupyter-Notebooks im aktuellen Verzeichnis zusammen mit der Dateigröße aus und berechnet die Gesamtgröße der Dateien:"
]
},
{
@@ -39,60 +39,26 @@
"metadata": {},
"outputs": [],
"source": [
- "# Quellen: https://docs.python.org/3/howto/sockets.html und \n",
- "# http://www.binarytides.com/python-socket-server-code-example/\n",
- "\n",
- "import socket\n",
- "\n",
- "# function for handling connections. This will be used to create threads\n",
- "def client_thread(conn):\n",
- " # sending message to connected client\n",
- " conn.send(bytearray('Welcome to the server. Type something and hit enter\\n', \"utf-8\")) #send only takes string\n",
- " \n",
- " # infinite loop so that function do not terminate and thread do not end.\n",
- " while True:\n",
- " \n",
- " # receiving from client\n",
- " data = conn.recv(1024)\n",
- " if not data: \n",
- " break\n",
- " # print on server side\n",
- " print(data.decode(\"utf-8\"))\n",
- " # echo to client side\n",
- " reply = bytearray('OK ... ', \"utf-8\") + data\n",
- " conn.sendall(reply)\n",
- " \n",
- " # came out of loop\n",
- " conn.close()\n",
- " \n",
- "# create an INET, STREAMing socket\n",
- "serversocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n",
- "# bind the socket to a public host, and a port\n",
- "# serversocket.bind((socket.gethostname(), 8080))\n",
- "# use localhost instead \n",
- "serversocket.bind((\"localhost\", 8080))\n",
- "# become a server socket\n",
- "serversocket.listen(5)\n",
+ "## Modul 6 \n",
"\n",
+ "import os\n",
"\n",
- "while True:\n",
- " # accept connections from outside\n",
- " (clientsocket, address) = serversocket.accept()\n",
- " # now do something with the clientsocket\n",
- " # in this case, we'll pretend this is a threaded server\n",
- " ct = client_thread(clientsocket)\n",
- " ct.run()\n",
+ "# Tabellenkopf ausgeben\n",
+ "print(\"Bytes\\tName\")\n",
+ "print(\"--------------------------------------------------------------\")\n",
"\n",
- "serversocket.close()"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "Wenn Sie den Code starten und sich dann mit Hilfe von Telnet mit der Anwendung verbinden (telnet localhost 8080), werden alle Eingaben an Sie zurückgespiegelt (\"echo\") und hier in Jupyter ausgegeben. Das ist eine sehr einfache Testanwendung, die aus Sicherheitsgründen nur von Ihrem Rechner aus erreichbar ist.\n",
+ "# Gesamtgröße in Bytes\n",
+ "bytes_sum = 0\n",
"\n",
- "Falls Ihr Rechner keinen Paketfilter (\"Firewall\") laufen hat und Sie die Zeile mit localhost auskommentieren und stattdessen die mit socket.gethostbyname() aktivieren, dann ist die Anwendung ggf. auch von anderen Rechnern erreichbar und stellt ziemlich sicher eine Sicherheitslücke dar. Gehen Sie also vorsichtig mit dieser Option um."
+ "# Inhalt des aktuellen Verzeichnisses durchlaufen\n",
+ "for entry in os.scandir():\n",
+ " if entry.is_file() and entry.name.endswith(\".ipynb\"):\n",
+ " size = entry.stat().st_size\n",
+ " bytes_sum +=size\n",
+ " print(\"{:5d}\".format(size), entry.name, sep='\\t')\n",
+ " \n",
+ "print(\"--------------------------------------------------------------\")\n",
+ "print(bytes_sum, \"bytes =\", bytes_sum/1000, \"kilobytes =\", bytes_sum/1000000, \"Megabytes\")"
]
},
{
@@ -699,7 +665,7 @@
"\n",
"Im untersten (letzten) Block existieren die lokalen Variablen `rekursion` und `ergebnis` nicht, denn derjenige Zweig, welcher diese erzeugt, wird nicht ausgeführt.\n",
"\n",
- "Nutzen Sie auch http://pythontutor.com/, um die einzelnen Schritte nachzuvollziehen!"
+ "Nutzen Sie auch [http://pythontutor.com/](http://pythontutor.com/visualize.html#code=def%20fakultaet%28n%29%3A%0A%20%20%20%20if%20n%20%3D%3D%200%3A%0A%20%20%20%20%20%20%20%20return%201%0A%20%20%20%20else%3A%0A%20%20%20%20%20%20%20%20rekursion%20%3D%20fakultaet%28n-1%29%0A%20%20%20%20%20%20%20%20ergebnis%20%3D%20n%20*%20rekursion%0A%20%20%20%20%20%20%20%20return%20ergebnis%0A%0Afakultaet%283%29&cumulative=false&curInstr=0&heapPrimitives=nevernest&mode=display&origin=opt-frontend.js&py=3&rawInputLstJSON=%5B%5D&textReferences=false), um die einzelnen Schritte nachzuvollziehen!"
]
},
{
diff --git a/notebooks/seminar07.ipynb b/notebooks/seminar07.ipynb
index 2086e332077d3de071575edc1b3b4221b80376fb..550bd18c56ed06900d84e9afb402a910c2d1a2ed 100644
--- a/notebooks/seminar07.ipynb
+++ b/notebooks/seminar07.ipynb
@@ -6,82 +6,103 @@
"source": [
"# Seminar Problemorientierte Programmierung\n",
"\n",
- "## Exkurs: Was mir an Python gefällt\n",
+ "## 7 Iteration\n",
"\n",
- "In dieser Rubrik, die immer am Anfang eines Kapitels steht, möchte ich Ihnen zeigen, wofür ich Python nutze und warum ich es mag. Sie werden vielleicht noch nicht verstehen, was ich genau mache, aber Sie sehen damit schon einmal die Möglichkeiten von Python und können später darauf zurückgreifen. Da dies auch ein Exkurs ist, können Sie diese Rubrik gerne auch erst einmal überspringen.\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {},
- "outputs": [],
- "source": [
- "# Quellen: https://docs.python.org/3/howto/sockets.html und \n",
- "# http://www.binarytides.com/python-socket-server-code-example/\n",
+ "[Chapter 7: Iteration](http://greenteapress.com/thinkpython2/html/thinkpython2008.html) \n",
"\n",
"import socket\n",
"\n",
- "# function for handling connections. This will be used to create threads\n",
- "def client_thread(conn):\n",
- " # sending message to connected client\n",
- " conn.send(bytearray('Welcome to the server. Type something and hit enter\\n', \"utf-8\")) #send only takes string\n",
- " \n",
- " # infinite loop so that function do not terminate and thread do not end.\n",
- " while True:\n",
- " \n",
- " # receiving from client\n",
- " data = conn.recv(1024)\n",
- " if not data: \n",
- " break\n",
- " # print on server side\n",
- " print(data.decode(\"utf-8\"))\n",
- " # echo to client side\n",
- " reply = bytearray('OK ... ', \"utf-8\") + data\n",
- " conn.sendall(reply)\n",
- " \n",
- " # came out of loop\n",
- " conn.close()\n",
- " \n",
- "# create an INET, STREAMing socket\n",
- "serversocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n",
- "# bind the socket to a public host, and a port\n",
- "# serversocket.bind((socket.gethostname(), 8080))\n",
- "# use localhost instead \n",
- "serversocket.bind((\"localhost\", 8080))\n",
- "# become a server socket\n",
- "serversocket.listen(5)\n",
+ "Dieses Kapitel handelt von der Iteration - der Möglichkeit, eine Folge von Anweisungen zu wiederholen. Wir haben eine Art der Iteration unter Verwendung der Rekursion schon im [Abschnitt 5.8](seminar05.ipynb#5.8-Rekursion) gesehen und eine andere Art, mit Hilfe der `for`-Schleife, in [Abschnitt 4.2](seminar04.ipynb#4.2-Einfache-Wiederholung). In diesem Kapitel lernen wir eine weitere Variante unter Verwendung der `while`-Anweisung kennen. Aber vorher schauen wir uns noch einmal die Zuweisung eines Wertes an eine Variable an. \n",
"\n",
+ "### Ihre Lernziele:\n",
"\n",
- "while True:\n",
- " # accept connections from outside\n",
- " (clientsocket, address) = serversocket.accept()\n",
- " # now do something with the clientsocket\n",
- " # in this case, we'll pretend this is a threaded server\n",
- " ct = client_thread(clientsocket)\n",
- " ct.run()\n",
+ "Beschreiben Sie in 2-3 Stichpunkten kurz was Sie im Seminar heute lernen wollen. Klicken Sie dazu doppelt auf diesen Text und bearbeiten Sie dann den Text:\n",
"\n",
- "serversocket.close()"
+ "- \n",
+ "- \n",
+ "- "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "Dieser Code enthält das Grundgerüst, um eine auf TCP basierende Serveranwendung zu programmieren. Wenn Sie den Code starten und sich dann mit Hilfe von Telnet mit der Anwendung verbinden (`telnet localhost 8080`), werden alle Eingaben an Sie zurückgespiegelt (\"echo\") und hier in Jupyter ausgegeben. Das ist eine sehr einfache Testanwendung, die aus Sicherheitsgründen nur von Ihrem Rechner aus erreichbar ist. \n",
+ "## Exkurs: Was mir an Python gefällt\n",
"\n",
- "Falls Ihr Rechner keinen Paketfilter (\"Firewall\") laufen hat und Sie die Zeile mit `localhost` auskommentieren und stattdessen die mit `socket.gethostbyname()` aktivieren, dann ist die Anwendung ggf. auch von anderen Rechnern erreichbar und stellt ziemlich sicher eine Sicherheitslücke dar. Gehen Sie also vorsichtig mit dieser Option um. "
+ "Wir wünschen Ihnen ein frohes Fest und einen guten Rutsch ins neue Jahr."
]
},
{
- "cell_type": "markdown",
+ "cell_type": "code",
+ "execution_count": null,
"metadata": {},
+ "outputs": [],
"source": [
- "## 7 Iteration\n",
+ "\"\"\" \n",
+ "Quelle: https://teampython.wordpress.com/2015/12/12/print-a-christmas-tree/\n",
+ "Python 3 version by antiloquax (2015), based on code from datamungeblog.com.\n",
+ "\"\"\"\n",
+ " \n",
+ "from random import choice\n",
+ "from random import random\n",
+ " \n",
+ "# If you change this, use an odd number.\n",
+ "size = 21\n",
+ "\n",
+ "# Probability that a character will be green.\n",
+ "prob_gr = 0.6\n",
+ "# Colour codes.\n",
+ "colours = [31, 33, 34, 35, 36, 37]\n",
+ "# Characters to use for decorations. Experiment with these.\n",
+ "# The chr(169) and chr(174) characters may not work in all terminals\n",
+ "# (extended ASCII, c and r in a circle).\n",
+ "decs = ['@', '&', '*', chr(169), chr(174)]\n",
+ "\n",
+ "# Format string for printing blinking characters.\n",
+ "blink_col = \"\\033[5;{0}m{1}\\033[0m\"\n",
+ "# String to print a green octothorpe ('#').\n",
+ "leaf = \"\\033[32m#\\033[0m\"\n",
+ "\n",
+ "# Width of the tree, will grow by 2 each time.\n",
+ "width = 1\n",
+ "# Initialise the tree string, with a star at the top.\n",
+ "tree = \"\\n{}*\\n\".format(' ' * (size))\n",
+ "\n",
+ "\"\"\" Main Loop starts now.\"\"\"\n",
+ " \n",
+ "\"\"\" We can't use the normal \"format\" centering approach:\n",
+ " (\"{:^nn}\".format(string) where \"nn\" is the width of the line), \n",
+ " with these ansi codes. This is because Python sees the strings as being\n",
+ " more than one character long (15 & 10 for baubles and leaves).\"\"\"\n",
+ "\n",
+ "# Loop from (size - 1) down to 0, using the counter as the padding size.\n",
+ "for pad in range(size - 1, -1, -1):\n",
+ " # Increase the width of the tree by 2.\n",
+ " width += 2\n",
+ " \n",
+ " # Put the characters for the line in \"temp\".\n",
+ " temp = \"\"\n",
+ " for j in range(width):\n",
+ " # Make some leaves.\n",
+ " if random() < prob_gr:\n",
+ " temp += leaf\n",
+ " # And also some baubles.\n",
+ " else:\n",
+ " temp += blink_col.format(choice(colours), choice(decs))\n",
"\n",
- "Dieses Kapitel ist eine Ãœbersetzung des [Kapitels 7 \"Iteration\"](http://greenteapress.com/thinkpython2/html/thinkpython2008.html) von Allen B. Downey. \n",
+ " # Add that string to the line, with padding.\n",
+ " tree += \"{0}{1}\\n\".format(' ' * pad, temp)\n",
"\n",
- "Dieses Kapitel handelt von der Iteration - der Möglichkeit, eine Folge von Anweisungen zu wiederholen. Wir haben eine Art der Iteration unter Verwendung der Rekursion schon im [Abschnitt 5.8](seminar05.ipynb#5.8-Rekursion) gesehen und eine andere Art, mit Hilfe der `for`-Schleife, in [Abschnitt 4.2](seminar04.ipynb#4.2-Einfache-Wiederholung). In diesem Kapitel lernen wir eine weitere Variante unter Verwendung der `while`-Anweisung kennen. Aber vorher schauen wir uns noch einmal die Zuweisung eines Wertes an eine Variable an. "
+ "# Add a \"trunk\" of 2 lines and return.\n",
+ "print(tree + \"{0}{1}\\n\".format(' ' * (size - 1), \"000\") * 2)\n",
+ "print(\"\\x46\\x72\\x6f\\x68\\x65\\x20\\x46\\x65\\x73\\x74\\x74\\x61\\x67\\x65\\x21\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "[Und noch viele weitere schöne Beispiele](https://codegolf.stackexchange.com/questions/15860/)"
]
},
{
@@ -117,9 +138,9 @@
"\n",
"An dieser Stelle wollen wir auf eine häufige Ursache für Verwechslungen hinweisen: Da Python das Gleichheitszeichen (`=`) für die Zuweisung verwendet, ist es verlockend, eine Anweisung wie `a = b` wie eine mathematische Aussage der Gleichheit zu interpretieren, das heisst, die Behauptung, dass `a` und `b` gleich seien. Aber diese Interpretation ist falsch! \n",
"\n",
- "Erstens ist Gleichheit eine symmetrische Beziehung und die Zuweisung ist es nicht. Beispielsweise gilt in der Mathematik: wenn $a=7$, dann ist auch $7=a$. Aber in Python ist die Anweisung `a = 7` erlaubt und `7 = a` ist es nicht. \n",
+ "Zum Einen ist Gleichheit eine symmetrische Beziehung und die Zuweisung ist es nicht. Beispielsweise gilt in der Mathematik: wenn $a=7$, dann ist auch $7=a$. Aber in Python ist die Anweisung `a = 7` erlaubt und `7 = a` ist es nicht. \n",
"\n",
- "Außerdem ist in der Mathematik eine Aussage über die Gleichheit entweder wahr oder falsch und gilt durchgängig. Wenn $a = b$ jetzt gilt, dann wird $a$ stets gleich $b$ sein. Aber in Python kann eine Zuweisung zwei Variablen gleich machen, sie müssen aber nicht durchgängig gleich bleiben:\n"
+ "Zum Anderen ist in der Mathematik eine Aussage über die Gleichheit entweder wahr oder falsch und gilt durchgängig. Wenn $a = b$ jetzt gilt, dann wird $a$ stets gleich $b$ sein. In Python kann eine Zuweisung zwei Variablen gleich machen, sie müssen aber nicht durchgängig gleich bleiben:\n"
]
},
{
@@ -138,7 +159,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "Die dritte Zeile ändert den Wert von `a` aber dadurch ändert sich nicht der Wert von `b`, so dass die beiden Variablen nicht mehr gleich sind.\n",
+ "Die dritte Zeile ändert den Wert von `a`, aber dadurch ändert sich nicht der Wert von `b`, so dass die beiden Variablen nicht mehr gleich sind.\n",
"\n",
"Variablen neue Werte zuzuweisen ist oft nützlich, aber Sie sollten vorsichtig damit umgehen. Wenn sich die Werte von Variablen häufig ändern, ist der Code schwerer zu lesen und zu debuggen. "
]
@@ -205,9 +226,9 @@
"\n",
"Computer werden häufig zur Automatisierung sich wiederholender Aufgaben genutzt. Identische oder ähnliche Aufgaben zu wiederholen ohne dabei Fehler zu machen, ist etwas was Computer sehr gut können und Menschen eher schlecht. In einem Computerprogramm wird die Wiederholung auch als **Iteration** bezeichnet. \n",
"\n",
- "Wir haben bereits zwei Funktionen gesehen, `countdown` und `print_t`, die mit Hilfe einer Rekursion eine Wiederholung durchführen. Da Wiederholung sehr häufig benötigt wird, gibt es in Python Sprachkonstrukte die das vereinfachen. Eines ist die `for`-Anweisung, die wir in [Abschnitt 4.2](seminar04.ipynb#4.2-Einfache-Wiederholung) kennengelernt haben. Darauf kommen wir später noch einmal zurück.\n",
+ "Wir haben bereits zwei Funktionen gesehen, `countdown` und `print_t`, die mit Hilfe einer Rekursion eine Wiederholung durchführen. Da Wiederholung sehr häufig benötigt wird, gibt es in Python Sprachkonstrukte, die das vereinfachen. Eines ist die `for`-Anweisung, die wir in [Abschnitt 4.2](seminar04.ipynb#4.2-Einfache-Wiederholung) kennengelernt haben. Darauf kommen wir später noch einmal zurück.\n",
"\n",
- "Eine andere Möglichkeit ist die `while`-Anweisung. Dies ist eine Version von `countdown` die eine `while`-Schleife verwendet:"
+ "Eine andere Möglichkeit ist die `while`-Anweisung. Dies ist eine Version von `countdown`, die eine `while`-Schleife verwendet:"
]
},
{
@@ -230,17 +251,17 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "Wir können die `while`-Anweisung fast so lesen, als wäre es natürliche Sprache: \"Solange `n` größer als 0 ist, zeige den Wert von `n` und dann dekrementiere `n`. Sobald 0 erreicht ist, gib das Wort `Abheben!` aus.\"\n",
+ "Wir können die `while`-Anweisung fast so lesen, als wäre es natürliche Sprache: \"Solange `n` größer als 0 ist, zeige den Wert von `n` an und dann dekrementiere `n`. Sobald 0 erreicht ist, gib das Wort `Abheben!` aus.\"\n",
"\n",
"Der Kontrollfluss der `while`-Schleife etwas formaler ausgedrückt sieht so aus:\n",
"\n",
"1. Bestimme ob die Bedingung wahr oder falsch ist.\n",
"2. Wenn die Bedingung unwahr ist, beende die `while`-Schleife und fahre mit der Ausführung der nächsten Anweisung nach der eingerückten Folge von Anweisungen fort.\n",
- "3. Wenn die Bedingung wahr ist, führe die eingerückte Folge von Anweisungen im Schleifenrumpf aus und gehe dann zu Schritt 1.\n",
+ "3. Wenn die Bedingung wahr ist, führe die eingerückte Folge von Anweisungen im Schleifenrumpf aus und gehe dann zu Schritt 1 zurück.\n",
"\n",
"Diese Art von Kontrollfluss wird Schleife genannt, weil der dritte Schritt wieder zum ersten Schritt springt und damit den Kreis (Schleife) schließt. (Im Englischen Original passt es besser: *This type of flow is called a loop because the third step loops back around to the top*.)\n",
"\n",
- "Der Schleifenrumpf sollte den Wert einer oder mehrerer Variablen ändern, so dass die Bedingung irgendwann einmal unwahr wird und die Schleife beendet wird. Ansonsten wiederholt sich die Schleife für immer, was **Endlosschleife** (*infinite loop*) genannt wird.\n",
+ "Der Schleifenrumpf sollte den Wert einer oder mehrerer Variablen ändern, sodass die Bedingung irgendwann einmal unwahr wird und die Schleife beendet wird. Ansonsten wiederholt sich die Schleife für immer, was **Endlosschleife** (*infinite loop*) genannt wird.\n",
"\n",
"\n",
"\n",
@@ -290,7 +311,8 @@
"source": [
"Da `n` manchmal wächst und manchmal schrumpft gibt es keinen offensichtlichen Beweis, dass `n` jemals 1 erreichen wird oder das Programm beendet wird. Für einige bestimmte Werte von `n` können wir zeigen, dass das Programm beendet wird. Wenn beispielsweise der Startwert eine Potenz von 2 ist (2, 4, 8, 16, 32, ...), dann ist `n` bei jedem Schleifendurchlauf eine gerade Zahl (und wird daher halbiert) bis die Schleife den Wert 1 erreicht. Das eben genannte Beispiel endet mit einer solchen Folge, die mir der Zahl 16 beginnt.\n",
"\n",
- "Die schwierige Frage ist, ob wir beweisen können, dass dieses Programm für *jeden* positiven Wert von `n` beendet wird. Bis jetzt hat es noch niemand geschafft, dies zu beweisen *oder* das Gegenteil zu beweisen (siehe https://de.wikipedia.org/wiki/Collatz-Problem).\n",
+ "Die schwierige Frage ist, ob wir beweisen können, dass dieses Programm für *jeden* positiven Wert von `n` beendet wird. Bis jetzt hat es noch niemand geschafft, dies zu beweisen. \n",
+ "Es hat aber auch noch niemand geschafft das Gegenteil zu beweisen. [Collatz-Problem](https://de.wikipedia.org/wiki/Collatz-Problem).\n",
"\n",
"\n",
"\n",
@@ -319,9 +341,9 @@
"source": [
"### 7.4 `break`\n",
"\n",
- "Manchmal wissen wir nicht, dass es Zeit wird eine Schleife zu beenden, bevor wir den Schleifenrumpf nicht schon zur Hälfte ausgeführt haben. In einem solchen Fall können wir die `break`-Anweisung nutzen, um eine Schleife zu verlassen.\n",
+ "Manchmal wissen wir nicht, dass es Zeit wird eine Schleife zu beenden, bis wir den Schleifenrumpf bereits zur Hälfte ausgeführt haben. In einem solchen Fall können wir die `break`-Anweisung nutzen, um eine Schleife zu verlassen.\n",
"\n",
- "Nehmen wir beispielsweise an, wir wollen eine Eingabe von der Nutzerin einlesen bis Sie `fertig` eingibt. Dann könnten wir folgendes schreiben:"
+ "Nehmen wir beispielsweise an, wir wollen eine Eingabe von der Nutzer_in einlesen bis sie `fertig` eingibt. Dann könnten wir folgendes schreiben:"
]
},
{
@@ -345,7 +367,7 @@
"source": [
"Die Schleifenbedingung ist `True`, was stets wahr ist, daher läuft die Schleife so lange, bis die `break`-Anweisung erreicht wird.\n",
"\n",
- "Bei jedem Durchlauf wird die Nutzerin aufgefordert, etwas einzugeben. Wenn Sie `fertig` eingibt, dann beendet die `break`-Anweisung die Schleife. Ansonsten gibt das Programm einfach nur aus, was die Nutzerin eingegeben hat und geht zurück zum Anfang der Schleife. Probieren Sie es selbst einmal aus.\n",
+ "Bei jedem Durchlauf wird die Nutzer_in aufgefordert, etwas einzugeben. Wenn Sie `fertig` eingibt, dann beendet die `break`-Anweisung die Schleife. Ansonsten gibt das Programm einfach nur aus, was die Nutzer_in eingegeben hat und geht zurück zum Anfang der Schleife. Probieren Sie es selbst einmal aus.\n",
"\n",
"Diese Art eine `while`-Schleife zu nutzen ist üblich, denn wir können die Bedingung überall innerhalb der Schleife prüfen (nicht nur am Anfang) und wir können die Abbruchbedingung positiv formulieren (\"beende die Schleife, wenn folgendes passiert\") statt negativ (\"fahre fort bis folgendes passiert\")."
]
@@ -515,7 +537,7 @@
"\n",
"Aber wenn Sie \"faul\" waren, haben Sie vielleicht ein paar Tricks gelernt. Beispielsweise kann man das Produkt einer Zahl $n$ mit 9 berechnen, indem man $n-1$ als erste Ziffer des Ergebnisses aufschreibt und dann $10-n$ als zweite Ziffer anhängt. Dieser Trick ist eine allgemeine Lösung, um jede Zahl mit nur einer Ziffer mit 9 zu multiplizieren. Das ist ein Algorithmus!\n",
"\n",
- "Genauso sind die Verfahren zur schriftlichen Addition (mit Übertrag), Subtraktion und Division Algorithmen. Eine Eigenschaft von Algorithmen ist, dass Sie keine Intelligenz benötigen, um ausgeführt zu werden. Sie sind mechanische Prozesse bei denen jeder Schritt vom vorherigen mittels einfacher und eindeutiger Regeln folgt.\n",
+ "Genauso sind die Verfahren zur schriftlichen Addition (mit Übertrag), Subtraktion und Division Algorithmen. Eine Eigenschaft von Algorithmen ist, dass Sie keine Intelligenz benötigen, um ausgeführt zu werden. Sie sind mechanische Prozesse bei denen jeder Schritt auf den vorherigen mittels einfacher und eindeutiger Regeln folgt.\n",
"\n",
"Algorithmen auszuführen ist langweilig aber sie zu entwerfen ist interessant, intellektuell herausfordernd und ein wesentlicher Teil der Informatik.\n",
"\n",
@@ -530,7 +552,7 @@
"\n",
"Sobald Sie größere Programme schreiben werden Sie bemerken, dass Sie mehr Zeit mit Debuggen verbringen. Mehr Programmcode bedeutet halt auch, dass es mehr Möglichkeiten gibt, einen Fehler zu machen und mehr Stellen, an denen sich \"Bugs\" verstecken können.\n",
"\n",
- "Eine Möglichkeit die Zeit für das Debuggen zu reduzieren ist \"Debugging durch Halbieren\" (binäre Suche). Wenn Ihr Programm beispielsweise 100 Zeilen hat und Sie jede Zeile einzeln prüfen würden, dann bräuchten Sie 100 Schritte zum Debuggen.\n",
+ "Eine Möglichkeit die Zeit für das Debuggen zu reduzieren ist \"Debugging durch Halbieren\" (denken Sie an die binäre Suche). Wenn Ihr Programm beispielsweise 100 Zeilen hat und Sie jede Zeile einzeln prüfen würden, dann bräuchten Sie 100 Schritte zum Debuggen.\n",
"\n",
"Stattdessen können Sie versuchen, das Problem zu halbieren. Gehen Sie (ungefähr) zur Hälfte des Programms und suchen Sie dort nach einem Zwischenwert (eine Variable), den Sie überprüfen können. Fügen Sie eine `print`-Anweisung, die den Zwischenwert ausgibt (oder etwas anderes, was einen prüfbare Auswirkung hat), hinzu und starten Sie das Programm.\n",
"\n",
@@ -551,7 +573,7 @@
"\n",
"- Neuzuweisung: \n",
"- Aktualisierung:\n",
- "- Initialisierung:\n",
+ "- Initialisierung: Das Erstellen einer Variablen und die damit verbundene erste Zuweisung eines Wertes\n",
"- inkrementieren:\n",
"- dekrementieren:\n",
"- Iteration:\n",
@@ -623,6 +645,96 @@
"test_square_root()"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "([2038](https://xkcd.com/607/), Randall Munroe)\n",
+ "\n",
+ "\n",
+ "\n",
+ "([Spoiler Alert](https://xkcd.com/109/), Randall Munroe)\n",
+ "\n",
+ "\n",
+ "1. Schreiben Sie den Kopf der Funktion, überlegen Sie welche Argumente der Funktion übergeben müssen.\n",
+ "2. Kopieren Sie, wie oben bereits erwähnt die Funktion. \n",
+ "3. Wenn Sie das Notebook aufmerksam gelesen haben, werden Sie sich an einige Verbesserungen erinnern, die wir vornehmen müssen. \n",
+ "4. Vor allem heißt das x und y mit der `abs()`-Funktion zu vergleichen, also zu schreiben `abs(x-y)<epsilon` wobei Sie einen Wert für epsilon wählen müssen, der klein genug ist. Fügen Sie diese Änderungen in Ihren Code ein.\n",
+ "5. Wählen Sie einen geeigneten Wert für x in Abhängigkeit von a. Da fast jeder Wert funktioniert, können Sie ihn frei wählen, sie müssen lediglich sicherstellen, dass x ungleich null ist.\n",
+ "6. Vergessen Sie nicht Ihre Funktion mit Werten zu testen, die Sie überprüfen können. \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def mysqrt(a):\n",
+ " if a==1:\n",
+ " x=a\n",
+ " else:\n",
+ " x=a-1\n",
+ " \n",
+ " epsilon=0.00000000001\n",
+ " while True:\n",
+ " y=(x+a/x)/2\n",
+ " if abs(y-x) < epsilon:\n",
+ " break\n",
+ " x=y\n",
+ " return x\n",
+ " \n",
+ " \n",
+ "mysqrt(25)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Wenn die von Ihnen geschriebene Funktion richtig funktiniert, können Sie an der gewünschten Vergleichstabelle arbeiten. Dazu können Sie folgendermaßen ansetzen:\n",
+ "\n",
+ "\n",
+ "1. Der Kopf der Funktion ist bereits gegeben, aber Sie können bereits den Tabellenkopf schreiben. Dafür schreiben Sie eine `print`-Anweisung für jede Zeile des Tabellenkopfs.\n",
+ "2. Als nächstes müssen Sie entscheiden ob Sie die Tabelle von oben ausgeben wollen, dann muss a die Werte 1 bis 9 annehmen - Sie brauchen eine Schleife - oder ob Sie die Tabelle für ein beliebiges a berechnen wollen, dann müssen Sie User-Input einrichten.\n",
+ "3. Wir planen für die Schleife, für diesen Fall können Sie eine `While` oder eine `For` Schleife verwenden. \n",
+ "4. Prüfen Sie zunächst ob beide Funktionen Werte zurückgeben. Dies ist für die Pythonfunktion der Fall, trifft es auch auf Ihre Funktion zu? Wenn nicht ergänzen Sie die `return`-Anweisung an geeigneter Stelle.\n",
+ "5. Weißen Sie die beiden Funktionen und damit ihre Rückgabewerte neuen Funktionen zu. \n",
+ "6. Berechnen Sie die Differenz zwischen `mysqrt()` und `math.sqrt()` und speichern Sie diese in einer neuen Variablen\n",
+ "7. Für ein nachvollziehbares `a` testen Sie jetzt einmal die 3 Ausgaben. \n",
+ "8. Fügen Sie die `print` Anweisung hinzu, die die einzelnen Tabellenzeilen ausgibt. \n",
+ "9. Vergessen Sie nicht den Wert für a bei jedem Schleifendurchlauf zu erhöhen. \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import math\n",
+ "def test_square_root():\n",
+ " a=1.0\n",
+ " print('a mysqrt(a) math.sqrt(a) diff')\n",
+ " print('- --------- ------------ ----')\n",
+ " while a<10:\n",
+ " E= mysqrt(a)\n",
+ " M= math.sqrt(a)\n",
+ " if E<M:\n",
+ " diff=M-E\n",
+ " else:\n",
+ " diff=E-M\n",
+ " E=str(E)\n",
+ " M=str(M)\n",
+ " print(a,E,(18-len(E))*' ',M,(18-len(M))*' ',diff)\n",
+ " a=a+1\n",
+ "\n",
+ " \n",
+ "test_square_root()"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {},
@@ -678,6 +790,42 @@
"# Implementieren Sie hier die Funktion eval_loop"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "([Spoiler Alert](https://xkcd.com/109/), Randall Munroe)\n",
+ "\n",
+ "1. Schreiben Sie den Funktionskopf\n",
+ "2. Richten Sie die Nutzereingabe ein und weißen Sie diese einer Variablen zu, damit wir den Input weiter verwenden können. \n",
+ "3. Da der Nutzer mehrfach eine Eingabe machen soll, muss diese Zuweißung innerhalb einer Schleife stattfinden.\n",
+ "4. Überlegen Sie welche Schleife Sie verwenden müssen, was ist hier Ihre Abbruchbedingung? Ist Sie positiv oder negativ?\n",
+ "5. Wenn `fertig` eingegeben wird, soll der letzte berechnete Wert zurückgegeben werden, daher muss dieser in einer Variablen temporär gespeichert werden.\n",
+ "6. Wenn nicht `fertig` eingegeben wird, wird der neue Ausdruck evaluiert und der Wert der zuvor in der temporären Variablen gespeichert war überschrieben. \n",
+ "7. Vergessen Sie nicht, dass die temporäre Variable initialisiert werden muss, bevor wir sie zum Speichern von Werten verwenden können. \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def eval_loop():\n",
+ " Eval=0\n",
+ " while True:\n",
+ " line = input('> ')\n",
+ " if line == 'fertig':\n",
+ " return(Eval)\n",
+ " break\n",
+ " Eval=eval(line)\n",
+ " print(Eval)\n",
+ " print('Fertig!')\n",
+ " \n",
+ "eval_loop()"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {},
@@ -694,9 +842,74 @@
"\n",
"(Eventuell ist die Formel [in der Original-Aufgabenstellung](http://greenteapress.com/thinkpython2/html/thinkpython2008.html#hevea_default541) besser zu lesen.)\n",
"\n",
- "Schreiben Sie eine Funktion `estimate_pi` die diese Formel nutzt, um einen Näherungswert für $\\pi$ zu berechnen und zurückzugeben. Sie sollten eine `while`-Schleife nutzen, um die Terme der Summe zu solange berechnen, bis der letzte Term kleiner ist als `1e-15` (was die Python-Notation für $10^{-15}$ ist). Sie können Ihr Ergebnis prüfen, indem Sie es mit `math.pi` vergleichen.\n",
+ "Schreiben Sie eine Funktion `estimate_pi` die diese Formel nutzt, um einen Näherungswert für $\\pi$ zu berechnen und zurückzugeben. Sie sollten eine `while`-Schleife nutzen, um die Terme der Summe zu solange berechnen, bis der letzte Term kleiner ist als `1e-15` (was die Python-Notation für $10^{-15}$ ist). Sie können Ihr Ergebnis prüfen, indem Sie es mit `math.pi` vergleichen.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "([Spoiler Alert](https://xkcd.com/109/), Randall Munroe)\n",
+ "\n",
+ "1. Auf den ersten Blick sieht diese Formel sehr überwältigend aus. Machen Sie sich keine Sorgen, wir können die Formel in ihre einzelnen Bestandteile aufsplitten und diese einzeln berechnen.\n",
+ "2. Wie Sie sehen können wird in der Formel zweimal eine Fakultät berechnet. Dafür können Sie die Funktion, die Sie in Seminar 6 geschrieben verwenden. \n",
+ "3. Berechnen Sie zuerst die Konstante vor dem Summenzeichen und speichern Sie den Wert in einer Variablen. In unserer Lösung wird diesè Variable `faktor` genannt. \n",
+ "4. Die `while`-Schleife ersetzt das Summenzeichen. Überlegen Sie sich wie Sie die Bedingung formulieren müssen. Die Abbruchbedingung ist `abs(term)<1e-15` \n",
+ "5. Das Summenzeichen berechnet Werte für k=0 aufwärts (unedlich anstrebend), also muss die Schleife k hochzählen. \n",
+ "6. Alles was hinter dem Summenzeichen steht wird in der Schleife berechnet.\n",
+ "7. In jedem Durchgang der Schleife werden Zähler (hier `num`) und Nenner (hier `den`) einzeln berechnet und je einer Variablen zugewiesen\n",
+ "8. Anschließend wird der Wert des Terms im aktuellen Schleifendurchlauf berechnet, indem die Konstante vor dem Summenzeichen mit dem Bruch hinter dem Summenzeichen multipliziert wird. \n",
+ "9. Dieser Wert wird in jedem Schleifendurchlauf auf das Gesamtergebnis addiert\n",
+ "10. Danach wird geprüft ob die Abbruchbedingung erfüllt ist. \n",
+ "11. Da diese Formel 1/$\\pi$ berechnet, muss 1/ergebnis gerechnet werden um $\\pi$ zu erhalten. \n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import math\n",
+ "\n",
+ "def fakultaet(n):\n",
+ " if not isinstance(n, int):\n",
+ " print('Die Fakultät ist nur für ganze Zahlen definiert.')\n",
+ " return None\n",
+ " elif n < 0:\n",
+ " print('Die Fakultät für negative ganze Zahlen ist nicht definiert.')\n",
+ " return None\n",
+ " elif n == 0:\n",
+ " return 1\n",
+ " else:\n",
+ " return n * fakultaet(n-1)\n",
+ "\n",
+ "def estimate_pi():\n",
+ " faktor = 2 * math.sqrt(2) / 9801 \n",
+ " ergebnis = 0\n",
+ " k = 0\n",
+ " while True:\n",
+ " num = fakultaet(4*k) * (1103 + 26390*k)\n",
+ " den = fakultaet(k)**4 * 396**(4*k)\n",
+ " term = faktor * num / den\n",
+ " ergebnis= ergebnis + term\n",
+ " if abs(term) < 1e-15:\n",
+ " break\n",
+ " k =k + 1\n",
+ " \n",
+ " fast_pi= 1/ ergebnis\n",
+ " return fast_pi\n",
"\n",
- "Lösung: http://thinkpython2.com/code/pi.py"
+ "print(estimate_pi())"
]
},
{
diff --git a/notebooks/seminar08.ipynb b/notebooks/seminar08.ipynb
index eb9421a4363a7c338809913e5242ad078c739016..36bf23c90d4be5a9d5cd460243b9b7d39fdb3a87 100644
--- a/notebooks/seminar08.ipynb
+++ b/notebooks/seminar08.ipynb
@@ -1184,11 +1184,11 @@
"\n",
"Hier gibt es keine Lösungsansätze, schauen sie sich die Lösungen von unten an und versuchen Sie nachzuvollziehen wie der tatsächliche Effekt entsteht. Fragen Sie dabei auf jeden Fall nach, wenn Sie etwas nicht verstehen!\n",
"\n",
- " - lowercase1 prüft ob alle Zeichen Kleinbuchstaben sind.\n",
- " - lowercase2 prüft ob `c`ein Kleinbuchstabe ist und gibt immer true -als string, nicht als boolscher Wert- zurück.\n",
- " - lowercase3 prüft ob der letzte Buchstabe ein Kleinbuchstabe ist.\n",
- " - lowercase4 prüft ob es Kleinbuchstaben gibt, diese Funktion macht das was sie soll.\n",
- " - lowercase5 püft ob der erste Buchstabe ein Kleinbuchstabe ist. "
+ " - any_lowercase1 prüft ob alle Zeichen Kleinbuchstaben sind.\n",
+ " - any_lowercase2 prüft ob `c`ein Kleinbuchstabe ist und gibt immer true – als Zeichenkette, nicht als boolscher Wert – zurück.\n",
+ " - any_lowercase3 prüft ob der letzte Buchstabe ein Kleinbuchstabe ist.\n",
+ " - any_lowercase4 prüft ob es Kleinbuchstaben gibt, diese Funktion macht das was sie soll.\n",
+ " - any_lowercase5 püft ob der erste Buchstabe ein Kleinbuchstabe ist. "
]
},
{
diff --git a/notebooks/seminar09.ipynb b/notebooks/seminar09.ipynb
index 2cab1ce6a9383467226f8b1b13f3ad1ce77c43e8..014c133750954942d3555d0374558e21a1ad36d2 100644
--- a/notebooks/seminar09.ipynb
+++ b/notebooks/seminar09.ipynb
@@ -6,11 +6,22 @@
"source": [
"# Seminar Problemorientierte Programmierung\n",
"\n",
- "## Exkurs: Was mir an Python gefällt\n",
+ "## 9 Fallstudie: Wortspiele\n",
+ "[Chapter 9: Case study: Word play](http://greenteapress.com/thinkpython2/html/thinkpython2010.html)\n",
+ "\n",
+ "In diesem Abschnitt gibt es die zweite Fallstudie. In dieser werden Wort-Rätsel gelöst, in denen Wörter mit bestimmten Eigenschaften gesucht werden. Beispielsweise finden wir die längsten Palindrome und suchen nach Wörtern, deren Buchstaben in alphabetischer Reihenfolge erscheinen. Und wir lernen eine weitere Entwicklungsmethode kennen: Rückführung auf ein bereits gelöstes Problem.\n",
+ "\n",
+ "### Ihre Lernziele:\n",
+ "\n",
+ "Beschreiben Sie in 2-3 Stichpunkten kurz was Sie im Seminar heute lernen wollen. Klicken Sie dazu doppelt auf diesen Text und bearbeiten Sie dann den Text:\n",
"\n",
- "In dieser Rubrik, die immer am Anfang eines Kapitels steht, möchte ich Ihnen zeigen, wofür ich Python nutze und warum ich es mag. Sie werden vielleicht noch nicht verstehen, was ich genau mache, aber Sie sehen damit schon einmal die Möglichkeiten von Python und können später darauf zurückgreifen. Da dies auch ein Exkurs ist, können Sie diese Rubrik gerne auch erst einmal überspringen.\n",
+ "- \n",
+ "- \n",
+ "- \n",
"\n",
- "Das [Modul os](https://docs.python.org/3/library/os.html) stellt Funktionen bereit, um Funktionalitäten des Betriebssystems zu nutzen. Beispielsweise können wir damit Verzeichnis-Inhalte auflisten, durch Verzeichnisse navigieren, Informationen zu Dateien bekommen und Dateieigenschaften verändern. Das folgende Programm gibt eine Liste aller Jupyter-Notebooks im aktuellen Verzeichnis zusammen mit der Dateigröße aus und berechnet die Gesamtgröße der Dateien:"
+ "## Exkurs: Was mir an Python gefällt\n",
+ "\n",
+ "Dieser Code enthält das Grundgerüst, um eine auf TCP basierende Serveranwendung zu programmieren."
]
},
{
@@ -19,33 +30,67 @@
"metadata": {},
"outputs": [],
"source": [
- "import os\n",
- "\n",
- "# Tabellenkopf ausgeben\n",
- "print(\"Bytes\\tName\")\n",
- "print(\"--------------------------------------------------------------\")\n",
- "\n",
- "# Gesamtgröße in Bytes\n",
- "bytes_sum = 0\n",
+ "# Quellen: https://docs.python.org/3/howto/sockets.html und \n",
+ "# http://www.binarytides.com/python-socket-server-code-example/\n",
+ "\n",
+ "import socket\n",
+ "\n",
+ "# function for handling connections. This will be used to create threads\n",
+ "def client_thread(conn):\n",
+ " # sending message to connected client\n",
+ " conn.send(bytearray('Welcome to the server. Type something and hit enter\\n', \"utf-8\")) #send only takes string\n",
+ " \n",
+ " # infinite loop so that function do not terminate and thread do not end.\n",
+ " while True:\n",
+ " \n",
+ " # receiving from client\n",
+ " data = conn.recv(1024)\n",
+ " if not data: \n",
+ " break\n",
+ " # print on server side\n",
+ " print(data.decode(\"utf-8\"))\n",
+ " # echo to client side\n",
+ " reply = bytearray('OK ... ', \"utf-8\") + data\n",
+ " conn.sendall(reply)\n",
+ " \n",
+ " # came out of loop\n",
+ " conn.close()\n",
+ " \n",
+ "# create an INET, STREAMing socket\n",
+ "serversocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n",
+ "# bind the socket to a public host, and a port\n",
+ "# serversocket.bind((socket.gethostname(), 8080))\n",
+ "# use localhost instead \n",
+ "serversocket.bind((\"localhost\", 8080))\n",
+ "# become a server socket\n",
+ "serversocket.listen(5)\n",
+ "\n",
+ "\n",
+ "while True:\n",
+ " # accept connections from outside\n",
+ " (clientsocket, address) = serversocket.accept()\n",
+ " # now do something with the clientsocket\n",
+ " # in this case, we'll pretend this is a threaded server\n",
+ " ct = client_thread(clientsocket)\n",
+ " ct.run()\n",
+ "\n",
+ "serversocket.close()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Wenn Sie den Code starten und sich dann mit Hilfe von Telnet mit der Anwendung verbinden (telnet localhost 8080), werden alle Eingaben an Sie zurückgespiegelt (\"echo\") und hier in Jupyter ausgegeben. Das ist eine sehr einfache Testanwendung, die aus Sicherheitsgründen nur von Ihrem Rechner aus erreichbar ist.\n",
"\n",
- "# Inhalt des aktuellen Verzeichnisses durchlaufen\n",
- "for entry in os.scandir():\n",
- " if entry.is_file() and entry.name.endswith(\".ipynb\"):\n",
- " size = entry.stat().st_size\n",
- " bytes_sum +=size\n",
- " print(\"{:5d}\".format(size), entry.name, sep='\\t')\n",
- " \n",
- "print(\"--------------------------------------------------------------\")\n",
- "print(bytes_sum, \"bytes =\", bytes_sum/1000, \"kilobytes =\", bytes_sum/1000000, \"Megabytes\")"
+ "Falls Ihr Rechner keinen Paketfilter (\"Firewall\") laufen hat und Sie die Zeile mit localhost auskommentieren und stattdessen die mit socket.gethostbyname() aktivieren, dann ist die Anwendung ggf. auch von anderen Rechnern erreichbar und stellt ziemlich sicher eine Sicherheitslücke dar. Gehen Sie also vorsichtig mit dieser Option um."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "## 9 Fallstudie: Wortspiele\n",
"\n",
- "In diesem Abschnitt gibt es das zweite Fallbeispiel. In diesem werden Wort-Puzzles gelöst, in denen Wörter mit bestimmten Eigenschaften gesucht werden. Beispielsweise finden wir die längsten Palindrome und suchen nach Wörtern, deren Buchstaben in alphabetischer Reihenfolge erscheinen. Und wir lernen eine weitere Entwicklungsmethode kennen: Rückführung auf ein bereits gelöstes Problem.\n",
"\n",
"### 9.1 Wortlisten einlesen\n",
"\n",
@@ -53,7 +98,7 @@
"\n",
"Für die Übungen in diesem Abschnitt benötigen wir eine Liste deutscher Wörter. Es gibt sehr viele Wortlisten im Web, wir verwenden hier eine Liste des [Wortschatz-Projektes](http://wortschatz.uni-leipzig.de/) der Universität Leipzig. Laden Sie [diese Liste mit 10000 häufigen deutschen Wörtern](http://pcai056.informatik.uni-leipzig.de/downloads/etc/legacy/Papers/top10000de.txt) herunter und speichern Sie sie unter dem Dateinamen `top10000de.txt`.\n",
"\n",
- "Die Datei ist eine reine Textdatei, daher können wir sie mit einem Texteditor anschauen, aber wir können sie auch leicht mit Python einlesen. Die eingebaute Funktion `open` erwartet einen Dateiname als Parameter und gibt uns ein **Dateiobjekt** (*file object*) zurück, mit dessen Hilfe wir die Datei lesen können:"
+ "Die Datei ist eine reine Textdatei, daher können wir sie mit einem Texteditor anschauen. Wir können sie aber auch leicht mit Python einlesen. Die eingebaute Funktion `open` erwartet einen Dateiname als Parameter und gibt uns ein **Dateiobjekt** (*file object*) zurück, mit dessen Hilfe wir die Datei lesen können:"
]
},
{
@@ -64,7 +109,7 @@
"source": [
"fin = open('top10000de.txt', encoding=\"latin1\")\n",
"# Hinweis: der Parameter encoding gibt an, in welcher Zeichenkodierung\n",
- "# die Datei verfasst ist. I.A. sollten Dateien heute in Unicode codiert\n",
+ "# die Datei verfasst ist. Im Allgemeinen sollten Dateien heute in Unicode codiert\n",
"# sein, bei diesen ist in Python3 diese Angabe nicht notwendig.\n",
"# Leider ist die Datei vom Wortschatz-Projekt aber noch in der\n",
"# Latin1-Kodierung, so dass wir dies Python mitteilen müssen."
@@ -158,7 +203,7 @@
"source": [
"### 9.2 Ãœbung\n",
"\n",
- "Die Lösungen für die Aufgaben hier gibt es im nächsten Abschnitt. Bitte versuchen Sie zunächst, jede Aufgabe selbständig zu lösen, bevor sie eine der Lösungen anschauen.\n",
+ "Die Lösungen der Aufgaben gibt es wie gehabt unter der jeweiligen Aufgabe und mit ergänzender Theorie im nächsten Abschnitt. Bitte versuchen Sie zunächst, jede Aufgabe selbständig zu lösen, bevor sie eine der Lösungen anschauen.\n",
"\n",
"#### Aufgabe 1\n",
"\n",
@@ -178,7 +223,34 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "Am Ergebnis werden Sie merken, dass die Wortliste nicht ganz bereinigt ist und manche Zeilen Phrasen bestehend aus mehreren Wörtern enthalten. "
+ "Am Ergebnis werden Sie merken, dass die Wortliste nicht ganz bereinigt ist und manche Zeilen Phrasen bestehend aus mehreren Wörtern enthalten. \n",
+ "\n",
+ "\n",
+ "([Spoiler Alert](https://xkcd.com/109/), Randall Munroe)\n",
+ "\n",
+ "1. Öffnen Sie die Datei in einer neuen Variablen und rufen Sie diese im Funktionskopf auf.\n",
+ "2. Um zu überprüfen, ob ein Wort lang genug ist, müssen Sie jede Zeile einzeln aufrufen. Verwenden Sie dafür eine `for`- Schleife, die Sie zuvor gesehen haben.\n",
+ "3. Für jede Zeile müssen Sie nun prüfen ob die Bedungung erfüllt ist. Wie könnte diese Bedingung aussehen?\n",
+ "4. Wenn die Bedinung erfüllt ist, geben Sie die entsprechende Zeile mit einem `print`-Statement aus. Verwenden Sie nicht `return`, da Sie die Funktion so sofort beenden und nur das erste Element finden würden, dass die Bedingung erfüllt.\n",
+ "5. Schreiben Sie den Funktionsaufruf und schauen Sie sich das Ergebnis an."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fin = open('top10000de.txt', encoding=\"latin1\")\n",
+ "\n",
+ "def long(fin):\n",
+ " \"\"\"Findet Zeilen mit mehr als 20 Buchstaben aus einer beliebigen Wortliste im txt Format\"\"\"\n",
+ " for line in fin:\n",
+ " if len(line)>20:\n",
+ " print (line.strip())\n",
+ " \n",
+ " \n",
+ "long(fin)\n"
]
},
{
@@ -191,9 +263,7 @@
"\n",
"1939 hat [Ernest Vincent Wright](https://de.wikipedia.org/wiki/Ernest_Vincent_Wright) den englischen Roman *Gadsby* mit 50000 Wörtern veröffentlicht, von denen keines den Buchstaben \"e\" enthält. Da \"e\" der häufigste Buchstabe im Englischen ist, ist das eine beachtliche Leistung.\n",
"\n",
- "Tatsächlich ist's knifflig, was im Hirn ohn' das Symbol zu tun. (Im Englischen ist's wohl einfacher - im Original steht hier: *In fact, it is difficult to construct a solitary thought without using that most common symbol. It is slow going at first, but with caution and hours of training you can gradually gain facility.\n",
- "\n",
- "All right, I’ll stop now.*)\n",
+ "Tatsächlich ist's knifflig, was im Hirn ohn' das Symbol zu tun. (Im Englischen ist es wohl einfacher - im Original steht hier: *In fact, it is difficult to construct a solitary thought without using that most common symbol. It is slow going at first, but with caution and hours of training you can gradually gain facility. All right, I’ll stop now.*)\n",
"\n",
"Schreiben Sie eine Funktion `has_no_e` die `True` zurückgibt, wenn das übergebene Wort den Buchstaben \"e\" nicht enthält. (Denken Sie auch an den Großbuchstaben \"E\".)"
]
@@ -212,7 +282,14 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "Verändern Sie jetzt das Programm aus Aufgabe 1, so dass nur Wörter ausgegeben werden, die kein \"e\" enthalten und berechnen Sie den Anteil der Wörter in der Liste, die kein \"e\" enthalten."
+ "\n",
+ "\n",
+ "([Spoiler Alert](https://xkcd.com/109/), Randall Munroe)\n",
+ "\n",
+ "1. Schreiben Sie den Funktionskopf und legen Sie fest welche Rückgabewerte es gibt. (Wenn kein `e` vorkommt, `True`, sonst `False`.)\n",
+ "2. Um jeden Buchstaben in dem Wort zu prüfen, schreiben Sie eine `for`-Schleife, wie in [Abschnitt 8.3](seminar08.ipynb#Durchlauf-mit-einer-for-Schleife) gezeigt.\n",
+ "3. Prüfen Sie für jeden Buchstaben, ob er `e` ist. Denken Sie dabei daran, dass die Buchstaben sowohl groß als auch klein geschrieben sein können. Wenn der Buchhstabe `e` ist, kann der Test sofort abgebrochen und die Schleife mit `return False` verlassen werden.\n",
+ "4. Wenn in der Schleife nie eine `return`-Anweißung erreicht wird, wird die Schleife verlassen und `True` zurückgegeben."
]
},
{
@@ -221,7 +298,65 @@
"metadata": {},
"outputs": [],
"source": [
- "# Implementieren Sie hier Ihr Programm"
+ "def has_no_e(word):\n",
+ " for letter in word: \n",
+ " if letter == 'e':\n",
+ " return False\n",
+ " if letter == 'E':\n",
+ " return False\n",
+ " return True\n",
+ " \n",
+ "has_no_e('nicht')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Verändern Sie jetzt das Programm aus Aufgabe 1 so, dass nur Wörter ausgegeben werden, die kein \"e\" enthalten und berechnen Sie den Anteil der Wörter in der Liste, die kein \"e\" enthalten."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Implementieren Sie hier Ihr Programm\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "([Spoiler Alert](https://xkcd.com/109/), Randall Munroe)\n",
+ "\n",
+ "1. Gehen Sie hier analog zu Aufgabe 1 vor, kopieren Sie ruhig den Code, den Sie für Aufgabe 1 geschrieben haben, so verringern Sie die Gefahr von Tippfehlern.\n",
+ "2. Verändern Sie die `if`-Verzweigung so, dass Sie `has_no_e` aufruft und den Rückgabewert prüft. Liefert `has_no_e` `True` zurück wird das Wort ausgegeben.\n",
+ "3. Um den Anteil zu bestimmen, müssen wir zählen auf wie viele Worte die Bedingung zutrifft. Legen Sie dafür eine Variable an und initialisieren Sie sie mit 0.\n",
+ "4. Immer wenn Sie das Wort ausgeben inkrementieren Sie den Zähler.\n",
+ "5. Um den Anteil zu berechnen teilen Sie diese Variable durch die Gesamtmenge an Wörtern, in diesem Fall 10000. Vergessen Sie nicht die so berechnete Zahl auszugeben."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fin = open('top10000de.txt', encoding=\"latin1\")\n",
+ "def test(fin):\n",
+ " count=0\n",
+ " for line in fin:\n",
+ " if has_no_e(line):\n",
+ " count=count+1\n",
+ " print(line)\n",
+ " anteil=count/10000\n",
+ " print(anteil)\n",
+ " \n",
+ "test(fin)"
]
},
{
@@ -230,7 +365,9 @@
"source": [
"#### Aufgabe 3\n",
"\n",
- "Schreiben Sie eine Funktion `avoids` die ein Wort sowie eine Zeichenkette mit verbotenen Buchstaben erwartet und `True` zurückgibt, wenn im Wort keiner der verbotenen Buchstaben auftaucht. "
+ "Schreiben Sie eine Funktion `avoids` die ein Wort sowie eine Zeichenkette mit verbotenen Buchstaben erwartet und `True` zurückgibt, wenn im Wort keiner der verbotenen Buchstaben auftaucht. \n",
+ "\n",
+ "*Hinweis: mit der Methode `lower` können Sie eine Zeichenkette in Kleinbuchstaben umwandeln. `word.lower()` enthält also die gleichen Buchstaben wie `word`, nur halt als Kleinbuchstaben*\n"
]
},
{
@@ -247,9 +384,40 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "*Hinweis: mit der Methode `lower` können Sie eine Zeichenkette in Kleinbuchstaben umwandeln. `word.lower()` enthält also die gleichen Buchstaben wie `word`, nur halt als Kleinbuchstaben*\n",
"\n",
- "Verändern Sie Ihr Programm von Aufgabe 2, so dass Sie zunächst die Nutzerin bitten, die verbotenen Buchstaben einzugeben und dann drucken Sie die Anzahl der Wörter aus, die keine der Buchstaben enthalten."
+ "\n",
+ "([Spoiler Alert](https://xkcd.com/109/), Randall Munroe)\n",
+ "\n",
+ "\n",
+ "1. Diese Aufgabe ist eine Verallgemeinerung von `has_no_e`.\n",
+ "2. Auch in dieser Aufgabe muss das Wort Buchstabe für Buchstabe überprüft werden.\n",
+ "3. Der Vergleich findet allerdings nicht mit `e` statt, sondern mit dem zusätzlich eingegebenen Buchstaben.\n",
+ "4. Da wir im Vorfeld nicht wissen, um welchen Buchstaben es sich handelt, können wir nicht einfach zwei Tests durchführen, sondern müssen stattdessen das Wort vereinheitlichen. Nutzen Sie dazu `word.lower()`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def avoids(word, forbidden):\n",
+ " for letter in word.lower():\n",
+ " if letter in forbidden:\n",
+ " return False\n",
+ " return True\n",
+ "\n",
+ "\n",
+ "avoids(\"ad\", \"f,g,h\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "Verändern Sie Ihr Programm von Aufgabe 2, so dass Sie zunächst die Nutzer bitten, die verbotenen Buchstaben einzugeben und dann drucken Sie die Anzahl der Wörter aus, die keine der Buchstaben enthalten."
]
},
{
@@ -265,7 +433,38 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "Können Sie eine Kombination von fünf verbotenen Buchstaben finden, die die kleinste Anzahl an Wörtern ausschließt? (*Bestwert unter den 10000 Wörtern der Liste ist bisher 590.*)"
+ "Können Sie eine Kombination von fünf verbotenen Buchstaben finden, die die kleinste Anzahl an Wörtern ausschließt? (*Bestwert unter den 10000 Wörtern der Liste ist bisher 590.*)\n",
+ "\n",
+ "\n",
+ "\n",
+ "([Spoiler Alert](https://xkcd.com/109/), Randall Munroe)\n",
+ "\n",
+ "1. Auch dieser Test funktioniert analog zum ersten Test. Kopieren Sie die Funktion, geben Sie ihr einen neuen Namen und passen Sie sie an. Dadurch vermeiden Sie eventuelle Flüchtigkeitsfehler.\n",
+ "2. Aus der Aufgabenstellung geht hervor, dass wir eine Nutzereingabe brauchen. Verwenden Sie dafür `input`. \n",
+ "3. Stellen Sie sicher, dass die Eingabe aus `input` einer Variablen zugewießen wird.\n",
+ "4. Rufen Sie dann in der Schleife `avoids` mit dem User-Input auf. Um zu sehen, wie viele Worte Sie nicht ausgeschlossen haben, verwenden Sie den Zähler.\n",
+ "5. Geben Sie diesen Zähler nach Verlassen der `for`-Schleife einmalig aus."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fin = open('top10000de.txt', encoding=\"latin1\")\n",
+ "\n",
+ "def test2(fin):\n",
+ " forbidden=input(\"Geben Sie Buchstaben ein, die nicht vorkommen sollen:\\n\")\n",
+ " count=0\n",
+ " print(\"Dies sind die übrigen Worte:\")\n",
+ " for line in fin: \n",
+ " word=line.strip()\n",
+ " if avoids(word, forbidden):\n",
+ " count=count+1\n",
+ " print (word)\n",
+ " print (count)\n",
+ "test2(fin)"
]
},
{
@@ -291,7 +490,35 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "Können Sie einen Satz bilden, der nur die Buchstaben `acefhln` enthält?"
+ "\n",
+ "\n",
+ "([Spoiler Alert](https://xkcd.com/109/), Randall Munroe)\n",
+ "\n",
+ "1. Auch hier können Sie Code wiederverwenden. Überlegen Sie wie Sie den Code anpassen können.\n",
+ "2. Diesmal wollen Sie nicht prüfen, ob der Buchstabe verboten ist. Stattdessen interessiert uns, ob er erlaubt ist.\n",
+ "3. Sie müssen die Prüfung also negativ, nicht positiv formulieren. Wenn ein Buchstabe des Wortes nicht in der verfügbaren Liste zu finden ist, kann das Programm abbrechen und `False` zurück geben.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def uses_only(word, available):\n",
+ " for letter in word.lower(): \n",
+ " if letter not in available:\n",
+ " return False\n",
+ " return True\n",
+ "\n",
+ "uses_only(\"acefhln\", \"acefhln\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Können Sie einen Satz bilden, der nur die Buchstaben `acefhln` enthält? Nutzen Sie ihr Programm um alle Worte auf der Liste zu finden, die Sie verwenden dürfen."
]
},
{
@@ -303,6 +530,49 @@
"# Implementieren Sie hier Ihr Programm"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "([Spoiler Alert](https://xkcd.com/109/), Randall Munroe)\n",
+ "\n",
+ "1. Wie gehabt, können Sie Code wiederverwenden und es ist empfehlenswert, das zu tun, da Sie so viele Flüchtigkeitsfehler vermeiden können. Nehmen Sie am besten den Testcode, den Sie für `forbidden` verwendet haben.\n",
+ "2. Sie müssen den Testcode natürlich anpassen. Als erstes können Sie die `if`-Verzweigung verändern. Welche Funktion wird aufgerufen, um zu testen, ob ein Wort die Bedingung erfüllt?\n",
+ "3. Wenn Sie dies angepasst haben, schauen Sie, was Sie an die Funktion übergeben müssen. Das Wort wird automatisch in der Schleife übergeben, aber die Liste der verfügbaren Buchstaben müssen Sie manuell anpassen. Da eine Nutzereingabe nicht notwendig ist, können Sie der Variablen einfach einen String zuweißen, der alle erlaubten Buchstaben enthält.\n",
+ "4. Drucken Sie alle Worte aus, die die Bedingung erfüllen, und versuchen Sie aus den Worten einen Satz zu bilden.\n",
+ "*Hinweiß: Ich habe mich entschieden die Zählervariable zu behalten, da Sie mir sagt, wie viele Worte ich zur Verfügung habe. Dies ist nicht notwendig.*"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "\n",
+ "\n",
+ "fin = open('top10000de.txt', encoding=\"latin1\")\n",
+ "\n",
+ " \n",
+ " \n",
+ "def sentence(fin):\n",
+ " available=\"acefhln\"\n",
+ " count=0\n",
+ " for line in fin:\n",
+ " word=line.strip()\n",
+ " if uses_only(word, available):\n",
+ " count=count+1\n",
+ " print(line)\n",
+ " return count\n",
+ " \n",
+ "\n",
+ "sentence(fin)\n",
+ "\n",
+ "#Elf Fahnen lehnen an Helene\n",
+ "#Aber ich bin sicher Sie können einen besseren Satz bilden. Viel Erfolg!"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {},
@@ -321,6 +591,33 @@
" # Implementieren Sie hier die Funktion\n"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "([Spoiler Alert](https://xkcd.com/109/), Randall Munroe)\n",
+ "\n",
+ "1. Wenn Sie das Wort Buchstabe für Buchstabe durchgehen, können Sie sicherstellen, dass nur erlaubte Buchstaben verwendet werden. Können Sie so auch sicherstellen, dass alle Buchstaben verwendet werden? Probieren Sie es aus.\n",
+ "2. Da es so nicht möglich ist, überlegen Sie, wie Sie sicherstellen können, dass alle Buchstaben verwendet werden. Sie können dafür die Strukturen verwenden, die Sie bereits kennen. \n",
+ "3. Wir haben gesehen, dass wir unseren Buchstaben mit einer ganzen Liste an Buchstaben vergleichen können. In diesem Fall behandeln wir word.lower() als diese Liste und die Liste mit vorgegebenen Buchstaben als unser Wort. Gehen Sie die Liste also Buchstabe für Buchstabe durch und gleichen Sie Sie mit word.lower() ab. Überprüfen Sie wann `True` und wann `False` zurückgegeben wird."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def uses_all(word, required):\n",
+ " for letter in required: \n",
+ " if letter not in word.lower():\n",
+ " return False\n",
+ " return True\n",
+ "uses_all(\"Hallo\", \"ahlo\")"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {},
@@ -343,6 +640,41 @@
"source": [
"In der Ergebnisliste sollte das Wort `Argumentation` enthalten sein.\n",
"\n",
+ "\n",
+ "\n",
+ "([Spoiler Alert](https://xkcd.com/109/), Randall Munroe)\n",
+ "\n",
+ "1. Wie gehabt können Sie den Test kopieren. Bennenen Sie ihn um und passen Sie auf, dass Sie den Namen auch in dem Funktionsaufruf ändern. \n",
+ "2. Hier wird gefragt, wie viele Wörter alle Vokale enthalten, der Zähler ist also ein notwendiges Element der Funktion. \n",
+ "3. Wie müssen sie die `if`-Anweißung anpassen, was ist die zweite Variable, die Sie der Funktion übergeben?"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def all_vowels(fin):\n",
+ " required='aeiou'\n",
+ " count=0\n",
+ " for line in fin:\n",
+ " word=line.strip()\n",
+ " if uses_all(word, required):\n",
+ " count=count+1\n",
+ " print(line)\n",
+ " return count\n",
+ "\n",
+ "\n",
+ "\n",
+ "fin = open('top10000de.txt', encoding=\"latin1\")\n",
+ "all_vowels(fin)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
"#### Aufgabe 6\n",
"\n",
"Schreiben Sie eine Funktion `is_abecedarian` die `True` zurückgibt, wenn die Buchstaben in einem Wort in alphabetischer Reihenfolge auftauchen (doppelte Buchstaben sind erlaubt). "
@@ -358,6 +690,39 @@
" # Implementieren Sie hier die Funktion"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "\n",
+ "([Spoiler Alert](https://xkcd.com/109/), Randall Munroe)\n",
+ "\n",
+ "1. Hier gibt es verschiedene richtige Lösungen. Weiter unten werden 3 verschiedene Lösungen vorgestellt und es kann sein, dass sich Ihr Ansatzt von dem hier präsentierten unterscheiden. Das heißt nicht zwingend, dass Ihr Ansatz falsch ist. Schauen Sie sich gegebenenfalls die Lösung weiter unten an, wenn Sie sich unsicher sind.\n",
+ "2. Der hier verwendete Ansatz verwendet eine `for`-Schleife. \n",
+ "3. Es wird eine Hilfsvariable benötigt, die den letzten Buchstaben speichert, damit die Buchstaben miteinander verglichen werden können. Diese wird vor der Schleife auf den ersten Buchstaben des Wortes gesetzt. \n",
+ "4. in jedem Durchlauf der Schleife wird der aktuelle Buchstabe mit dem vorherigen verglichen. Wenn er kleiner ist, wird `False` zurückgegeben, sonst wird `previous` auf `letter` gesetzt. \n",
+ "5. Wird die Schleife verlassen, ohne das `False` zurückgegeben wurde, wird `True` zurückgegeben. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def is_abecedarian(word):\n",
+ " previous=word[0]\n",
+ " for letter in word.lower():\n",
+ " if letter<previous:\n",
+ " return False\n",
+ " previous=letter\n",
+ " return True\n",
+ "\n",
+ "is_abecedarian(\"beginnt\")"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {},
@@ -381,6 +746,40 @@
"*(Das längste Wort mit dieser Eigenschaft in der Liste ist `beginnt`.)*"
]
},
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "([Spoiler Alert](https://xkcd.com/109/), Randall Munroe)\n",
+ "\n",
+ "1. Wie gehabt ist dies eine Abwandlung des ersten Tests, den Sie geschrieben haben. Kopieren Sie also eine der Testanweißungen. Da nach der Anzahl der Worte mit dieser Eigenschaft gefragt ist, bietet es sich an, einen der Tests zu kopieren, der bereits count enthält. \n",
+ "2. Überlegen Sie, wie Sie diese Funktion anpassen müssen. An welcher Stelle wird `is_abecedarian()` aufgerufen, was passiert wenn `is_abecedarian() True` zurückgibt?\n",
+ "3. Vergessen Sie nicht die .txt datei zu öffnen und zu übergeben. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def abecedarian(fin):\n",
+ " count=0\n",
+ " for line in fin:\n",
+ " word=line.strip()\n",
+ " if is_abecedarian(word):\n",
+ " count=count+1\n",
+ " print(line)\n",
+ " return count\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "fin = open('top10000de.txt', encoding=\"latin1\")\n",
+ "abecedarian(fin)"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {},
@@ -413,11 +812,11 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "Die `for`-Schleife geht über die Zeichen in `word` (genauer: nach Umwandlung in Kleinbuchstaben, wegen `lower`). Falls wir den Buchstaben \"e\" finden, können wir sofort `False` zurückgeben; ansonsten gehen wir zum nächsten Buchstaben. Wenn wir die Schleife ganz normal verlassen, d.h. wenn wir kein \"e\" gefunden haben, geben wir `True` zurück.\n",
+ "Die `for`-Schleife geht über die Zeichen in `word` (genau genommen nach der Umwandlung in Kleinbuchstaben, wegen der Verwendung von `lower`). Falls wir den Buchstaben \"e\" finden, können wir sofort `False` zurückgeben; ansonsten gehen wir zum nächsten Buchstaben. Wenn wir die Schleife ganz normal verlassen, d.h. wenn wir kein \"e\" gefunden haben, geben wir `True` zurück.\n",
"\n",
"Wir können diese Funktion noch etwas kompakter schreiben, indem wir den `in`-Operator verwenden, aber ich habe Ihnen diese Variante präsentiert, weil sie die Logik hinter der Suche demonstriert.\n",
"\n",
- "`avoids` ist eine verallgemeinerte Version von `has_no_e` aber es hat die gleiche Struktur:"
+ "`avoids` ist eine verallgemeinerte Version von `has_no_e` aber sie hat die gleiche Struktur:"
]
},
{
@@ -437,9 +836,9 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "Wir können `False` zurückgeben, sobald wir einen verbotenen Buchstaben finden; wenn wir am Ende der Schleife angelagt sind, geben wir `True` zurück.\n",
+ "Wir können `False` zurückgeben, sobald wir einen verbotenen Buchstaben finden; wenn wir am Ende der Schleife angelangt sind, geben wir `True` zurück.\n",
"\n",
- "`uses_only` ist ähnlich, außer dass die Semantik der Bedingung umgekehrt ist:\n"
+ "`uses_only` ist ähnlich, aber die Semantik der Bedingung ist umgekehrt:\n"
]
},
{
@@ -576,7 +975,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "Die Schleife startet mit `i = 0` und endet wenn `i = len(word)-1` gilt. Bei jedem Schleifendurchlauf wird das *i*te Zeichen (was wir uns als das aktuelle Zeichen vorstellen können) mit dem *i+1*ten Zeichen (welches wir uns als das nächste Zeichen vorstellen können) verglichen. \n",
+ "Die Schleife startet mit `i = 0` und endet wenn `i = len(word)-1` gilt. Bei jedem Schleifendurchlauf wird das *i*-te Zeichen (was wir uns als das aktuelle Zeichen vorstellen können) mit dem *i+1*-ten Zeichen (welches wir uns als das nächste Zeichen vorstellen können) verglichen. \n",
"\n",
"Wenn das nächste Zeichen (alphabetisch) kleiner als das aktuelle Zeichen ist, dann haben wir eine Verletzung der alphabetischen Reihenfolge entdeckt und geben `False` zurück.\n",
"\n",
@@ -618,14 +1017,39 @@
"outputs": [],
"source": [
"def is_palindrome(word):\n",
- " return is_reverse(word, word)"
+ " return is_reverse(word, word)\n",
+ "\n",
+ "is_palindrome(\"anna\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "... indem wir `is_reverse` aus [Abschnitt 8.11](seminar08.ipynb#8.11-Debugging) verwenden. "
+ "... indem wir `is_reverse` aus [Abschnitt 8.11](seminar08.ipynb#8.11-Debugging) verwenden:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def is_reverse(word1, word2):\n",
+ " '''Um die kürzere Funktion is_palindrom() aufzurufen eingefügt.'''\n",
+ " if len(word1) != len(word2):\n",
+ " return False\n",
+ " \n",
+ " i = 0\n",
+ " j = len(word2)-1\n",
+ "\n",
+ " while j > 0:\n",
+ " if word1[i] != word2[j]:\n",
+ " return False\n",
+ " i = i+1\n",
+ " j = j-1\n",
+ "\n",
+ " return True"
]
},
{
@@ -661,7 +1085,7 @@
"\n",
"- Dateiobjekt:\n",
"- Zurückführen auf ein vorher gelöstes Problem:\n",
- "- Spezialfall:\n",
+ "- Spezialfall: ein nicht offensichtlicher Fall, in dem sich oft Fehler verstecken.\n",
"\n",
"Ergänzen Sie die Liste in eigenen Worten. Das ist eine gute Erinnerungs- und Übungsmöglichkeit."
]
@@ -670,15 +1094,25 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "### Ãœbung\n",
- "\n",
- "#### Aufgabe 7\n",
+ "### 9.7 Ãœbung\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Aufgabe 7\n",
"\n",
- "Diese Aufgabe basiert auf einem Rätsel welches im Radioprogramm [Car Talk](http://www.cartalk.com/content/puzzlers) gesendet wurde. \n",
+ "Hier ist ein weiteres [Car Talk Rätsel](http://www.cartalk.com/content/puzzlers):\n",
"\n",
- "> Gib' mir ein Wort mit zwei aufeinanderfolgenden doppelten Buchstaben. Ich gebe Dir ein paar Wörter, die sich fast dafür qualifizieren (aber nur fast!) - beispielsweise das Wort Kommission, K-o-m-m-i-s-s-i-o-n. Es wäre gut, aber leider hat sich das \"i\" zwischen \"mm\" und \"ss\" eingeschlichen. Oder \"Ballett\" - wenn wir das \"e\" entfernen könnten, würde es klappen. Aber es gibt mindestens ein Wort, welches zwei aufeinanderfolgende Paare von (jeweils gleichen) Buchstaben hat und vielleicht ist es das einzige solche Wort. Welches Wort ist es?\n",
+ "> Als ich letztens auf der Autobahn gefahren bin ist mir auf meinem Kilometerzähler etwas aufgefallen. Wie die meisten Kilometerzähler hat er sechs Stellen für die ganzen Kilometer. Wenn also mein Auto 300000 Kilometer gefahren wäre, dann würde ich 3-0-0-0-0-0 sehen. Was ich sah, war sehr interessant. Mir ist aufgefallen, dass die letzten vier Ziffern ein Palindrom gebildet haben, d.h. rückwärts gelesen ergeben sie die gleiche Zahlenfolge wie vorwärts. Beispielswiese ist 5-4-4-5 ein Palindrom. Mein Kilometerzähler könnte also beispielsweise 3-1-5-4-4-5 angezeigt haben. \n",
+ ">\n",
+ "> Einen Kilometer später ergaben die letzten 5 Ziffern ein Palindrom. Mein Kilometerzähler könnte also beispielsweise 3-6-5-4-5-6 anzeigen. Nach einem weiteren Kilometer ergaben die mittleren 4 der 6 Ziffern ein Palindrom. Bis du bereit? Noch einen Kilometer weiter ergaben alle 6 Ziffern ein Palindrom!\n",
+ ">\n",
+ "> Die Frage ist: was zeigte der Kilometerzähler an, als ich das erste mal darauf schaute?\n",
"\n",
- "Schreiben Sie ein Programm, um das Wort zu finden. Die Lösung für englische Wörter (http://thinkpython2.com/code/cartalk1.py) findet sogar Wörter mit drei aufeinanderfolgenden Buchstabenpaaren (die es im Deutschen vermutlich nicht gibt, zumindest nicht in der hier verwendeten Wortliste). "
+ "Schreiben Sie ein Python-Programm, welches alle Zahlen mit sechs Ziffern durchtestet und alle Nummern mit dieser Eigenschaft ausgibt."
]
},
{
@@ -687,20 +1121,32 @@
"metadata": {},
"outputs": [],
"source": [
- "# Implementieren Sie hier das Programm"
+ "# Implementieren Sie hier das Programm\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "Ein ähnliches Problem:\n",
"\n",
- "\n",
+ "\n",
+ "([Spoiler Alert](https://xkcd.com/109/), Randall Munroe)\n",
+ "\n",
+ "\n",
+ "1. Es sollte schnell klar werden, dass wir mehrere Funktionen brauchen, die ineinander greifen. Insgesamt werden 3 Funktionen benötigt. Überlegen Sie welche Funktionen benötigt werden und schreiben Sie eventuell schoneinmal die Funktionskopf. \n",
+ "2. Wir brauchen auf jedenfall eine Funktion, die testet ob eine Zahl ein Palindrom ist. Verwandeln Sie die eingegebene Zahl in einen `string` dann können Sie die einzeilige version von is_palindrom aus [Abschnitt 8.13](seminar08.ipynb#8.13-Übung) wiederverwenden.\n",
+ "3. Testen Sie diese Funktion. Behalten Sie auf jeden Fall im Kopf, dass die Funktion im Lauf der Entwicklung unter Umständen angepasst werden muss. \n",
+ "4. Sobald `palindrom` funktioniert, schreiben wir eine Funktion, die für einzelne Zahlen prüft, ob die Bedingungen des Rätsels erfüllt sind. Diese Funktion ist schwierig zu testen, da Sie quasi im Kopf durchrechnen müssten, was das Ergebnis ist. Kontrollieren Sie ob Sie die Angaben des Rätsels richtig übernommen haben und geben Sie der Funktion ggf. einen Vertrauensvorschuss.\n",
+ "5. Die Funktion ruft `palindrom` mit verschiedenen Werten auf, die aus der Zahl errechnet werden, die eingegeben wird. Beim erneuten Lesen der Aufgabenstellung sollte auffallen, dass wir die eingegebene Zahl auf verschiedene Längen kürzen müssen.\n",
+ "6. Am besten funktiert das, wenn Sie Start- und Endwerte mit übergeben und diese dann auch an palindrom weitergeben. Hier müssen wir `palindrom` anpassen, indem wir mehr Werte übergeben und den `string` mit dem Klammernoperator entsprechend kürzen. \n",
+ "7. Insgesamt müssen 4 Zahlen überprüft werden, dabei kann abgebrochen werden, sobald einer der Tests `False` zurückgibt. Zuerst wird palindrom mit i, 2 und 6 aufgerufen, dann mit i+1, 1 und 6. Schreiben Sie die anderen beiden Tests selber und ergänzen Sie wie notwendig die `return`-Anweißungen. *Hinweiß: Sie können die Funktion mit 199999 und 111111 testen, ersteres gibt `True` letzteres `False` zurück.* \n",
+ "8. Wenn diese Tests das gewüschte Ergebnis liefern, nehmen Sie an, dass die Funktion richtig funktioniert und schreiben Sie die letzte Funktion die wir benötigen. Sie iteriert durch alle möglichen Zählerstände und gibt alle aus, die die Bedingung des Rätsels erfüllen. Überlegen Sie was der kleinstmögliche Zählerstand ist. Überlegen Sie auch was der größtmögliche Zählerstand ist.\n",
+ "9. Erstellen Sie eine Variable mit dem kleinstmöglichen Zählerstand und eine Schleife, deren Abbruchbedingung der größtmögliche Zählerstand ist.\n",
+ "10. In dieser Schleife prüfen Sie den momentanen Wert des Zählers in `check()` und wenn die Funktion `True` zurückliefert, drucken sie den Wert des Zählers aus. Wenn Sie eine `while`-Schleife verwenden, vergessen Sie nicht den Wert des Zählers zu inkrementieren. \n",
"\n",
- "[Consecutive Vowels](https://xkcd.com/853/), Randall Munroe\n",
+ "*Hinweiß: 198888 und 199999 sollten als Lösungen rauskommen*\n",
"\n",
- "Schreiben Sie ein Programm, welches das Wort mit den meisten hintereinander auftauchenden Vokalen in unserer Wortliste findet."
+ "Eine weitere Lösung finden Sie [hier](http://thinkpython2.com/code/cartalk2.py)."
]
},
{
@@ -708,7 +1154,36 @@
"execution_count": null,
"metadata": {},
"outputs": [],
- "source": []
+ "source": [
+ "def palindrom(i, start, end):\n",
+ " s=str(i)[start:end]\n",
+ " return s[::-1]==s\n",
+ " \n",
+ "\n",
+ " \n",
+ "def check(i):\n",
+ " if palindrom(i, 2,6):\n",
+ " if palindrom(i+1, 1, 6):\n",
+ " if palindrom(i+2,1,5):\n",
+ " if palindrom(i+3,0,6):\n",
+ " return True\n",
+ " return False \n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "def check_all():\n",
+ " i = 100000\n",
+ " print(\"Hier die Zählerstände die Lösungen sind: \\n\")\n",
+ " while i <= 999999:\n",
+ " if check(i):\n",
+ " print(i)\n",
+ " i = i + 1\n",
+ "\n",
+ " \n",
+ "check_all()"
+ ]
},
{
"cell_type": "markdown",
@@ -716,15 +1191,12 @@
"source": [
"### Aufgabe 8\n",
"\n",
- "Hier ist ein weiteres [Car Talk Rätsel](http://www.cartalk.com/content/puzzlers):\n",
+ "Und noch ein [Car Talk Rätsel](http://www.cartalk.com/content/puzzlers) welches sich mit Suche lösen lässt:\n",
"\n",
- "> Als ich letztens auf der Autobahn gefahren bin ist mir auf meinem Kilometerzähler etwas aufgefallen. Wie die meisten Kilometerzähler hat er sechs Stellen, für die ganzen Kilometer. Wenn also mein Auto 300000 Kilometer gefahren wäre, dann würde ich 3-0-0-0-0-0 sehen. Was ich sah, war sehr interessant. Mir ist aufgefallen, dass die letzten vier Ziffern ein Palindrom gebildet haben, d.h. rückwärts gelesen ergeben sie die gleiche Zahlenfolge wie vorwärts. Beispielswiese ist 5-4-4-5 ein Palindrom. Mein Kilometerzähler könnte also beispielsweise 3-1-5-4-4-5 angezeigt haben. \n",
- ">\n",
- "> Einen Kilometer später ergaben die letzten 5 Ziffern ein Palindrom. Mein Kilometerzähler könnte also beispielsweise 3-6-5-4-5-6 anzeigen. Nach einem weiteren Kilometer ergaben die mittleren 4 der 6 Ziffern ein Palindrom. Bis du bereit? Noch einen Kilometer weiter ergaben alle 6 Ziffern ein Palindrom!\n",
- ">\n",
- "> Die Frage ist: was zeigte der Kilometerzähler an, als ich das erste mal darauf schaute?\n",
+ "> Letztens hat mich meine Mutter besucht und uns ist aufgefallen, dass die zwei Ziffern, die mein Alter angegeben rückwärts gelesen ihrem Alter entsprachen. Wir haben uns gefragt, wie oft das über die Jahre schon passiert ist, aber wir wurden abgelenkt und haben keine Antwort gefunden.\n",
+ "> Als ich nach Hause kam ist mir aufgefallen, dass die Ziffern unserer Alter sich bisher sechs mal umkehren ließen. Mir fiel auch auf, dass es in ein paar Jahren nochmal passieren würde, wenn es uns bis dahin gut geht. Und wenn wir richtig viel Glück haben, würde es danach noch einmal passieren. Anders gesagt: es könnte acht mal insgesamt passieren. Die Frage ist also, wie alt ich gerade bin?\n",
"\n",
- "Schreiben Sie ein Python-Programm, welches alle Zahlen mit sechs Ziffern durchtestet und alle Nummern mit dieser Eigenschaft ausgibt. Eine Lösung finden Sie hier: http://thinkpython2.com/code/cartalk2.py."
+ "Schreiben Sie ein Programm, welches nach einer Lösung für dieses Rätsel sucht. Hinweis: Sie könnten die Zeichenketten-Methode [zfill](http://python-reference.readthedocs.io/en/latest/docs/str/zfill.html) nützlich finden. Lösung: http://thinkpython2.com/code/cartalk3.py"
]
},
{
@@ -733,21 +1205,40 @@
"metadata": {},
"outputs": [],
"source": [
- "# Implementieren Sie hier das Programm\n"
+ "# Implementieren Sie hier ihr Programm\n",
+ "\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
- "### Aufgabe 9\n",
"\n",
- "Und noch ein [Car Talk Rätsel](http://www.cartalk.com/content/puzzlers) welches sich mit Suche lösen lässt:\n",
+ "\n",
+ "([Spoiler Alert](https://xkcd.com/109/), Randall Munroe)\n",
"\n",
- "> Letztens hat mich meine Mutter besucht und uns ist aufgefallen, dass die zwei Ziffern, die mein Alter angegeben rückwärts gelesen ihrem Alter entsprachen. Wir haben uns gefragt, wie oft das über die Jahre schon passiert ist, aber wir wurden abgelenkt und haben keine Antwort gefunden.\n",
- "> Als ich nach Hause kam ist mir aufgefallen, dass die Ziffern unserer Alter sich bisher sechs mal umkehren ließen. Mir fiel auch auf, dass es in ein paar Jahren nochmal passieren würde, wenn es uns bis dahin gut geht. Und wenn wir richtig viel Glück haben, würde es danach noch einmal passieren. Anders gesagt: es könnte acht mal insgesamt passieren. Die Frage ist also, wie alt ich gerade bin?\n",
+ "1. Auch dies ist wieder ein Problem für das wir mehrere Funktionen schreiben müssen. Überlegen Sie zunächst in welche Bestandteile sie das Problem aufteilen können.\n",
+ "2. Wir brauchen insgesammt 4 Funktionen, diese sind stärker miteinander verbunden als in der vorherigen Aufgabe, wir versuchen dennoch Sie nach und nach zu schreiben.\n",
+ "3. Wir schreiben zunächst eine Funktion, die testet ob sich das Alter herumdrehen lässt. Sie brauchen 2 Strings der gleichen Länge, dafür können Sie `zfill(2)` verwenden. Orientieren Sie sich an `palindrom` aus der vorherigen Aufgabe.\n",
+ "4. Die Funktion `are_reversed()` wird in 2 weiteren Funktionen dieser Aufgabe verwenden, die sich einigen Code teilen. Schreiben Sie also zunächst eine der Funktionen, duplizieren Sie sie dann und passen Sie sie entsprechen an.\n",
+ "5. In der ersten Funktion wird gezählt, wie oft sich für einen gegebenen Altersunterschied das Alter der Mutter und der Tochter umdrehen lässt. \n",
+ "6. Erstellen Sie eine Variable die das Alter der Tochter simuliert. Initialisieren Sie diese mit 0. Erstellen Sie eine Variable die zählt wie oft sich das Alter umdrehen lässt.\n",
+ "7. Da Sie jedes mögliche Alter für den gegebenen Abstand testen wollen erstellen Sie ein Schleife. Da Sie das Alter der Mutter als Abbruchbedingung nehmen wollen und wir die entsprechende Variable erst in der Schleife initialisieren verwenden Sie eine Schleife die erst abbricht, wenn in der Schleife eine Bedingung erfüllt wird. (*`While True`*)\n",
+ "8. Das Alter der Mutter ergibt sich aus dem Alter der Tochter und der Differenz. Erstellen Sie die Variable entsprechend. \n",
+ "9. Rufen Sie `are_reversed()` mit mother und daughter auf. Wird `True` zurückgegeben, muss count inkrementiert werden.\n",
+ "10. Testen Sie das Alter der Mutter. Ist es größer als 100 brechen Sie die Schleife mit einer `break`-Anweißung ab.\n",
+ "11. Vergessen Sie nicht vor Abschluss des Schleifendurchlaufs die Variable `daughter` zu inkrementieren.\n",
+ "12. Nach Verlassen der Schleife geben Sie mit der `return`-Anweißung den Zähler zurück. \n",
+ "13. Kopieren Sie die Funktion und geben Sie ihr einen neuen Namen. Weitere Änderungen der Funktion führen wir an gegebener Stelle durch. \n",
+ "14. Schreiben Sie nun zunächst eine allgemeine Funktion. Diese wird nach und nach den Altersabstand zwischen Mutter und Tocher erhöhen und prüfen ob die Bedingung des Rätsels erfüllt ist. Da wir den Altersabstand an die anderen Funktionen weiterreichen, erstellen Sie hier die benötigte Variable. Legen Sie einen sinnvollen Mindestabstand fest. \n",
+ "15. Schreiben Sie eine Schleife die den Altersabstand graduell vergrößert. Wählen Sie einen sinnvollen Maximalabstand als Abbruchbedingung.\n",
+ "16. In der Schleife wird `num_instances()`aufgerufen und der Rückgabewert einer Variablen zugewießen. Diese Variable wird dann geprüft um zu schauen ob dieser Altersabstand die Bedingung des Rätsels erfüllt. Was ist diese Bedinung?\n",
+ "17. Ist die Bedinung erfüllt wird `list_instance` mit dieser Differenz aufgerufen. Diese Funktion prüft das Alter analog zu `num_instances()` und gibt das Alter aus, das die Lösung des Rätsels dastellt. Wir brauchen hierbei `print`-Anweißungen, eine für den Kopf der Tablle und eine die das Alter ausdruckt, wenn sich das Alter von Mutter und Tochter genau x mal bisher umdrehen ließ. \n",
"\n",
- "Schreiben Sie ein Programm, welches nach einer Lösung für dieses Rätsel sucht. Hinweis: Sie könnten die Zeichenketten-Methode [zfill](http://python-reference.readthedocs.io/en/latest/docs/str/zfill.html) nützlich finden. Lösung: http://thinkpython2.com/code/cartalk3.py"
+ "*Hinweiß: Vergessen Sie nicht, diff in der Schleife zu inkrementieren!*\n",
+ "\n",
+ "\n",
+ "\n"
]
},
{
@@ -756,8 +1247,50 @@
"metadata": {},
"outputs": [],
"source": [
- "# Implementieren Sie hier ihr Programm\n",
- "\n"
+ "def are_reversed(i,j):\n",
+ " i= str(i).zfill(2)\n",
+ " j= str(j).zfill(2)\n",
+ " if i==j[::-1]:\n",
+ " return True\n",
+ " \n",
+ "\n",
+ "def num_instances(diff):\n",
+ " daughter = 0\n",
+ " count = 0\n",
+ " while True:\n",
+ " mother = daughter + diff\n",
+ " if are_reversed(daughter, mother):\n",
+ " count = count + 1\n",
+ " if mother > 100:\n",
+ " break\n",
+ " daughter = daughter + 1\n",
+ " return count\n",
+ "\n",
+ "\n",
+ "def list_instance(diff):\n",
+ " daughter=0\n",
+ " count=0\n",
+ " print(\"daughter mother\")\n",
+ " while True:\n",
+ " mother= daughter+diff\n",
+ " if are_reversed(daughter, mother):\n",
+ " count=count+1\n",
+ " if count==6:\n",
+ " print(daughter,\" \",mother)\n",
+ " if mother > 100:\n",
+ " return\n",
+ " daughter=daughter+1\n",
+ "\n",
+ "\n",
+ "def check_ages():\n",
+ " diff = 13\n",
+ " while diff < 70:\n",
+ " n = num_instances(diff)\n",
+ " if n == 8:\n",
+ " list_instance(diff)\n",
+ " diff = diff + 1 \n",
+ "\n",
+ "check_ages()\n"
]
},
{
diff --git a/notebooks/test.txt b/notebooks/test.txt
new file mode 100644
index 0000000000000000000000000000000000000000..bc2a36524d2bcd46f811b262ed34e8fc6776da6f
--- /dev/null
+++ b/notebooks/test.txt
@@ -0,0 +1,77 @@
+
+Syntax
+
+The format of email addresses is local-part@domain where the local part may be up to 64 characters long and the domain may have a maximum of 255 characters.[4] The formal definitions are in RFC 5322 (sections 3.2.3 and 3.4.1) and RFC 5321—with a more readable form given in the informational RFC 3696[5] and the associated errata. Note that unlike the syntax of RFC 1034,[6] and RFC 1035[7] there is no trailing period in the domain name.
+Local-part
+
+The local-part of the email address may use any of these ASCII characters:
+
+ uppercase and lowercase Latin letters A to Z and a to z;
+ digits 0 to 9;
+ printable characters others than letters and digit !#$%&'*+-/=?^_`{|}~;
+
+ dot ., provided that it is not the first or last character unless quoted, and provided also that it does not appear consecutively unless quoted (e.g. John..Doe@example.com is not allowed but "John..Doe"@example.com is allowed);[8]
+
+Note that some mail servers wildcard local parts, typically the characters following a plus and less often the characters following a minus, so fred+bah@domain and fred+foo@domain might end up in the same inbox as fred+@domain or even as fred@domain. This can be useful for tagging emails for sorting, see below, and for spam control. Braces { and } are also used in that fashion, although less often.
+
+ space and special characters "(),:;<>@[\] are allowed with restrictions (they are only allowed inside a quoted string, as described in the paragraph below, and in addition, a backslash or double-quote must be preceded by a backslash);
+ comments are allowed with parentheses at either end of the local-part; e.g. john.smith(comment)@example.com and (comment)john.smith@example.com are both equivalent to john.smith@example.com.
+
+In addition to the above ASCII characters, international characters above U+007F, encoded as UTF-8, are permitted by RFC 6531, though even mail systems that support SMTPUTF8 and 8BITMIME may restrict which characters to use when assigning local-parts.
+
+A local part is either a Dot-string or a Quoted-string; it cannot be a combination. Quoted strings and characters however, are not commonly used.[citation needed] RFC 5321 also warns that "a host that expects to receive mail SHOULD avoid defining mailboxes where the Local-part requires (or uses) the Quoted-string form".
+
+The local-part postmaster is treated specially—it is case-insensitive, and should be forwarded to the domain email administrator. Technically all other local-parts are case-sensitive, therefore jsmith@example.com and JSmith@example.com specify different mailboxes; however, many organizations treat uppercase and lowercase letters as equivalent. Indeed, RFC 5321 warns that "a host that expects to receive mail SHOULD avoid defining mailboxes where ... the Local-part is case-sensitive".
+
+Despite the wide range of special characters which are technically valid, organisations, mail services, mail servers and mail clients in practice often do not accept all of them. For example, Windows Live Hotmail only allows creation of email addresses using alphanumerics, dot (.), underscore (_) and hyphen (-).[9] Common advice is to avoid using some special characters to avoid the risk of rejected emails.[10]
+Domain
+
+The domain name part of an email address has to conform to strict guidelines: it must match the requirements for a hostname, a list of dot-separated DNS labels, each label being limited to a length of 63 characters and consisting of:[8]:§2
+
+ uppercase and lowercase Latin letters A to Z and a to z;
+ digits 0 to 9, provided that top-level domain names are not all-numeric;
+ hyphen -, provided that it is not the first or last character.
+
+This rule is known as the LDH rule (letters, digits, hyphen). In addition, the domain may be an IP address literal, surrounded by square brackets [], such as jsmith@[192.168.2.1] or jsmith@[IPv6:2001:db8::1], although this is rarely seen except in email spam. Internationalized domain names (which are encoded to comply with the requirements for a hostname) allow for presentation of non-ASCII domains. In mail systems compliant with RFC 6531 and RFC 6532 an email address may be encoded as UTF-8, both a local-part as well as a domain name.
+
+Comments are allowed in the domain as well as in the local-part; for example, john.smith@(comment)example.com and john.smith@example.com(comment) are equivalent to john.smith@example.com.
+Examples
+
+Valid email addresses
+ simple@example.com
+ very.common@example.com
+ disposable.style.email.with+symbol@example.com
+ other.email-with-hyphen@example.com
+ fully-qualified-domain@example.com
+ user.name+tag+sorting@example.com (may go to user.name@example.com inbox depending on mail server)
+ x@example.com (one-letter local-part)
+ example-indeed@strange-example.com
+ admin@mailserver1 (local domain name with no TLD, although ICANN highly discourages dotless email addresses)
+ example@s.example (see the List of Internet top-level domains)
+ " "@example.org (space between the quotes)
+ "john..doe"@example.org (quoted double dot)
+
+Invalid email addresses
+ Abc.example.com (no @ character)
+ A@b@c@example.com (only one @ is allowed outside quotation marks)
+ a"b(c)d,e:f;g<h>i[j\k]l@example.com (none of the special characters in this local-part are allowed outside quotation marks)
+ just"not"right@example.com (quoted strings must be dot separated or the only element making up the local-part)
+ this is"not\allowed@example.com (spaces, quotes, and backslashes may only exist when within quoted strings and preceded by a backslash)
+ this\ still\"not\\allowed@example.com (even if escaped (preceded by a backslash), spaces, quotes, and backslashes must still be contained by quotes)
+ 1234567890123456789012345678901234567890123456789012345678901234+x@example.com (local part is longer than 64 characters)
+
+Common local-part semantics
+
+According to RFC 5321 2.3.11 Mailbox and Address, "...the local-part MUST be interpreted and assigned semantics only by the host specified in the domain of the address." This means that no assumptions can be made about the meaning of the local-part of another mail server. It is entirely up to the configuration of the mail server.
+Local-part normalization
+
+Interpretation of the local part of an email address is dependent on the conventions and policies implemented in the mail server. For example, case sensitivity may distinguish mailboxes differing only in capitalization of characters of the local-part, although this is not very common.[11] Gmail ignores all dots in the local-part for the purposes of determining account identity.[12] This prevents the creation of user accounts your.user.name or yourusername when the account your.username already exists.
+Subaddressing
+
+Some mail services support a tag included in the local-part, such that the address is an alias to a prefix of the local part. For example, the address joeuser+tag@example.com denotes the same delivery address as joeuser@example.com. RFC 5233, refers to this convention as sub-addressing, but it is also known as plus addressing or tagged addressing.
+
+Addresses of this form, using various separators between the base name and the tag, are supported by several email services, including Runbox (plus), Gmail (plus),[13] Rackspace Email (plus), Yahoo! Mail Plus (hyphen),[14] Apple's iCloud (plus), Outlook.com (plus),[15] ProtonMail (plus),[16] FastMail (plus and Subdomain Addressing),[17] MMDF (equals), Qmail and Courier Mail Server (hyphen).[18][19] Postfix allows configuring an arbitrary separator from the legal character set.[20]
+
+The text of the tag may be used to apply filtering,[18] or to create single-use, or disposable email addresses.[21]
+
+In practice, the form validation of some web sites may reject special characters such as "+" in an email address – treating them, incorrectly, as invalid characters. This can lead to an incorrect user receiving an e-mail if the "+" is silently stripped by a website without any warning or error messages. For example, an email intended for the user-entered email address foo+bar@example.com could be incorrectly sent to foobar@example.com. In other cases a poor user experience can occur if some parts of a site, such as a user registration page, allow the "+" character whilst other parts, such as a page for unsubscribing from a site's mailing list, do not.
diff --git a/notebooks/uebung_regex.ipynb b/notebooks/uebung_regex.ipynb
new file mode 100644
index 0000000000000000000000000000000000000000..5c34bb95317748a2e8dc8cc72e0671787bd0d7b5
--- /dev/null
+++ b/notebooks/uebung_regex.ipynb
@@ -0,0 +1,151 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# 12. Ãœbungsblatt\n",
+ "\n",
+ "Mit diesem Python-Code können Sie Ihren regulären Ausdruck testen:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import re\n",
+ "\n",
+ "\"\"\"\n",
+ "Ändern Sie den folgenden regulären Ausdruck, so dass alle \n",
+ "positiven Muster erkannt werden, aber kein negatives Muster.\n",
+ "\"\"\"\n",
+ "muster = re.compile(\"Z\") \n",
+ "positive = [\n",
+ " \"rap them\",\n",
+ " \"tapeth\",\n",
+ " \"apth\",\n",
+ " \"wrap/try\",\n",
+ " \"sap tray\",\n",
+ " \"87ap9th\",\n",
+ " \"apothecary\"\n",
+ "]\n",
+ "\n",
+ "negative = [\n",
+ " \"aleht\",\n",
+ " \"happy them\",\n",
+ " \"tarpth\",\n",
+ " \"Apt\",\n",
+ " \"peth\",\n",
+ " \"tarreth\",\n",
+ " \"ddapdg\",\n",
+ " \"apples\",\n",
+ " \"shape the\"\n",
+ "]\n",
+ "\n",
+ "# testen, ob alle positiven Muster richtig erkannt werden\n",
+ "positive_not_matched = [s for s in positive if not muster.findall(s)]\n",
+ "if positive_not_matched:\n",
+ " print(\"Folgende positiven Muster wurden nicht erkannt:\", \", \".join(positive_not_matched))\n",
+ "\n",
+ "# testen, ob keine negativen Muster erkannt werden\n",
+ "negative_matched = [s for s in negative if muster.findall(s)]\n",
+ "if negative_matched:\n",
+ " print(\"Folgende negativen Muster wurden erkannt:\", \", \".join(negative_matched))\n",
+ "\n",
+ "if not positive_not_matched and not negative_matched:\n",
+ " print(\"Herzlichen Glückwunsch, Sie haben das richtige Muster gefunden!\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Nachfolgend noch einige Beispiele zur Verwendung von regulären Ausdrücke mit Python:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Funktionen für reguläre Ausdrücke werden im Modul \"re\" bereitgestellt\n",
+ "import re\n",
+ "\n",
+ "# die Methode \"findall\" findet alle Teilzeichenketten in einer Zeichenkette,\n",
+ "# die auf das angegebene Muster passen \n",
+ "re.findall(\"cat|dog\", \"This sentence contains a dog.\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# die Methode \"match\" testet, ob die gesamte Zeichenkette auf das angegebene Muster passt \n",
+ "re.match(\".*dog\\\\.\", \"This sentence contains a dog.\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "re.match(\".*(cat|dog)\", \"This sentence contains a cat.\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Mit \"match\" können wir beispielsweise unsere Ergebnisse für Aufgabe 1 prüfen:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if re.match(\"[hc]?at\", \"cat\"):\n",
+ " print(\"Wort wurde erkannt\")\n",
+ "else:\n",
+ " print(\"Wort wurde nicht erkannt\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": []
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Es gibt eine umfangreiche eingebaute Hilfe:\n",
+ "help(re)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "name": "python",
+ "pygments_lexer": "ipython3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git "a/programmierspa\303\237/Working_with_excel_spreadsheets.ipynb" "b/programmierspa\303\237/Working_with_excel_spreadsheets.ipynb"
new file mode 100644
index 0000000000000000000000000000000000000000..999c21bc615bf733439efdf8e59e4c9d6a144496
--- /dev/null
+++ "b/programmierspa\303\237/Working_with_excel_spreadsheets.ipynb"
@@ -0,0 +1,1247 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Working with Excel Spreadsheets"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Source: https://automatetheboringstuff.com/chapter12/"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%load_ext nb_black"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "## Working with Excel Spreadsheets\n",
+ "\n",
+ "**Excel** is a popular and powerful spreadsheet application for Windows. The `openpyxl` module allows your Python programs to read and modify Excel spreadsheet files. For example, you might have the boring task of copying certain data from one spreadsheet and pasting it into another one. Or you might have to go through thousands of rows and pick out just a handful of them to make small edits based on some criteria. Or you might have to look through hundreds of spreadsheets of department budgets, searching for any that are in the red. These are exactly the sort of boring, mindless spreadsheet tasks that Python can do for you.\n",
+ "\n",
+ "Although Excel is proprietary software from Microsoft, there are free alternatives that run on Windows, OS X, and Linux. Both LibreOffice Calc and OpenOffice Calc work with Excel’s `.xlsx` file format for spreadsheets, which means the openpyxl module can work on spreadsheets from these applications as well. You can download the software from https://www.libreoffice.org/ and http://www.openoffice.org/, respectively. Even if you already have Excel installed on your computer, you may find these programs easier to use. The screenshots in this chapter, however, are all from Excel 2010 on Windows 7."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### About Excel\n",
+ "\n",
+ "First, let’s go over some basic definitions: An Excel spreadsheet document is called a **workbook**. A single workbook is saved in a file with the `.xlsx` extension. Each workbook can contain multiple sheets (also called **worksheets**). The sheet the user is currently viewing (or last viewed before closing Excel) is called the **active sheet**.\n",
+ "\n",
+ "Each sheet has **columns** (addressed by letters starting at A) and **rows** (addressed by numbers starting at 1). A box at a particular column and row is called a **cell**. Each cell can contain a number or text value. The grid of cells with data makes up a sheet."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Installing the openpyxl Module\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Python does not come with OpenPyXL, so you’ll have to install it."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!pip install openpyxl"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ " To test whether it is installed correctly, enter the following into a code block:\n",
+ "\n",
+ "`import openpyxl`\n",
+ "\n",
+ "If the module was correctly installed, this should produce no error messages. Remember to import the `openpyxl` module before running the examples in this notebook, or you’ll get a *NameError: name 'openpyxl' is not defined* error.\n",
+ "\n",
+ "This book covers version 2.3.3 of OpenPyXL, but new versions are regularly released by the OpenPyXL team. Don’t worry, though: New versions should stay backward compatible with the instructions in this book for quite some time. If you have a newer version and want to see what additional features may be available to you, you can check out the full documentation for OpenPyXL at http://openpyxl.readthedocs.org/."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Reading Excel Documents\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The examples in this chapter will use a spreadsheet named **example.xlsx** stored in the root folder. You can either create the spreadsheet yourself or download it from http://nostarch.com/automatestuff/. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Opening Excel Documents with OpenPyXL\n",
+ "\n",
+ "Once you’ve imported the openpyxl module, you’ll be able to use the `openpyxl.load_workbook()` function. Enter the following into a code block:\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import openpyxl\n",
+ "\n",
+ "wb = openpyxl.load_workbook(\"example.xlsx\")\n",
+ "type(wb)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ " \n",
+ "The `openpyxl.load_workbook()` function takes in the filename and returns a value of the workbook data type. This Workbook object represents the Excel file, a bit like how a File object represents an opened text file.\n",
+ "\n",
+ "Remember that *example.xlsx* needs to be in the current working directory in order for you to work with it. You can find out what the current working directory is by importing `os` and using `os.getcwd()`, and you can change the current working directory using `os.chdir()`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Getting Sheets from the Workbook\n",
+ "\n",
+ "You can get a list of all the sheet names in the workbook by calling the `get_sheet_names()` method. Enter the following into a codeblock:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import openpyxl\n",
+ "\n",
+ "wb = openpyxl.load_workbook(\"example.xlsx\")\n",
+ "wb.get_sheet_names()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sheet = wb.get_sheet_by_name(\"Sheet3\")\n",
+ "print(sheet)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(type(sheet))\n",
+ "print(sheet.title)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "anotherSheet = wb.active\n",
+ "print(anotherSheet)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Each sheet is represented by a Worksheet object, which you can obtain by passing the sheet name string to the `get_sheet_by_name()` workbook method.\\\n",
+ "Finally, you can read the active member variable of a Workbook object to get the workbook’s active sheet. The active sheet is the sheet that’s on top when the workbook is opened in Excel. Once you have the Worksheet object, you can get its name from the title attribute."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Getting Cells from the Sheets\n",
+ "\n",
+ "Once you have a Worksheet object, you can access a Cell object by its name. Enter the following into the interactive shell:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import openpyxl\n",
+ "\n",
+ "wb = openpyxl.load_workbook(\"example.xlsx\")\n",
+ "sheet = wb.get_sheet_by_name(\"Sheet1\")\n",
+ "print(sheet[\"A1\"])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(sheet[\"A1\"].value)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "c = sheet[\"B1\"]\n",
+ "print(c.value)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(\"Row \" + str(c.row) + \", Column \" + c.column + \" is \" + c.value)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(\"Cell \" + c.coordinate + \" is \" + c.value)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(sheet[\"C1\"].value)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The Cell object has a value attribute that contains, unsurprisingly, the value stored in that cell. Cell objects also have row, column, and coordinate attributes that provide location information for the cell.\n",
+ "\n",
+ "Here, accessing the value attribute of our Cell object for cell *B1* gives us the string *'Apples'*. The row attribute gives us the integer *1*, the column attribute gives us *'B'*, and the coordinate attribute gives us *'B1'*.\n",
+ "\n",
+ "*OpenPyXL* will automatically interpret the dates in column *A* and return them as datetime values rather than strings.\n",
+ "\n",
+ "Specifying a column by letter can be tricky to program, especially because after column *Z*, the columns start by using two letters: *AA, AB, AC*, and so on. As an alternative, you can also get a cell using the sheet’s *cell()* method and passing integers for its row and column keyword arguments. The first row or column integer is *1*, not *0*. Continue the interactive shell example by entering the following:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sheet.cell(row=1, column=2)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sheet.cell(row=1, column=2).value"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for i in range(1, 8, 2):\n",
+ " print(i, sheet.cell(row=i, column=2).value)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "As you can see, using the sheet’s cell() method and passing it `row=1` and `column=2` gets you a Cell object for cell *B1*, just like specifying `sheet['B1']` did. Then, using the `cell()` method and its keyword arguments, you can write a `for` loop to print the values of a series of cells.\n",
+ "\n",
+ "Say you want to go down column *B* and print the value in every cell with an odd row number. By passing *2* for the `range()` function’s “step†parameter, you can get cells from every second row (in this case, all the odd-numbered rows). The for loop’s `i` variable is passed for the row keyword argument to the `cell()` method, while *2* is always passed for the column keyword argument. Note that the integer *2*, not the string *'B'*, is passed.\n",
+ "\n",
+ "You can determine the size of the sheet with the Worksheet object’s `max_row` and `max_column` member variables. Enter the following into the interactive shell:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import openpyxl\n",
+ "\n",
+ "wb = openpyxl.load_workbook(\"example.xlsx\")\n",
+ "sheet = wb.get_sheet_by_name(\"Sheet1\")\n",
+ "print(sheet.max_row)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Note that the *max_column* method returns an integer rather than the letter that appears in Excel."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "print(sheet.max_column)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Converting Between Column Letters and Numbers\n",
+ "\n",
+ "To convert from letters to numbers, call the `openpyxl.cell.column_index_from_string()` function. To convert from numbers to letters, call the `openpyxl.cell.get_column_letter()` function. Enter the following into the interactive shell:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import openpyxl\n",
+ "from openpyxl.utils import get_column_letter, column_index_from_string\n",
+ "\n",
+ "get_column_letter(1)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "get_column_letter(2)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "get_column_letter(27)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "get_column_letter(900)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "wb = openpyxl.load_workbook(\"example.xlsx\")\n",
+ "sheet = wb.get_sheet_by_name(\"Sheet1\")\n",
+ "get_column_letter(sheet.max_column)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "column_index_from_string(\"A\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "column_index_from_string(\"AA\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "After you import these two functions from the `openpyxl.utils` module, you can call `get_column_letter()` and pass it an integer like 27 to figure out what the letter name of the 27th column is. The function `column_index_string()` does the reverse: You pass it the letter name of a column, and it tells you what number that column is. You don’t need to have a workbook loaded to use these functions. If you want, you can load a workbook, get a Worksheet object, and call a Worksheet object method like `max_column` to get an integer. Then, you can pass that integer to `get_column_letter()`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Getting Rows and Columns from the Sheets\n",
+ "\n",
+ "You can slice Worksheet objects to get all the Cell objects in a row, column, or rectangular area of the spreadsheet. Then you can loop over all the cells in the slice. Enter the following into the interactive shell:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import openpyxl\n",
+ "\n",
+ "wb = openpyxl.load_workbook(\"example.xlsx\")\n",
+ "sheet = wb.get_sheet_by_name(\"Sheet1\")\n",
+ "tuple(sheet[\"A1\":\"C3\"])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# loop 1\n",
+ "for rowOfCellObjects in sheet[\"A1\":\"C3\"]:\n",
+ " # loop 2\n",
+ " for cellObj in rowOfCellObjects:\n",
+ " print(cellObj.coordinate, cellObj.value)\n",
+ " print(\"--- END OF ROW ---\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Here, we specify that we want the Cell objects in the rectangular area from *A1* to *C3*, and we get a Generator object containing the Cell objects in that area. To help us visualize this Generator object, we can use `tuple()` on it to display its Cell objects in a tuple.\n",
+ "\n",
+ "This tuple contains three tuples: one for each row, from the top of the desired area to the bottom. Each of these three inner tuples contains the Cell objects in one row of our desired area, from the leftmost cell to the right. So overall, our slice of the sheet contains all the Cell objects in the area from A1 to C3, starting from the top-left cell and ending with the bottom-right cell.\n",
+ "\n",
+ "To print the values of each cell in the area, we use two for loops. The outer for loop goes over each row in the slice (see #loop 1). Then, for each row, the nested for loop goes through each cell in that row (see #loop 2).\n",
+ "\n",
+ "To access the values of cells in a particular row or column, you can also use a Worksheet object’s rows and columns attribute. Enter the following into the interactive shell:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import openpyxl\n",
+ "\n",
+ "wb = openpyxl.load_workbook(\"example.xlsx\")\n",
+ "sheet = wb.active\n",
+ "print(list(sheet.columns)[1])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for cellObj in list(sheet.columns)[1]:\n",
+ " print(cellObj.value)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Using the rows attribute on a Worksheet object will give you a tuple of tuples. Each of these inner tuples represents a row, and contains the Cell objects in that row. The columns attribute also gives you a tuple of tuples, with each of the inner tuples containing the Cell objects in a particular column. For *example.xlsx*, since there are 7 rows and 3 columns, rows gives us a tuple of 7 tuples (each containing 3 Cell objects), and columns gives us a tuple of 3 tuples (each containing 7 Cell objects).\n",
+ "\n",
+ "To access one particular tuple, you can refer to it by its index in the larger tuple. For example, to get the tuple that represents column *B*, you use `sheet.columns[1]`. To get the tuple containing the Cell objects in column *A*, you’d use `sheet.columns[0]`. Once you have a tuple representing one row or column, you can loop through its Cell objects and print their values."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Workbooks, Sheets, Cells\n",
+ "\n",
+ "As a quick review, here’s a rundown of all the functions, methods, and data types involved in reading a cell out of a spreadsheet file:\n",
+ "\n",
+ "1. Import the`openpyxl` module.\n",
+ "\n",
+ "2. Call the `openpyxl.load_workbook()` function.\n",
+ "\n",
+ "3. Get a Workbook object.\n",
+ "\n",
+ "4. Read the active member variable or call the `get_sheet_by_name()` workbook method.\n",
+ "\n",
+ "5. Get a Worksheet object.\n",
+ "\n",
+ "6. Use indexing or the `cell()` sheet method with row and column keyword arguments.\n",
+ "\n",
+ "7. Get a Cell object.\n",
+ "\n",
+ "8. Read the Cell object’s value attribute.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Project: Reading Data from a Spreadsheet\n",
+ "\n",
+ "Say you have a spreadsheet of data from the 2010 US Census and you have the boring task of going through its thousands of rows to count both the total population and the number of census tracts for each county. (A census tract is simply a geographic area defined for the purposes of the census.) Each row represents a single census tract. We’ll name the spreadsheet file **censuspopdata.xlsx**, and you can download it from http://nostarch.com/automatestuff/."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Even though Excel can calculate the sum of multiple selected cells, you’d still have to select the cells for each of the 3,000-plus counties. Even if it takes just a few seconds to calculate a county’s population by hand, this would take hours to do for the whole spreadsheet.\n",
+ "\n",
+ "In this project, you’ll write a script that can read from the census spreadsheet file and calculate statistics for each county in a matter of seconds.\n",
+ "\n",
+ "This is what your program does:\n",
+ "\n",
+ "1. Reads the data from the Excel spreadsheet.\n",
+ "\n",
+ "2. Counts the number of census tracts in each county.\n",
+ "\n",
+ "3. Counts the total population of each county.\n",
+ "\n",
+ "4. Prints the results.\n",
+ "\n",
+ "This means your code will need to do the following:\n",
+ "\n",
+ "1. Open and read the cells of an Excel document with the `openpyxl` module.\n",
+ "\n",
+ "2. Calculate all the tract and population data and store it in a data structure.\n",
+ "\n",
+ "3. Write the data structure to a text file with the `.py` extension using the `pprint` module.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Step 1: Read the Spreadsheet Data\n",
+ "\n",
+ "There is just one sheet in the **censuspopdata.xlsx** spreadsheet, named 'Population by Census Tract', and each row holds the data for a single census tract. The columns are the tract number (A), the state abbreviation (B), the county name (C), and the population of the tract (D).\n",
+ "\n",
+ "Use the following code:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import openpyxl, pprint\n",
+ "\n",
+ "print(\"Opening workbook...\")\n",
+ "wb = openpyxl.load_workbook(\"censuspopdata.xlsx\")\n",
+ "sheet = wb.get_sheet_by_name(\"Population by Census Tract\")\n",
+ "countyData = {}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# TODO: Fill in countyData with each county's population and tracts.\n",
+ "print(\"Reading rows...\")\n",
+ "for row in range(2, sheet.max_row + 1):\n",
+ " # Each row in the spreadsheet has data for one census tract.\n",
+ " state = sheet[\"B\" + str(row)].value\n",
+ " county = sheet[\"C\" + str(row)].value\n",
+ " pop = sheet[\"D\" + str(row)].value\n",
+ "# TODO: Open a new text file and write the contents of countyData to it."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This code imports the openpyxl module, as well as the pprint module that you’ll use to print the final county data. Then it opens the **censuspopdata.xlsx** file, gets the sheet with the census data, and begins iterating over its rows.\n",
+ "\n",
+ "Note that you’ve also created a variable named `countyData`, which will contain the populations and number of tracts you calculate for each county. Before you can store anything in it, though, you should determine exactly how you’ll structure the data inside it."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Step 2: Populate the Data Structure"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The data structure stored in *countyData* will be a dictionary with state abbreviations as its keys. Each state abbreviation will map to another dictionary, whose keys are strings of the county names in that state. Each county name will in turn map to a dictionary with just two keys, 'tracts' and 'pop'. These keys map to the number of census tracts and population for the county. For example, the dictionary will look similar to this:\n",
+ "\n",
+ "`{'AK': {'Aleutians East': {'pop': 3141, 'tracts': 1},\n",
+ " 'Aleutians West': {'pop': 5561, 'tracts': 2},\n",
+ " 'Anchorage': {'pop': 291826, 'tracts': 55},\n",
+ " 'Bethel': {'pop': 17013, 'tracts': 3},\n",
+ " 'Bristol Bay': {'pop': 997, 'tracts': 1},\n",
+ " --snip--`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "If the previous dictionary were stored in *countyData*, the following expressions would evaluate like this:\n",
+ "\n",
+ "`countyData['AK']['Anchorage']['pop']`\n",
+ "\n",
+ "291826\n",
+ "\n",
+ "`countyData['AK']['Anchorage']['tracts']`\n",
+ "\n",
+ "55\n",
+ "\n",
+ "More generally, the *countyData* dictionary’s keys will look like this:\n",
+ "\n",
+ "`countyData[state abbrev][county]['tracts']`\n",
+ "\n",
+ "`countyData[state abbrev][county]['pop']`\n",
+ "\n",
+ "Now that you know how *countyData* will be structured, you can write the code that will fill it with the county data. Add the following code to the bottom of your program:\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "#! python 3\n",
+ "# readCensusExcel.py - Tabulates population and number of census tracts for\n",
+ "# each county.\n",
+ "# --snip--\n",
+ "for row in range(2, sheet.max_row + 1):\n",
+ " # Each row in the spreadsheet has data for one census tract.\n",
+ " state = sheet[\"B\" + str(row)].value\n",
+ " county = sheet[\"C\" + str(row)].value\n",
+ " pop = sheet[\"D\" + str(row)].value"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Make sure the key for this state exists.\n",
+ "1. `countyData.setdefault(state, {})`\n",
+ "\n",
+ "Make sure the key for this county in this state exists.\n",
+ "\n",
+ "2. `countyData[state].setdefault(county, {'tracts': 0, 'pop': 0})`\n",
+ "\n",
+ "Each row represents one census tract, so increment by one.\n",
+ "\n",
+ "3. `countyData[state][county]['tracts'] += 1`\n",
+ "\n",
+ "Increase the county pop by the pop in this census tract.\n",
+ "\n",
+ "4. `countyData[state][county]['pop'] += int(pop)`\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# TODO: Open a new text file and write the contents of countyData to it."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "\n",
+ "\n",
+ "The last two lines of code perform the actual calculation work, incrementing the value for tracts and increasing the value for pop for the current county on each iteration of the for loop.\n",
+ "\n",
+ "The other code is there because you cannot add a county dictionary as the value for a state abbreviation key until the key itself exists in countyData. (That is, `countyData['AK']['Anchorage']['tracts'] += 1` will cause an error if the 'AK' key doesn’t exist yet.) To make sure the state abbreviation key exists in your data structure, you need to call the `setdefault()` method to set a value if one does not already exist for state.\n",
+ "\n",
+ "Just as the *countyData* dictionary needs a dictionary as the value for each state abbreviation key, each of those dictionaries will need its own dictionary as the value for each county key. And each of those dictionaries in turn will need keys 'tracts' and 'pop' that start with the integer value 0. (If you ever lose track of the dictionary structure, look back at the example dictionary at the start of this section.)\n",
+ "\n",
+ "Since `setdefault()` will do nothing if the key already exists, you can call it on every iteration of the for loop without a problem."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "### Step 3: Write the Results to a File\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "After the for loop has finished, the countyData dictionary will contain all of the population and tract information keyed by county and state. At this point, you could program more code to write this to a text file or another Excel spreadsheet. For now, let’s just use the pprint.pformat() function to write the countyData dictionary value as a massive string to a file named census2010.py. Add the following code to the bottom of your program (making sure to keep it unindented so that it stays outside the for loop):"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "#! python 3\n",
+ "# readCensusExcel.py - Tabulates population and number of census tracts for\n",
+ "# each county.get_active_sheet\n",
+ "\n",
+ "for row in range(2, sheet.max_row + 1):\n",
+ " --snip--"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Open a new text file and write the contents of countyData to it.\n",
+ "print(\"Writing results...\")\n",
+ "resultFile = open(\"census2010.py\", \"w\")\n",
+ "resultFile.write(\"allData = \" + pprint.pformat(countyData))\n",
+ "resultFile.close()\n",
+ "print(\"Done.\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The `pprint.pformat()` function produces a string that itself is formatted as valid Python code. By outputting it to a text file named `census2010.py`, you’ve generated a Python program from your Python program! This may seem complicated, but the advantage is that you can now import `census2010.py` just like any other Python module. In the interactive shell, change the current working directory to the folder with your newly created `census2010.py` file (on my laptop, this is `C:\\Python34`), and then import it:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "\n",
+ "os.chdir(\"C:\\\\Python34\")\n",
+ "import census2010\n",
+ "\n",
+ "census2010.allData[\"AK\"][\"Anchorage\"]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "anchoragePop = census2010.allData[\"AK\"][\"Anchorage\"][\"pop\"]\n",
+ "print(\"The 2010 population of Anchorage was \" + str(anchoragePop))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The `readCensusExcel.py` program was throwaway code: Once you have its results saved to `census2010.py`, you won’t need to run the program again. Whenever you need the county data, you can just run \n",
+ "\n",
+ "`import census2010`.\n",
+ "\n",
+ "Calculating this data by hand would have taken hours; this program did it in a few seconds. Using *OpenPyXL*, you will have no trouble extracting information that is saved to an Excel spreadsheet and performing calculations on it. You can download the complete program from http://nostarch.com/automatestuff/."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Ideas for Similar Programs\n",
+ "\n",
+ "Many businesses and offices use Excel to store various types of data, and it’s not uncommon for spreadsheets to become large and unwieldy. Any program that parses an Excel spreadsheet has a similar structure: It loads the spreadsheet file, preps some variables or data structures, and then loops through each of the rows in the spreadsheet. Such a program could do the following:\n",
+ "\n",
+ "1. Compare data across multiple rows in a spreadsheet.\n",
+ "\n",
+ "2. Open multiple Excel files and compare data between spreadsheets.\n",
+ "\n",
+ "3. Check whether a spreadsheet has blank rows or invalid data in any cells and alert the user if it does.\n",
+ "\n",
+ "4. Read data from a spreadsheet and use it as the input for your Python programs.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Writing Excel Documents\n",
+ "\n",
+ "OpenPyXL also provides ways of writing data, meaning that your programs can create and edit spreadsheet files. With Python, it’s simple to create spreadsheets with thousands of rows of data."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Creating and Saving Excel Documents\n",
+ "\n",
+ "Call the `openpyxl.Workbook()` function to create a new, blank Workbook object. Enter the following into the interactive shell:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import openpyxl\n",
+ "\n",
+ "wb = openpyxl.Workbook()\n",
+ "wb.get_sheet_names()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sheet = wb.active\n",
+ "sheet.title"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sheet.title = \"Spam Bacon Eggs Sheet\"\n",
+ "wb.get_sheet_names()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The workbook will start off with a single sheet named Sheet. You can change the name of the sheet by storing a new string in its title attribute.\n",
+ "\n",
+ "Any time you modify the Workbook object or its sheets and cells, the spreadsheet file will not be saved until you call the `save()` workbook method. Enter the following into the interactive shell (with **example.xlsx** in the current working directory):"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import openpyxl\n",
+ "\n",
+ "wb = openpyxl.load_workbook(\"example.xlsx\")\n",
+ "sheet = wb.active\n",
+ "sheet.title = \"Spam Spam Spam\"\n",
+ "wb.save(\"example_copy.xlsx\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Here, we change the name of our sheet. To save our changes, we pass a filename as a string to the`save()` method. Passing a different filename than the original, such as **example_copy.xlsx**, saves the changes to a copy of the spreadsheet.\n",
+ "\n",
+ "Whenever you edit a spreadsheet you’ve loaded from a file, you should always save the new, edited spreadsheet to a different filename than the original. That way, you’ll still have the original spreadsheet file to work with in case a bug in your code caused the new, saved file to have incorrect or corrupt data."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Creating and Removing Sheets\n",
+ "\n",
+ "Sheets can be added to and removed from a workbook with the `create_sheet()` and `remove_sheet()` methods. Enter the following into the interactive shell:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import openpyxl\n",
+ "wb = openpyxl.Workbook()\n",
+ "wb.get_sheet_names()\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "wb.create_sheet()\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "wb.get_sheet_names()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "wb.create_sheet(index=0, title=\"First Sheet\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "wb.get_sheet_names()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "wb.create_sheet(index=2, title=\"Middle Sheet\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "wb.get_sheet_names()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The `create_sheet()` method returns a new Worksheet object named `SheetX`, which by default is set to be the last sheet in the workbook. Optionally, the index and name of the new sheet can be specified with the index and title keyword arguments.\n",
+ "\n",
+ "Continue the previous example by entering the following:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "wb.get_sheet_names()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "wb.remove_sheet(wb.get_sheet_by_name('Middle Sheet'))\n",
+ "wb.remove_sheet(wb.get_sheet_by_name('Sheet1'))\n",
+ "wb.get_sheet_names()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The `remove_sheet()` method takes a Worksheet object, not a string of the sheet name, as its argument. If you know only the name of a sheet you want to remove, call `get_sheet_by_name()` and pass its return value into `remove_sheet()`.\n",
+ "\n",
+ "Remember to call the `save()` method to save the changes after adding sheets to or removing sheets from the workbook.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Writing Values to Cells\n",
+ "\n",
+ "Writing values to cells is much like writing values to keys in a dictionary. Enter this into the interactive shell:\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import openpyxl\n",
+ "wb = openpyxl.Workbook()\n",
+ "Sheet = wb.get_sheet_by_name('Sheet')\n",
+ "sheet['A1'] = 'Hello world!'\n",
+ "sheet['A1'].value\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "If you have the cell’s coordinate as a string, you can use it just like a dictionary key on the Worksheet object to specify which cell to write to.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Project: Updating a Spreadsheet\n",
+ "\n",
+ "In this project, you’ll write a program to update cells in a spreadsheet of produce sales. Your program will look through the spreadsheet, find specific kinds of produce, and update their prices. Download this spreadsheet from http://nostarch.com/automatestuff/. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Each row represents an individual sale. The columns are the type of produce sold (A), the cost per pound of that produce (B), the number of pounds sold (C), and the total revenue from the sale (D). The `TOTAL` column is set to the Excel formula `=ROUND(B3*C3, 2)`, which multiplies the cost per pound by the number of pounds sold and rounds the result to the nearest cent. With this formula, the cells in the `TOTAL` column will automatically update themselves if there is a change in column B or C.\n",
+ "\n",
+ "Now imagine that the prices of garlic, celery, and lemons were entered incorrectly, leaving you with the boring task of going through thousands of rows in this spreadsheet to update the cost per pound for any garlic, celery, and lemon rows. You can’t do a simple find-and-replace for the price because there might be other items with the same price that you don’t want to mistakenly “correct.†For thousands of rows, this would take hours to do by hand. But you can write a program that can accomplish this in seconds."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Your program does the following:\n",
+ "\n",
+ "- Loops over all the rows.\n",
+ "\n",
+ "- If the row is for garlic, celery, or lemons, changes the price.\n",
+ "\n",
+ "This means your code will need to do the following:\n",
+ "\n",
+ "- Open the spreadsheet file.\n",
+ "\n",
+ "- For each row, check whether the value in column A is *Celery, Garlic, or Lemon*.\n",
+ "\n",
+ "- If it is, update the price in column B.\n",
+ "\n",
+ "- Save the spreadsheet to a new file (so that you don’t lose the old spreadsheet, just in case).\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Step 1: Set Up a Data Structure with the Update Information"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The prices that you need to update are as follows:\n",
+ "\n",
+ "`Celery 1.19`\n",
+ "\n",
+ "`Garlic 3.07`\n",
+ "\n",
+ "`Lemon 1.27`\n",
+ "\n",
+ "You could write code like this:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if produceName == 'Celery':\n",
+ " cellObj = 1.19\n",
+ "if produceName == 'Garlic':\n",
+ " cellObj = 3.07\n",
+ "if produceName == 'Lemon':\n",
+ " cellObj = 1.27"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Having the produce and updated price data hardcoded like this is a bit inelegant. If you needed to update the spreadsheet again with different prices or different produce, you would have to change a lot of the code. Every time you change code, you risk introducing bugs.\n",
+ "\n",
+ "A more flexible solution is to store the corrected price information in a dictionary and write your code to use this data structure. In a new file editor window, enter the following code:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "#! python3\n",
+ "# updateProduce.py - Corrects costs in produce sales spreadsheet.\n",
+ "\n",
+ "import openpyxl\n",
+ "\n",
+ "wb = openpyxl.load_workbook('produceSales.xlsx')\n",
+ "sheet = wb.get_sheet_by_name('Sheet')\n",
+ "\n",
+ "# The produce types and their updated prices\n",
+ "PRICE_UPDATES = {'Garlic': 3.07,\n",
+ " 'Celery': 1.19,\n",
+ " 'Lemon': 1.27}\n",
+ "\n",
+ "# TODO: Loop through the rows and update the prices."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Save this as updateProduce.py. If you need to update the spreadsheet again, you’ll need to update only the PRICE_UPDATES dictionary, not any other code."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Step 2: Check All Rows and Update Incorrect Prices\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The next part of the program will loop through all the rows in the spreadsheet. Add the following code to the bottom of `updateProduce.py`:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "#! python3\n",
+ "# updateProduce.py - Corrects costs in produce sales spreadsheet.\n",
+ "\n",
+ "--snip--"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ " # Loop through the rows and update the prices.\n",
+ "for rowNum in range(2, sheet.max_row): # skip the first row\n",
+ " produceName = sheet.cell(row=rowNum, column=1).value\n",
+ " if produceName in PRICE_UPDATES:\n",
+ " sheet.cell(row=rowNum, column=2).value = PRICE_UPDATES[produceName]\n",
+ " \n",
+ "wb.save('updatedProduceSales.xlsx')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We loop through the rows starting at row 2, since row 1 is just the header. The cell in column 1 (that is, column A) will be stored in the variable `produceName`. If produceName exists as a key in the `PRICE_UPDATES` dictionary, then you know this is a row that must have its price corrected. The correct price will be in `PRICE_UPDATES[produceName]`.\n",
+ "\n",
+ "Notice how clean using `PRICE_UPDATES` makes the code. Only one if statement, rather than code like `if produceName == 'Garlic':`, is necessary for every type of produce to update. And since the code uses the `PRICE_UPDATES` dictionary instead of hardcoding the produce names and updated costs into the for loop, you modify only the `PRICE_UPDATES` dictionary and not the code if the produce sales spreadsheet needs additional changes.\n",
+ "\n",
+ "After going through the entire spreadsheet and making changes, the code saves the Workbook object to `updatedProduceSales.xlsx`. It doesn’t overwrite the old spreadsheet just in case there’s a bug in your program and the updated spreadsheet is wrong. After checking that the updated spreadsheet looks right, you can delete the old spreadsheet.\n",
+ "\n",
+ "You can download the complete source code for this program from http://nostarch.com/automatestuff/."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Ideas for Similar Programs"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Since many office workers use Excel spreadsheets all the time, a program that can automatically edit and write Excel files could be really useful. Such a program could do the following:\n",
+ "\n",
+ "- Read data from one spreadsheet and write it to parts of other spreadsheets.\n",
+ "\n",
+ "- Read data from websites, text files, or the clipboard and write it to a spreadsheet.\n",
+ "\n",
+ "- Automatically “clean up†data in spreadsheets. For example, it could use regular expressions to read multiple formats of phone numbers and edit them to a single, standard format.\n",
+ "\n"
+ ]
+ }
+ ],
+ "metadata": {
+ "language_info": {
+ "name": "python",
+ "pygments_lexer": "ipython3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git "a/programmierspa\303\237/census2010.py" "b/programmierspa\303\237/census2010.py"
new file mode 100644
index 0000000000000000000000000000000000000000..431e0bb1531c294278733d75a5bf8287827b523e
--- /dev/null
+++ "b/programmierspa\303\237/census2010.py"
@@ -0,0 +1 @@
+allData = {}
\ No newline at end of file
diff --git "a/programmierspa\303\237/censuspopdata.xlsx" "b/programmierspa\303\237/censuspopdata.xlsx"
new file mode 100644
index 0000000000000000000000000000000000000000..835d3e911991204e228c01ea363a5a60d05b6626
Binary files /dev/null and "b/programmierspa\303\237/censuspopdata.xlsx" differ
diff --git "a/programmierspa\303\237/example.xlsx" "b/programmierspa\303\237/example.xlsx"
new file mode 100644
index 0000000000000000000000000000000000000000..7a7d8ed92b80193cd3a4242d4f15c74b54bd7d23
Binary files /dev/null and "b/programmierspa\303\237/example.xlsx" differ
diff --git "a/programmierspa\303\237/example_copy.xlsx" "b/programmierspa\303\237/example_copy.xlsx"
new file mode 100644
index 0000000000000000000000000000000000000000..8ca6c26525b41f5e04b512ea38eb929ddca22594
Binary files /dev/null and "b/programmierspa\303\237/example_copy.xlsx" differ
diff --git "a/programmierspa\303\237/intro.org" "b/programmierspa\303\237/intro.org"
new file mode 100644
index 0000000000000000000000000000000000000000..27d16d871c1c11253b9207bf1059d8338a22b961
--- /dev/null
+++ "b/programmierspa\303\237/intro.org"
@@ -0,0 +1,21 @@
+Herzlich Willkommen
+
+- python Kenntnisse
+- Datum finden -> doodle Liste?
+- aktuellen moodle Kurs nehmen
+- Themen finden:
+ - web scraping
+ - arbeit mit excel sheets
+ - arbeit mit word und pdfs
+ - emails senden
+ - bilder manipulieren
+ - website?
+ - bibliotheken vorstellen
+ - matplotlib
+ - pandas
+ - numpy
+ - sklearn
+ - datenanalyse
+
+
+11. - 14. November
diff --git "a/programmierspa\303\237/intro.org~" "b/programmierspa\303\237/intro.org~"
new file mode 100644
index 0000000000000000000000000000000000000000..1646f14c2f7a9bd3de9adf0206ed96459ed51c3a
--- /dev/null
+++ "b/programmierspa\303\237/intro.org~"
@@ -0,0 +1,18 @@
+Herzlich Willkommen
+
+- python Kenntnisse
+- Datum finden -> doodle Liste?
+- aktuellen moodle Kurs nehmen
+- Themen finden:
+ - web scraping
+ - arbeit mit excel sheets
+ - arbeit mit word und pdfs
+ - emails senden
+ - bilder manipulieren
+ - website?
+ - bibliotheken vorstellen
+ - matplotlib
+ - pandas
+ - numpy
+ - sklearn
+ - datenanalyse
diff --git "a/programmierspa\303\237/readCensusExcel.py" "b/programmierspa\303\237/readCensusExcel.py"
new file mode 100644
index 0000000000000000000000000000000000000000..ab0096aca045bd90ec5f000ee9727296782311c6
--- /dev/null
+++ "b/programmierspa\303\237/readCensusExcel.py"
@@ -0,0 +1,33 @@
+#! python3
+# readCensusExcel.py - Tabulates population and number of census tracts for
+# each county.
+
+import openpyxl, pprint
+print('Opening workbook...')
+wb = openpyxl.load_workbook('censuspopdata.xlsx')
+sheet = wb.get_sheet_by_name('Population by Census Tract')
+countyData = {}
+# Fill in countyData with each county's population and tracts.
+print('Reading rows...')
+for row in range(2, sheet.max_row + 1):
+ # Each row in the spreadsheet has data for one census tract.
+ state = sheet['B' + str(row)].value
+ county = sheet['C' + str(row)].value
+ pop = sheet['D' + str(row)].value
+
+ # Make sure the key for this state exists.
+ countyData.setdefault(state, {})
+ # Make sure the key for this county in this state exists.
+ countyData[state].setdefault(county, {'tracts': 0, 'pop': 0})
+
+ # Each row represents one census tract, so increment by one.
+ countyData[state][county]['tracts'] += 1
+ # Increase the county pop by the pop in this census tract.
+ countyData[state][county]['pop'] += int(pop)
+
+# Open a new text file and write the contents of countyData to it.
+print('Writing results...')
+resultFile = open('census2010.py', 'w')
+resultFile.write('allData = ' + pprint.pformat(countyData))
+resultFile.close()
+print('Done.')